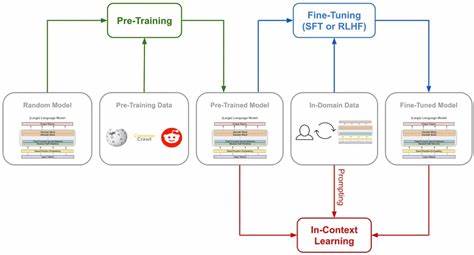
En el panorama actual de la inteligencia artificial, la capacidad de entrenar modelos de lenguaje de manera efectiva y precisa se ha convertido en un factor decisivo para alcanzar resultados satisfactorios en diversas aplicaciones. Qwen3, una arquitectura avanzada de modelo de lenguaje, junto con la metodología de afinamiento supervisado mediante TRL (Transformer Reinforcement Learning), está avanzando hacia un nivel superior en la optimización y especialización de modelos de lenguaje que responden mejor a las necesidades específicas de cada proyecto. Qwen3 representa una evolución significativa en la construcción de modelos de lenguaje. Está diseñado para manejar una gran cantidad de datos y procesar información con una eficiencia y velocidad avanzadas, lo que permite obtener resultados superiores en comprensión y generación de texto. Sin embargo, la verdadera potencia de Qwen3 se despliega cuando se combina con técnicas especializadas de entrenamiento, como el afinamiento supervisado mediante TRL.
El afinamiento supervisado es una estrategia que consiste en continuar la formación del modelo preentrenado con un conjunto específico de datos etiquetados, optimizando su capacidad para tareas concretas. Este tipo de entrenamiento permite que el modelo no solo entienda el lenguaje de forma general, sino que también se adapte a contextos, estilos y objetivos puntuales, mejorando su exactitud y relevancia. TRL, o Transformer Reinforcement Learning, se utiliza para refinar aún más el proceso de entrenamiento mediante la incorporación de técnicas de aprendizaje por refuerzo. Esto implica que, además del feedback habitual proporcionado durante el entrenamiento supervisado, el modelo recibe recompensas o penalizaciones que guían su evolución hacia comportamientos deseados. En esencia, TRL convierte el entrenamiento en un proceso dinámico y adaptativo, donde el modelo aprende a ajustar sus respuestas conforme a criterios específicos definidos por los investigadores o desarrolladores.
La sincronización de Qwen3 con el afinamiento supervisado utilizando TRL da lugar a modelos que no solo tienen sólido conocimiento base sino que también exhiben una alta capacidad de personalización. Esto es crucial en sectores como el comercio electrónico, atención al cliente, generación de contenido, traducción automática y análisis de sentimientos, donde la calidad del lenguaje generado y la precisión en la interpretación de las métricas específicas pueden marcar la diferencia en la experiencia del usuario y la efectividad operacional. Un aspecto destacado del proceso es la manera en que TRL ayuda a sortear algunas limitaciones del aprendizaje supervisado tradicional, principalmente la rigidez ante nuevas situaciones no contempladas en el conjunto de datos etiquetados. El componente de refuerzo facilita que el modelo explore distintas vías de respuesta y se adapte continuamente a medida que recibe retroalimentación directa sobre su desempeño en tareas reales o simuladas. Además, el uso de TRL en el afinamiento supervisado contribuye a mitigar problemas comunes como el sobreajuste, donde el modelo aprende de memoria los datos de entrenamiento sin generalizar adecuadamente.
Mediante objetivos de recompensa bien diseñados, el entrenamiento fomenta la creatividad y la flexibilidad en las respuestas del modelo, alcanzando un equilibrio entre precisión y diversidad lingüística. El proceso para implementar afinamiento supervisado con TRL en Qwen3 comienza con la selección cuidadosa de datasets de alta calidad, relevantes y bien etiquetados, que reflejen las características del dominio específico en que se pretende utilizar el modelo. Posteriormente, se ejecutan ciclos iterativos donde el modelo es entrenado, evaluado y ajustado según los criterios definidos para recompensa, consolidando una evolución que maximiza su rendimiento en condiciones particulares. Una ventaja notable de esta metodología es la reducción en los tiempos de entrenamiento y el uso más eficiente de los recursos computacionales. La incorporación de señales de refuerzo orientadas a objetivos concretos evita la necesidad de repetir extensas calibraciones, facilitando la convergencia del modelo hacia soluciones óptimas de manera más rápida.