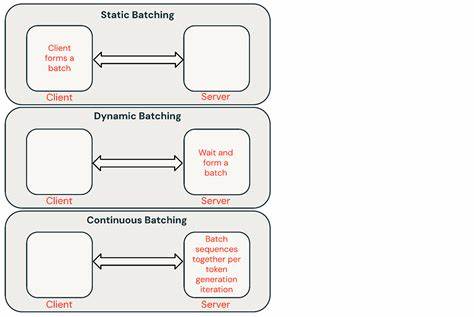
En el mundo actual, donde la inteligencia artificial y el procesamiento de lenguaje natural juegan un papel fundamental en múltiples áreas, la optimización de costos y eficiencia en la inferencia es una prioridad para empresas y desarrolladores. La inferencia de modelos de lenguaje grandes (LLM) a gran escala, especialmente cuando se procesan miles o millones de solicitudes a la vez, puede ser costosa si se realiza en tiempo real. Es aquí donde la inferencia en batch o por lotes se presenta como una solución revolucionaria que reduce considerablemente los gastos, sin comprometer la calidad y precisión de los resultados. Batch LLM inference o inferencia en lotes permite agrupar cientos o miles de solicitudes, procesándolas simultáneamente a través de una arquitectura diseñada para maximizar la eficiencia y el rendimiento. En lugar de enfocarse en la baja latencia, que es una característica crucial para aplicaciones en tiempo real, este método prioriza un alto rendimiento por volumen de datos.
De esta forma, es posible obtener respuestas para un gran número de prompts, optimizando el uso de recursos computacionales y disminuyendo el costo por token generado. Uno de los mayores beneficios de este enfoque es el ahorro económico. Gracias a la optimización del sistema para throughput o rendimiento, los proveedores pueden ofrecer costos de inferencia que son una fracción del precio habitual de las APIs en tiempo real. Por ejemplo, algunos modelos disponibles para batch inference tienen costos tan bajos como $0.01 por cada millón de tokens de salida, cifra que contrasta enormemente con las tarifas tradicionales en servicios de procesamiento en tiempo real.
El uso de modelos como Llama 3.1 de 8 mil millones de parámetros u otros modelos open source optimizados especialmente para batch inference hace posible procesar grandes cantidades de datos rápidamente sin sacrificar precisión. Además, opciones como Qwen y Deepseek, con diferentes configuraciones y niveles de capacidad, ofrecen alternativas variadas para distintos tipos de proyectos y necesidades específicas. El proceso para aprovechar la inferencia en batch es bastante sencillo para los desarrolladores. Primero, deben preparar un archivo en formato JSON que contenga todos los prompts que necesitan ser procesados.
Luego, mediante una API sencilla, se envía la URL de este archivo junto con la selección del modelo deseado. Debido a la naturaleza de la inferencia por lotes, los resultados no se entregan inmediatamente, pero siempre dentro de un período establecido, que puede ir desde unas pocas horas hasta un día, dependiendo del tamaño del lote. Esta modalidad es especialmente útil en escenarios donde la latencia no es crítica, sino la capacidad de manejar grandes volúmenes de datos. Entre los casos de uso más comunes se encuentran la generación de datos sintéticos para entrenamiento, procesos de RAG (Recuperación-Augmentada-Generación) para pre-procesamiento, extracción masiva de datos, evaluaciones automatizadas en proyectos de investigación y clasificación a gran escala de texto. La capacidad de enviar millones de solicitudes sin preocuparse por una facturación exorbitante o tiempos de procesamiento inasumibles está cambiando la forma en que las empresas adoptan la inteligencia artificial.
Muchas startups, laboratorios de investigación y departamentos de data science están adoptando estas plataformas para democratizar el acceso a modelos avanzados, especialmente al usar infraestructuras basadas en tecnologías open source que permiten mayor control y personalización. Otra ventaja clave de la inferencia por lotes es la flexibilidad. Aunque existen modelos predefinidos con tarifas ajustadas, la plataforma permite la implementación de modelos personalizados bajo petición, ampliando la variedad de aplicaciones posibles y facilitando la adaptación a casos muy específicos que requieran modelos especializados. Desde el punto de vista económico, solo se cobra por los tokens de salida, lo que significa que no se paga por los tokens de entrada o la operación interna. Esto es particularmente beneficioso para tareas como generación de texto, resumen o clasificación, donde la salida puede ser mucho menor comparada con la entrada procesada.
Con la aparición de soluciones como batchinference.com, que se encuentran en fase privada de beta pero con creciente interés, la comunidad tecnológica tiene acceso a interfaces simples y robustas que enfocan sus recursos en facilitar la integración mediante APIs, minimizando la curva de aprendizaje para la adopción tecnológica. La transparencia en la facturación, la comunicación constante con los usuarios y una política clara para evitar spam generan confianza y permiten que más usuarios se animen a probar esta innovadora modalidad. En definitiva, la inferencia en batch para modelos de lenguaje grandes representa una verdadera revolución en cuanto a la relación costo-beneficio en inteligencia artificial. Al combinar alta capacidad de procesamiento con menor gasto económico y una sencilla integración, abre la puerta a nuevas posibilidades en desarrollo de productos, investigación y operaciones impulsadas por AI.
A medida que el volumen y complejidad de datos crecen, adoptar tecnologías que optimicen recursos sin sacrificar calidad será clave para mantenerse competitivo. La inferencia por lotes llega para responder a esa necesidad defragmentando las barreras de costo y accesibilidad, permitiendo proyectos más ambiciosos y una mayor democratización en el acceso a la inteligencia artificial avanzada.