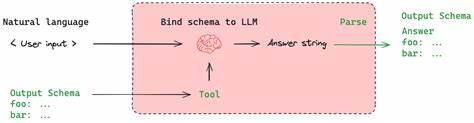
En la era digital actual, la capacidad para extraer información precisa y estructurada de grandes volúmenes de textos se ha convertido en una necesidad fundamental para diversas industrias. Los modelos de lenguaje grandes (LLMs) han revolucionado el procesamiento del lenguaje natural, pero para aprovechar su verdadero potencial es vital contar con herramientas que permitan obtener salidas organizadas, coherentes y validadas. Aquí es donde entran en juego soluciones como Instructor y Pydantic, dos tecnologías que facilitan la extracción de datos estructurados mediante ejemplos prácticos y validaciones robustas. Instructor es una biblioteca de código abierto diseñada para trabajar en conjunto con LLMs, ayudando a los desarrolladores a definir cómo deben ser las respuestas generadas por el modelo para que se ajusten a formatos específicos y útiles para aplicaciones reales. Usando Instructor, es posible especificar claramente el esquema o modelo de la respuesta deseada, asegurando que los datos extraídos tengan una estructura predecible y fácil de procesar posteriormente.
Pydantic, por otro lado, es una biblioteca en Python que permite la validación y gestión de datos mediante modelos de clases. Cuando se integra con Instructor en el ecosistema de extracción de información, Pydantic añade una capa esencial de seguridad y precisión, garantizando que los datos recibidos del modelo cumplan con ciertas reglas y tipos definidos, lo que reduce errores y mejora la consistencia. La combinación de estas herramientas requiere un entorno de desarrollo actualizado, por lo que se recomienda tener instalada una versión de Python igual o superior a la 3.9, junto con las últimas versiones de Instructor y Pydantic. Esto garantiza compatibilidad y acceso a las funcionalidades más recientes que ofrecen estas bibliotecas.
Para comenzar con la extracción de datos estructurados, es fundamental familiarizarse con los conceptos básicos y la configuración inicial. Instructor facilita la creación de respuestas con estructuras definidas a través de ejemplos, permitiendo que incluso usuarios con conocimientos limitados puedan orientar al modelo para que produzca salidas organizadas. El primer paso consiste en instalar Instructor y configurar un cliente que interactúe con el proveedor de LLM elegido, ya sea OpenAI, Anthropic, Gemini, Cohere, Mistral u otros. Uno de los aspectos más destacados al usar Instructor es la flexibilidad para adaptarse a diferentes proveedores de tecnología, lo cual es crucial dada la diversidad del mercado actual. Cada proveedor puede ofrecer capacidades y limitaciones distintas, pero Instructor permite abstraer estas diferencias y trabajar con un formato común, aumentando la escalabilidad y facilidad de integración en distintos proyectos.
Los patrones básicos para la extracción estructurada incluyen desde la obtención de un solo objeto simple hasta listas y estructuras anidadas más complejas. Con Instructor, se pueden definir modelos para validar campos únicos, campos opcionales y establecer plantillas que orienten al modelo durante la generación de texto, asegurando que se mantenga la coherencia en la presentación de los datos. Además, con la creciente demanda de manejar entradas multimodales, Instructor y Pydantic tienen capacidades para trabajar con imágenes, audio y documentos de texto en formatos como PDF. La extracción de tablas, reconocimiento de elementos visuales y análisis de audio son ejemplos de cómo estas herramientas están ampliando su rango de aplicación más allá del texto plano. En tareas de clasificación y análisis, los datos estructurados permiten a los sistemas automatizados entender mejor el contexto y tomar decisiones informadas.
Se pueden realizar clasificaciones simples o multi-etiqueta, así como gestionar respuestas que se transmiten en tiempo real mediante técnicas de streaming. Esto es especialmente útil en entornos dinámicos donde la velocidad y precisión de la información son críticas. Al abordar estructuras avanzadas, Instructor facilita la construcción de modelos recursivos como árboles de dependencias, grafos de conocimiento y planes de tareas complejos. Estas funcionalidades representan una ventaja competitiva para proyectos que requieren manejar jerarquías o relaciones complejas entre datos. La validación es una pieza clave para asegurar la calidad de los datos extraídos.
Pydantic ofrece diversas estrategias, desde validadores personalizados hasta mecanismos para reintentar solicitudes en caso de respuestas incorrectas o incompletas. También es posible implementar validaciones a nivel de campo, lo que contribuye a minimizar errores y mejorar la confiabilidad de los sistemas. Para ambientes productivos, la optimización del rendimiento resulta vital. Instructor permite implementar cachés de respuestas, realizar extracciones en paralelo y procesar lotes de datos para ahorrar tiempo y recursos. Además, la inclusión de hooks y callbacks facilita la integración con otros sistemas y la personalización de los flujos de procesamiento.