En el vertiginoso mundo del aprendizaje automático y la inteligencia artificial, el entrenamiento de grandes modelos de lenguaje ha sido durante mucho tiempo un proceso exclusivo para centros de datos que cuentan con costosos recursos computacionales. Sin embargo, TScale surge como una solución innovadora que permite realizar entrenamiento distribuido en GPUs de consumo, haciendo accesible esta tecnología avanzada a un público mucho más amplio. Esta plataforma aprovecha arquitecturas optimizadas, precisión reducida y técnicas de entrenamiento distribuido para ofrecer resultados competitivos sin la necesidad de hardware especializado o extremadamente caro. TScale es un repositorio de código abierto que combina C++ y CUDA para ofrecer implementaciones eficientes de entrenamiento e inferencia de transformadores. Diseñado explícitamente para funcionar en GPUs de consumo de Nvidia, como la serie RTX 4090, este proyecto ha apostado por reducir los costos y la barrera tecnológica que históricamente han limitado la creación y el desarrollo de grandes modelos de lenguaje.
La clave de su éxito radica en optimizaciones profundas de la arquitectura del transformador, el uso de precisiones de datos más bajas, la gestión inteligente de memoria y la capacidad para distribuir el entrenamiento tanto sincronizadamente entre hosts con configuraciones similares, como de forma asíncrona en entornos heterogéneos. Una de las grandes innovaciones que aporta TScale es la reducción aproximada de costos de atención en el modelo, logrando acelerar la convergencia del entrenamiento mientras disminuye a la mitad los recursos computacionales consumidos para esta operación crucial dentro del mecanismo de atención de transformadores. Esta mejora permite entrenar modelos más grandes o acelerar el proceso sin incrementar el gasto energético ni la memoria requerida. El soporte para precisión fp8 e int8 en pesos y activaciones es otro factor que optimiza el rendimiento. Al utilizar formatos de datos más bajos, el entrenamiento y la inferencia consumen menos memoria y procesan los cálculos con mayor rapidez, manteniendo al mismo tiempo una calidad prácticamente intacta del modelado.
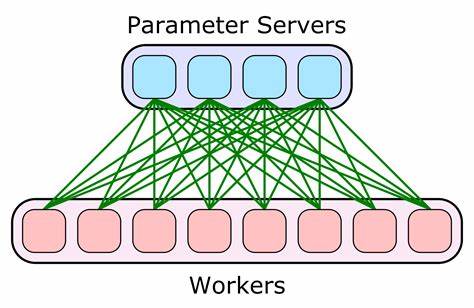
Este enfoque abre paso a usar GPUs convencionales, ya que reduce los requisitos de memoria que podrían hacer inviables entrenar modelos de gran escala en un hardware limitado. El mecanismo de descarga de cargas de CPU para aliviar la memoria de la GPU complementa esta estrategia, permitiendo que más datos y parámetros puedan procesarse simultáneamente. De este modo, TScale maximiza el potencial de hardware común, evitando cuellos de botella derivados de una memoria GPU saturada. En el ámbito de la distribución de entrenamiento, TScale ofrece dos modos innovadores. El primero es un entrenamiento distribuido síncrono, ideal para grupos de hosts con configuraciones homogéneas, donde los nodos sincronizan sus actualizaciones y realizan la tarea cooperativamente.
Si bien esta modalidad requiere una cantidad de hosts en potencias de dos para asegurar eficiencia, permite acelerar el proceso al aprovechar recursos sumados sin sacrificar precisión. Por otro lado, la modalidad asíncrona permite distribuir la carga de trabajo en máquinas geográficamente dispersas, conectadas incluso mediante enlaces Ethernet convencionales. Esta modalidad usa una compresión de gradientes de solo un bit, reduciendo el ancho de banda necesario para comunicarse y permitiendo un entrenamiento efectivo sin la necesidad de redes de alta velocidad o infraestructura especializada. Gracias a esta flexibilidad, usuarios con recursos repartidos o en diferentes ubicaciones pueden colaborar en el entrenamiento del mismo modelo sin grandes complicaciones. Un caso destacado logrado con TScale es el entrenamiento de un modelo de 1.
5 mil millones de parámetros en GPUs de consumo, específicamente con varias RTX 4090 en instancias de bajo costo. Durante un período de dos días y con un gasto aproximado de 500 dólares, se lograron métricas de log loss competitivas sobre un corpus de datos educativos, señalando la viabilidad económica y técnica de esta aproximación. Más impresionante aún resulta la concepción de modelos con índices de hasta un billón (1T) de entradas empleando TScale. Aunque el tamaño del modelo pueda parecer inalcanzable para la mayoría, TScale apuesta por una estructura donde un índice inmenso se consulta para cada token durante la predicción, pero el modelo base que procesa esta información es mucho más pequeño en comparación. Este diseño innovador no solo logra una significativa reducción de la perplejidad del modelo (indicando una mejor capacidad predictiva), sino que además es práctico y asequible, incluso para entornos domésticos o sin acceso a infraestructura computacional de alto nivel.
En términos técnicos de construcción y despliegue, TScale requiere CUDA v12.3 y compiladores C++ específicos para cada plataforma, incluyendo MSVC en Windows y combinación de CMake con Clang en Linux. La generación de archivos de construcción emplea "fo," una solución ligera desarrollada dentro del mismo proyecto, facilitando la configuración multiplataforma. Para la obtención de datos de entrenamiento, TScale incluye soporte para datasets reconocidos como enwik8 y enwik9, además de integración con datasets disponibles en Hugging Face, facilitando que el usuario pueda empezar a experimentar sin necesidad de buscar o procesar enormes volúmenes de datos por su cuenta. La ejecución del entrenamiento puede iniciarse con herramientas como gpt_train, controlada por scripts de entrenamiento y datos parametrizables para ajustarse a diferentes escenarios y modelos.
Además, el soporte para múltiples GPUs por nodo permite maximizar el uso de recursos locales cuando estén disponibles. Para realizar inferencia, TScale incluye gpt_infer, que permite levantar un servidor HTTP básico para probar las capacidades del modelo entrenado, facilitando la evaluación práctica y demostración sin necesidad de procesos complejos adicionales. Finalmente, el proyecto está licenciado bajo MIT, lo que garantiza que la comunidad pueda adaptarlo, mejorarlo y expandir su uso con libertad, contribuyendo a la democratización del desarrollo de inteligencia artificial avanzada. En resumen, TScale representa un cambio de paradigma en el entrenamiento de modelos de lenguaje grande, acercando tecnologías que antes estaban confinadas a grandes corporativos o centros de datos especializados al usuario promedio. Gracias a sus innovaciones en optimización, precisión y distribución, entornos domésticos o con hardware accesible pueden ahora considerar realizar proyectos que anteriormente parecían imposibles o prohibitivos desde el punto de vista técnico y económico.
El potencial que abre este tipo de plataformas es vasto: desde la academia, donde investigadores pueden experimentar sin grandes inversiones, hasta startups y desarrolladores independientes que buscan crear soluciones personalizadas sin depender de la infraestructura en la nube costosa. El futuro del entrenamiento de modelos IA parece cada vez más descentralizado y accesible gracias a propuestas como TScale.