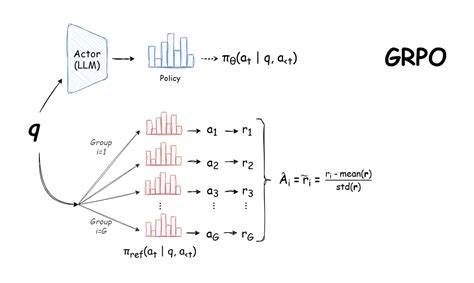
En la era actual, donde la inteligencia artificial avanza rápidamente, entrenar modelos de lenguaje para que comprendan y resuelvan problemas complejos se ha vuelto una prioridad para investigadores y desarrolladores. Uno de los retos interesantes y prácticos es la optimización de la programación de eventos, tomando en cuenta diversas restricciones y prioridades. Recientemente, se ha explorado el uso de GRPO, una técnica de aprendizaje por refuerzo que permite entrenar modelos sin necesidad de datos con respuestas completas, sino con señales de recompensa basadas en el desempeño. Este enfoque ofrece una nueva perspectiva para mejorar la capacidad de los modelos de lenguaje en tareas estructuradas como la creación de horarios eficientes. El reto propuesto consiste en que un modelo de lenguaje pueda recibir una lista de eventos, cada uno con un horario de inicio y fin, y un conjunto de prioridades para ciertos eventos.
La meta es generar una programación que maximice la duración total ponderada de los eventos seleccionados, dándole mayor importancia a los eventos considerados prioritarios. En este contexto, se asigna un peso de 2 a los eventos prioritarios y un peso de 1 a los eventos normales, buscando maximizar una función objetivo clara y cuantificable. Esta tarea no solo pone a prueba las capacidades del modelo para entender y procesar instrucciones, sino que también exige habilidades avanzadas de razonamiento y planificación, típicas de problemas de intervalos ponderados en optimización combinatoria. Gracias a que la solución óptima puede obtenerse mediante algoritmos de programación dinámica, esto facilita la generación de una señal de recompensa objetiva y robusta, lo que es fundamental para el entrenamiento mediante aprendizaje por refuerzo. El proceso de entrenamiento se inicia con la generación de un conjunto de datos a partir de escenarios simulados.
Se crean múltiples ejemplos con eventos variados en duración y frecuencia, algunos de los cuales se superponen en el tiempo para simular problemas reales de programación. Se incluyen diferentes categorías temáticas para los eventos, como conciertos de música, conferencias técnicas o actividades académicas, asegurando así diversidad y complejidad. Además, se asignan prioridades de forma aleatoria para reforzar el aprendizaje del modelo en situaciones con conflictos y decisiones difíciles. A diferencia de enfoques supervisados tradicionales que requieren respuestas explícitas para cada ejemplo, GRPO permite al modelo aprender solo a partir de la señal de recompensa, lo cual simplifica la recolección de datos y amplía las posibilidades para entrenar en dominios verificables o estructurados. En este caso, se utiliza la diferencia entre la puntuación obtenida por la solución generada y la puntuación óptima para guiar el aprendizaje, incentivando la mejora gradual de la capacidad del modelo para resolver el problema.
Para el entrenamiento, se eligió un modelo de lenguaje de tamaño mediano especializado en código, conocido por su habilidad para seguir formatos específicos y realizar razonamientos estructurados. Se aplicaron técnicas de reducción de memoria y optimización de recursos, como QLoRA y una biblioteca llamada Unsloth, que facilitan el proceso incluso en hardware con limitaciones. Esta elección asegura un balance entre rendimiento y accesibilidad para otros investigadores que quieran replicar el experimento. Un aspecto crucial en el procedimiento fue el diseño de las funciones de recompensa. Para evitar que el modelo simplemente aprendiera a replicar patrones superficiales, las recompensas se diseñaron para evaluar no solo el formato correcto de salida, sino también la validez lógica de la programación generada.
El modelo debe respetar las reglas de no solapamiento de eventos, mantener el orden cronológico, incluir eventos reales del conjunto original y producir al menos dos eventos para ser considerado válido. El equilibrio entre las distintas funciones de recompensa fue delicado. Experimentos iniciales mostraron que premios individuales para cada regla conducían a comportamientos indeseados, como generar únicamente un evento para maximizar ciertos puntajes de forma tramposa. Por ello, se optó por combinar las recompensas en una señal compuesta que incentiva la generación de horarios ordenados y con buena puntuación en términos de duración ponderada, logrando así un aprendizaje más robusto y genuino. Durante el proceso de entrenamiento, se observaron mejoras graduales en el desempeño del modelo.
Las métricas indicaron un aumento sostenido en la calidad de las soluciones y una mayor adherencia a las reglas impuestas. Además, el modelo comenzó a producir razonamientos intermedios visibles en su salida, reflejando una capacidad cada vez más refinada para analizar conflictos y tomar decisiones fundamentadas dentro de los límites establecidos. Las evaluaciones finales revelaron que el modelo afinado con GRPO superaba a modelos más grandes y sin entrenamiento específico para esta tarea en varios aspectos. Logró mantener la estructura correcta del formato, respetar el orden cronológico y usar únicamente eventos válidos en la mayoría de las programaciones generadas. Sin embargo, aún presentó dificultades al evitar algunas superposiciones, lo que fue identificado como un área clave para mejoras futuras.
Este proyecto también destacó algunos desafíos prácticos relacionados con las herramientas empleadas. Por ejemplo, Unsloth, aunque eficiente para reducir uso de GPU, presenta limitaciones e inconsistencias que pueden complicar la conversión del modelo para uso en producción. Por lo tanto, se recomienda evaluar soluciones más estables como TRL para implementaciones a escala o productivas, siempre considerando el balance de recursos disponibles. Uno de los aprendizajes más valiosos que surge de esta experiencia es la importancia del modelo base en el éxito de GRPO. Si el modelo inicial carece de indicios prometedores para resolver la tarea, las mejoras mediante GRPO serán escasas o nulas.
Por el contrario, un modelo con capacidades más avanzadas o específicas facilitará la adquisición de comportamientos deseados de forma mucho más efectiva. Asimismo, se evidenció que la búsqueda de llamados "momentos aha" o revelaciones súbitas en la capacitación, donde el modelo despliega de manera inesperada razonamientos complejos, podría estar sobrevalorada. Investigaciones recientes sugieren que tales comportamientos pueden originarse a partir de las capacidades ya presentes en el modelo inicial y no son necesariamente producto exclusivo del entrenamiento con GRPO. Este experimento abre una puerta fascinante para que la comunidad explore nuevos usos de aprendizaje por refuerzo aplicado a modelos de lenguaje en tareas que requieren razonamiento estructurado y verificable. Elementos como la definición clara del problema, la generación automática de datasets, el diseño ingenioso de funciones de recompensa y la iteración constante durante el entrenamiento son factores determinantes para alcanzar resultados satisfactorios.








