Los modelos ARIMA, también conocidos como modelos autorregresivos integrados de media móvil, continúan siendo uno de los enfoques más efectivos y populares para el análisis y la predicción de series temporales. En el ámbito de la programación en Python, un lenguaje de referencia para data science y machine learning, existen múltiples bibliotecas que implementan estos modelos. Sin embargo, resulta que, bajo el capó, muchas de estas herramientas dependen fundamentalmente de una librería central llamada Statsmodels. Explorar el porque y el cómo esta dependencia influye en la elección del paquete puede resultar esencial para quienes buscan optimizar sus proyectos analíticos. Para comenzar, es importante entender qué es un modelo ARIMA y por qué sigue siendo tan relevante.
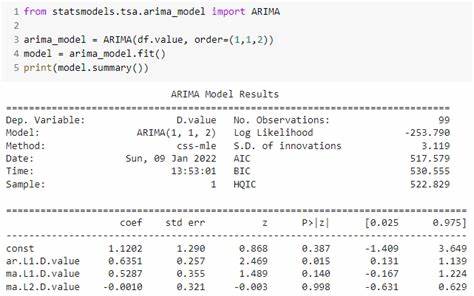
Las series temporales son datos organizados en función del tiempo, como el precio de las acciones día a día o las temperaturas en una ciudad cada hora. Predecir patrones futuros en estos datos es un desafío común en finanzas, economía, meteorología y muchas otras áreas. ARIMA combina tres conceptos: autoregresión (AR), diferenciación integrada (I) y promediado móvil (MA). Esta combinación permite modelar distintas características de la serie temporal, como tendencias y estacionalidades. En Python, la biblioteca pionera para modelar ARIMA es Statsmodels.
Esta librería es conocida por su robusta implementación de modelos estadísticos y provisión de herramientas para análisis econométrico. Statsmodels ofrece un módulo específico para ARIMA que incluye soporte para modelos estándar y estacionales, además de la integración con regresores exógenos, elementos externos que pueden influir en las predicciones. Su implementación es nativa y utiliza Cython para acelerar el procesamiento, lo que la convierte en una opción confiable y ampliamente utilizada. Más recientemente, otras bibliotecas como sktime, pmdarima, Darts, statsforecast y autogluon han surgido en la escena para cubrir diversas exigencias y simplificar el trabajo con series temporales. A primera vista, podría pensarse que estas librerías ofrecen nuevas implementaciones innovadoras de modelos ARIMA.
Sin embargo, al analizar su código fuente, se revela que muchas de ellas actúan principalmente como capas superiores o envoltorios sobre Statsmodels, brindando interfaces más amigables o integraciones con ecosistemas de machine learning. Por ejemplo, sktime destaca por ofrecer una API unificada para tareas de machine learning con series temporales. Esta biblioteca cuenta con módulos específicos que acomodan tanto la implementación original de Statsmodels como la opción automática de selección de modelos de Pmdarima. En esencia, sktime no reemplaza la lógica interna de Statsmodels, sino que la encapsula para facilitar su uso en pipelines complejos. La biblioteca pmdarima, diseñada para una automatización accesible y familiar a usuarios de scikit-learn, también se basa en Statsmodels para el núcleo del modelo ARIMA.
Su fuerza radica en la automatización del proceso de identificación de los mejores parámetros (p, d, q) del modelo, una tarea que suele ser laboriosa y técnica, pero nuevamente, la estimación matemática está delegada a Statsmodels. En la misma línea, Darts provee clases para el modelado ARIMA, tanto tradicionales como automáticos. Aunque la clase ARIMA está basada en Statsmodels, la implementación del AutoARIMA en Darts utiliza statsforecast, otro paquete interesante que introduce su propia implementación en C++ para acelerar cálculos. No obstante, incluso statsforecast recurre a Statsmodels para la estimación de regresores exógenos mediante métodos estadísticos como la regresión por mínimos cuadrados ordinarios. Autogluon representa una evolución hacia la automatización total en forecasting.
Su dependencia principal recae en statsforecast, lo que la aleja de depender directamente de Statsmodels. Esto refleja un movimiento hacia herramientas que priorizan el rendimiento y la eficiencia sin sacrificar la automatización y la facilidad de uso. Cabe destacar que esta independencia es relativamente reciente, ya que versiones anteriores de autogluon utilizaban Statsmodels. La razón de esta abundancia de wrappers y dependencias tiene sentido desde la perspectiva de desarrollo y mantenimiento. Implementar un modelo ARIMA desde cero implica un conocimiento profundo en estadística, optimización matemática y programación eficiente.
Statsmodels ha establecido un estándar basado en rigor académico y velocidad aceptable, por lo que reutilizar su núcleo permite que otros desarrolladores concentren sus esfuerzos en mejorar la experiencia del usuario, la automatización y la integración con otras herramientas de inteligencia artificial. Esta situación plantea algunas consideraciones importantes para los usuarios de estas librerías. Por un lado, es crucial ser consciente de que usar un modelo ARIMA en sktime o pmdarima significa, de alguna manera, recurrir a Statsmodels. Esto puede afectar aspectos como el rendimiento, la gestión de errores o el comportamiento frente a datos con características atípicas. Por otro, elegir herramientas que agreguen capas adicionales puede aportar beneficios, pero también complejidades, como tiempos de ejecución mayores o dificultades en la depuración.
En cuanto al rendimiento, statsforecast se presenta como una alternativa destacable para aquellos con necesidades de velocidad y escalabilidad. Su núcleo en C++ le permite ejecutar modelos ARIMA sustancialmente más rápido que Statsmodels, incluso cuatro veces en ciertos escenarios. Esto puede ser especialmente relevante en aplicaciones industriales o investigaciones donde se analizan miles de series temporales simultáneamente. Desde la perspectiva de usabilidad, pmdarima y Darts ofrecen una interfaz que se asemeja a la de scikit-learn, tan popular entre científicos de datos. Esto facilita su aprendizaje y uso, además de integrarse fácilmente en flujos de trabajo de machine learning existentes.
Autogluon lleva esta filosofía más allá al incorporar modelos automáticos de forecasting, eliminando la necesidad de ajuste manual y permitiendo probar múltiples configuraciones con un mínimo esfuerzo. La lección crucial para cualquier científico de datos o analista que trabaje con series temporales en Python es siempre invertir tiempo en entender las herramientas detrás del código. Hacer esto evita malentendidos sobre qué tan profundamente la librería se apoya en otras, qué aspectos son responsables de la calidad del modelo y dónde están las verdaderas oportunidades de mejora. Si bien Statsmodels no es la solución perfecta para todas las situaciones, su rol como base sólida y confiable en el ecosistema Python para modelos ARIMA es indiscutible. Sin embargo, la disponibilidad de librerías que aportan automatización, mejora en la usabilidad y mejor rendimiento abre un abanico de posibilidades a la hora de elegir la herramienta más adecuada.
En conclusión, muchos de los paquetes populares para modelado ARIMA en Python son equivalentes a envoltorios sobre la robusta librería Statsmodels. A excepción de algunos como statsforecast y autogluon, que apuntan a ofrecer implementaciones más propias o optimizadas, la reutilización de código es la norma. Por ello, la elección entre estas opciones dependerá del equilibrio que se busque entre rendimiento, facilidad de uso, automatización y funcionalidades adicionales. Comprender estas dinámicas permitirá tomar decisiones informadas y llevar los análisis de series temporales a otro nivel de precisión y eficiencia.