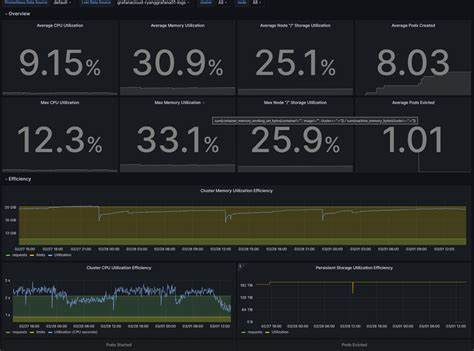
El monitoreo eficaz de los recursos en entornos de Kubernetes ha sido un desafío creciente a medida que las arquitecturas de infraestructura evolucionan hacia modelos cada vez más dinámicos y elásticos. Tradicionalmente, en entornos basados en máquinas virtuales, la observación y gestión de la utilización de CPU y memoria contra la capacidad asignada era una práctica habitual y confiable para detectar la falta de recursos o la contención. Sin embargo, Kubernetes ha cambiado fundamentalmente estas reglas. Su capacidad para compartir dinámicamente los recursos y la introducción de conceptos como las solicitudes y límites de recursos han hecho que las métricas clásicas pierdan su propósito y claridad original. Esta transformación requiere un replanteamiento completo de cómo se supervisan los cuellos de botella y la competencia por recursos en los contenedores.
En los sistemas de máquinas virtuales, monitorear si la CPU o la memoria llegaban cerca del 100% de su límite era un claro indicador de que el sistema estaba estresado o esperando más capacidad. Esta lógica es sencilla: si algo está utilizando todos los recursos fijos que se le asignaron, seguramente está experimentando falta de recursos. Sin embargo, Kubernetes funciona con un modelo un poco diferente. Las solicitudes de recursos se utilizan para asignar y garantizar una cierta cantidad mínima, pero los contenedores pueden superar esa asignación si hay capacidad disponible en el nodo. Además, el uso puede estar por debajo de la solicitud pero el sistema aún presenta signos de contención real cuando la demanda del clúster es alta.
Por eso, comparar el uso actual con la solicitud declarada puede inducir a error. Es común que ingenieros de infraestructura y equipos de operaciones intenten aplicar la misma lógica de la era de las máquinas virtuales, midiendo el porcentaje de utilización frente a las solicitudes asignadas. No obstante, esta comparación puede generar falsos positivos y negativos. Un contenedor que utiliza más CPU que su solicitud no necesariamente está en problemas; puede estar aprovechando recursos inactivos sin perjudicar a otros. Por el contrario, un contenedor que utiliza menos CPU que su solicitud podría estar sufriendo competencia detrás de escena que no se reflejan en los simples valores de uso.
En definitiva, los números de uso vs. solicitud no cuentan toda la historia. Para mejorar esta situación, algunos equipos comenzaron a supervisar el uso frente a los límites de recursos establecidos. En Kubernetes, los límites son restricciones duras: el sistema no permite que un contenedor supere su límite marcado para CPU y memoria. Supervisar el uso frente a estos límites tiene más sentido, ya que acercarse excesivamente al límite de memoria puede resultar en un error fatal de terminación del contenedor (OOM kill), mientras que acercarse al límite de CPU indica que el contenedor está siendo restringido por el sistema operativo mediante cinemáticas de throttling o estrangulamiento.
Sin embargo, el uso de límites de CPU no es una práctica universalmente recomendable. De hecho, existe un debate importante en la comunidad sobre si establecer límites de CPU en la mayoría de las aplicaciones puede perjudicar el rendimiento. Kubernetes y el sistema Linux cuentan con un planificador de CPU llamado Completely Fair Scheduler (CFS), que reparte el tiempo de CPU de forma justa en función del peso asignado, el cual se calcula a partir de las solicitudes de CPU. Esto permite que sin establecer límites duros, los contenedores puedan compartir el CPU equitativamente y aprovechar los recursos sobrantes cuando estén disponibles. Limitar el CPU puede impedir que una aplicación consuma recursos libres cuando los necesite, generando ineficiencias y problemas de latencia.
Dada esta complejidad y la falta de indicadores claros sobre cuándo una aplicación está realmente enfrentando competencia o falta de recursos, surge la necesidad de nuevas métricas que reflejen más fielmente la experiencia real de los procesos. Afortunadamente, el kernel de Linux introdujo una solución innovadora llamada Pressure Stall Information (PSI), que captura la cantidad de tiempo que los procesos están bloqueados o esperando por recursos como CPU, memoria o disco. PSI funciona midiendo el tiempo en que los hilos o tareas de un contenedor están listos para ejecutarse pero no pueden hacerlo debido a la falta de disponibilidad del recurso. Esto es un cambio radical en la forma de medir la presión en el sistema, pues deja de lado la simple observación del uso para mostrar el impacto directo que la competencia por los recursos tiene en el rendimiento real. Mediante PSI, es posible detectar si un contenedor pasa una parte significativa del tiempo esperando que el CPU esté libre, lo que indica que está sufriendo una contención real y no solo una fluctuación en su utilización.
Esta funcionalidad, integrada con cAdvisor y accesible desde Kubernetes a través del API de métricas, permite establecer alertas y paneles de monitoreo mucho más precisos. La ventaja principal es evitar falsas alarmas ante altos consumos que no perjudican el rendimiento y, por otro lado, detectar problemas de competencia incluso cuando los valores de utilización son bajos, pero la aplicación está experimentando demoras. Además de CPU, PSI también mide la presión en memoria y entrada/salida, permitiendo detectar problemas antes de llegar a fallos críticos como los OOM kills o cuellos de botella en el acceso a discos. Estas alertas tempranas son vitales para mantener la estabilidad y la experiencia de usuario en aplicaciones críticas. Para implementar PSI en un clúster Kubernetes es necesario contar con un kernel Linux 4.
20 o superior que soporte cgroup v2, habilitar la función en la configuración del kubelet y configurar las herramientas de monitoreo para recolectar y procesar esas métricas, normalmente con Prometheus u otros sistemas compatibles. Con las consultas adecuadas, los equipos pueden observar el porcentaje de tiempo que un contenedor ha estado esperando CPU o memoria, lo que ofrece una visión contextual y práctica para ajustar solicitudes, escalar servicios o identificar nodos saturados. En resumen, la evolución de la infraestructura hacia modelos desagregados y dinámicos demanda un cambio en el enfoque del monitoreo. El uso tradicional basado en métricas de utilización ya no es suficiente ni siempre relevante en Kubernetes. La incorporación de PSI como métrica clave entrega una perspectiva realista sobre la competencia y la falta de recursos, permitiendo tomar decisiones más informadas para mejorar la eficiencia, reducir alertas falsas y optimizar los recursos disponibles.