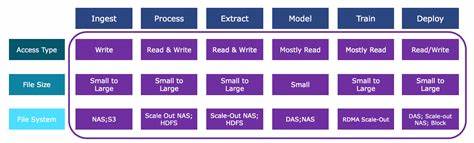
El aprendizaje automático ha revolucionado la forma en que las organizaciones procesan y analizan grandes volúmenes de datos para obtener insights valiosos y tomar decisiones informadas. Sin embargo, para que los modelos de aprendizaje automático funcionen eficientemente, es fundamental entender los patrones de acceso a datos a lo largo de todo el pipeline de desarrollo, desde la ingestión hasta el despliegue. Esta comprensión permite optimizar la infraestructura de datos, garantizar un flujo adecuado de información y maximizar el rendimiento computacional, especialmente en entornos que manejan petabytes de información. En la etapa inicial conocida como ingestión, los datos entran en el sistema y varían ampliamente según la fuente y el sector de aplicación. Por ejemplo, sensores IoT en una fábrica pueden generar datos muy pequeños pero muy frecuentes, generalmente con características de series temporales tomadas a frecuencias sub-segundo.
En contraste, los satélites pueden enviar imágenes comprimidas que alcanzan terabytes una vez al día. En el contexto de vehículos autónomos, la ingestión combina datos de sensores en tiempo real con archivos de video e imagen de alta definición, lo que exige capacidades considerables para manejar tanto volumen como velocidad. A nivel de acceso, esta fase es predominantemente de escritura, ya que se registra y almacena la información cruda, siendo la cantidad de operaciones de entrada/salida por segundo (IOPS) un factor crítico para evitar cuellos de botella. Una vez que los datos están almacenados, la fase de procesamiento toma protagonismo en la que la información es limpiada, anotada y correlacionada para preparar características útiles para etapas posteriores. Es aquí donde la relación entre lectura y escritura tiende a equilibrarse, evidenciando la necesidad de sistemas con alto rendimiento y capacidad.
Procesar y escribir datos masivos simultáneamente requiere infraestructura robusta como sistemas de archivos paralelos ejecutándose en unidades de almacenamiento rápidas, típicamente basadas en servidores con almacenamiento NVMe de estado sólido y redes de alta velocidad como 100 Gigabit Ethernet. Esta configuración reduce considerablemente el tiempo de procesamiento, permitiendo a los científicos de datos trabajar de manera más eficiente y acelerar el desarrollo de nuevas soluciones. La extracción de características representa una etapa iterativa dentro del pipeline, en la que se necesita leer constantemente grandes volúmenes de datos procesados para generar conjuntos más pequeños de características que luego alimentarán los algoritmos de modelado. Aquí, los datos suelen ser leídos y escritos repetidamente conforme los científicos validan hipótesis y ajustan sus enfoques. En proyectos avanzados a escala hiperescalada, este proceso puede realizarse dentro de la misma infraestructura, pero también involucra el traslado de conjuntos de datos más compactos hacia plataformas GPU para acelerar el entrenamiento de modelos.
Los patrones de acceso en esta fase reflejan una alta actividad tanto en lectura como en escritura, exigiendo flexibilidad y eficiencia en la gestión del almacenamiento. Durante la fase de modelado, los científicos utilizan subconjuntos pequeños de datos extraídos para probar hipótesis específicas. Ajustan y experimentan con distintos parámetros y conjuntos para mejorar la precisión del modelo. Debido a que trabaja con conjuntos limitados y definidos, esta etapa presenta predominantemente un patrón de acceso de lectura con mínimas escrituras, generalmente asociadas a la salida de modelos iniciales. Estos conjuntos más pequeños permiten ciclos rápidos de prototipado sin la necesidad de manejar toda la base de datos, lo que optimiza recursos y tiempos.
El entrenamiento es la fase en la cual los modelos se entrenan utilizando grandes volúmenes de datos para lograr una mayor precisión. Esta etapa exige una infraestructura computacional intensiva que generalmente se apoya en clusters de servidores GPU con elevados anchos de banda en redes para evitar cuellos de botella en la alimentación de datos. El almacenamiento debe proporcionar un acceso rápido y constante para garantizar que las GPUs trabajen a plena capacidad, maximizando el retorno de inversión en hardware especializado. La selección de sistemas de almacenamiento rápido, como arquitecturas de almacenamiento flash all-flash NVMe optimizadas, es clave para cumplir con las demandas de alta latencia y throughput en esta etapa. Finalmente, la etapa de despliegue se centra en usar los modelos entrenados para realizar inferencias sobre nuevos datos que llegan al sistema.
En este punto, el volumen de datos procesado es mucho menor que el utilizado para el entrenamiento, ya que el modelo genera respuestas específicas, como clasificaciones, etiquetas o recomendaciones. Los patrones de acceso pueden variar en función del tipo de modelo desplegado, siendo comunes relaciones de lectura versus escritura desbalanceadas, por ejemplo una a muchas. En algunos casos, como en modelos generativos que crean contenido nuevo basado en datos previos, se observan operaciones mixtas, aumentando la complejidad del manejo y la optimización del almacenamiento. Al diseñar infraestructuras para aprendizaje automático, es esencial diferenciar las necesidades entre big data y fast data. Las fases críticas como ingestión, procesamiento, entrenamiento y despliegue requieren acceso rápido a los datos para mantener el rendimiento, por lo que es recomendable aprovechar soluciones basadas en dispositivos flash de última generación, incluyendo NVMe y sistemas all-flash que minimizan la latencia y maximizan el flujo de datos.
Por otro lado, big data juega un rol esencial como repositorio de archivo o almacenamiento digital para grandes cantidades de información histórica. Para estos fines, se considera adecuado utilizar discos duros de alta capacidad, configuraciones híbridas o almacenamiento en la nube, donde el costo y la escala tienen prioridad sobre la velocidad extrema. La correcta comprensión e implementación de los patrones de acceso en cada etapa del pipeline de aprendizaje automático no solo optimiza el rendimiento de los modelos, sino que también influye en la eficiencia operativa y en la reducción de costos asociada a infraestructura. Organizaciones que invierten en arquitecturas adaptadas a sus patrones específicos de datos aseguran una mayor agilidad y capacidad para escalar proyectos de inteligencia artificial y machine learning, alcanzando resultados más precisos y rápidos. A medida que la inteligencia artificial continúa avanzando y expandiéndose en diversas industrias, la gestión inteligente de datos se convierte en un pilar fundamental para el éxito.
La combinación de análisis exhaustivo de patrones de acceso, hardware de almacenamiento optimizado y redes de alta capacidad asegura que el proceso de aprendizaje automático pueda desarrollarse sin interrupciones y con la máxima eficiencia. Incorporar estas buenas prácticas permite a las empresas mantenerse competitivas y aprovechar al máximo el potencial transformador de la inteligencia artificial.