En el mundo actual de la ingeniería de datos y la analítica, DBT (Data Build Tool) se ha consolidado como una herramienta fundamental para la transformación de datos y la gestión de pipelines analíticos. Su capacidad para facilitar la escritura y mantenimiento de modelos SQL dentro de un entorno estructurado ha sido clave para que los equipos de ingeniería de datos escalen con eficiencia sus proyectos. Sin embargo, a pesar de su popularidad y potencia técnica, DBT presenta un reto importante: la complejidad en la interpretación y documentación clara de sus modelos para perfiles no técnicos o menos familiarizados con el código. DBT, en esencia, ayuda a orquestar transformaciones de datos mediante modelos SQL bien organizados y versionados, pero el entendimiento profundo de qué hace cada modelo, cómo se derivan los datos y cuál es el flujo de dependencias suele estar relegado a desarrolladores o analistas con cierto nivel técnico avanzado. Esto limita la colaboración con otros miembros del equipo como analistas de negocio, gerentes de producto o departamentos menos técnicos que también requieren entender los datos para tomar decisiones acertadas.
Aquí es donde entra en escena una propuesta innovadora de la comunidad de Data & AI Engineering de Hipposys: DBT to English. Este proyecto de código abierto ofrece una solución automatizada para generar documentación clara y amigable sobre proyectos DBT, utilizando modelos de lenguaje grandes (LLM, por sus siglas en inglés) como Anthropic o Amazon Bedrock para interpretar y traducir la complejidad del SQL y la arquitectura de modelos en explicaciones en lenguaje natural. Para contextualizar, DBT to English funciona a partir de los archivos manifest.json y catalog.json, que DBT genera como parte de su compilación del proyecto.
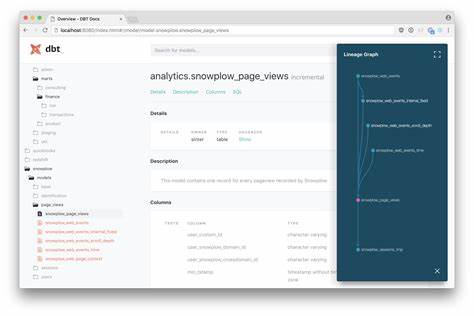
Estos archivos contienen toda la metadata, dependencias, estructura y detalles de cada modelo SQL. Lo revolucionario de esta herramienta es cómo aprovecha modelos de inteligencia artificial avanzada para procesar esta información y convertirla en descripciones detalladas, pero accesibles, de cada modelo, dónde se originan los datos, qué cálculos realizan y cómo se relacionan entre sí. Al implementar esta solución, los usuarios pueden obtener un resultado multidimensional: una descripción narrativa en lenguaje cotidiano que elimina la necesidad de leer SQL; un gráfico interactivo que revela el linaje a nivel granular, incluyendo no solo las relaciones entre modelos, sino también la lógica interna como CTEs y cálculos; tablas que explican el origen y transformación de cada columna; y un resumen general de dependencias entre modelos. Esta capa de información facilita a los equipos comprender, validar y colaborar en torno a sus pipelines de datos sin requerir conocimientos técnicos profundos. Una ventaja estratégica de DBT to English es su flexibilidad y personalización.
Los usuarios pueden modificar el “System Prompt”, es decir, las instrucciones enviadas al modelo de lenguaje, para adaptar el tono, el estilo o el formato de la documentación producida. Esto es vital para equipos que desean mantener una coherencia en su comunicación interna o aportar matices específicos para diferentes audiencias. Además, su interfaz amigable basada en Streamlit permite una rápida configuración, integración y uso local, facilitando la adopción sin complicaciones. El proyecto se ofrece públicamente en GitHub bajo una licencia abierta, invitando a la comunidad global a sumar esfuerzos. Este espíritu colaborativo promueve la mejora continua, la incorporación de nuevos proveedores LLM, el perfeccionamiento de prompts y la ampliación de funcionalidades.
Por ejemplo, futuras actualizaciones podrían incluir soporte para mayor variedad de archivos DBT, integración con plataformas de monitoreo de datos o funcionalidades automáticas para detección de errores y optimización de modelos. La necesidad de herramientas como DBT to English responde a un fenómeno creciente en las organizaciones: la democratización de los datos. Hoy, equipos multidisciplinarios requieren acceder y entender la información para tomar decisiones rápidamente. Sin embargo, las barreras técnicas dificultan esta interacción, generando cuellos de botella y riesgos en la gobernanza de datos. Al facilitar el acceso a la documentación inteligente y comprensible, se impulsa una cultura data-driven más inclusiva y efectiva.
Desde una perspectiva técnica, la arquitectura del proyecto se basa en la capacidad de los modelos de lenguaje para interpretar estructuras complejas y traducirlas a texto claro. Esto se acompaña de un procesamiento adicional para extraer diagramas y gráficos dinámicos, que aportan visualización directa de la estructura del proyecto. El aprovechamiento de tecnologías como Docker y Streamlit simplifica la instalación y despliegue, permitiendo probarlo fácilmente en diferentes entornos. Además, el enfoque de código abierto asegura transparencia, auditabilidad y adaptación a nuevas necesidades. Los equipos pueden integrar DBT to English dentro de sus pipelines de desarrollo continuo, automatizando la generación de documentación a medida que avanzan en la construcción de sus modelos.
Esto se traduce en una reducción significativa de tiempo invertido en documentación manual o en resolución de dudas dentro del equipo. Entender el funcionamiento y beneficios de DBT to English puede catapultar la eficiencia de los proyectos DBT en múltiples sectores. Desde empresas de tecnología, finanzas, hasta retail o salud, donde la gestión adecuada y transparencia en el tratamiento de datos resultan fundamentales para cumplir con normativas o mejorar la experiencia del cliente. Además, mejora la escalabilidad del equipo, facilitando la incorporación de nuevos miembros que pueden ponerse al día rápidamente gracias a la documentación generada de forma automática. En conclusión, DBT to English representa un avance significativo en la intersección entre ingeniería de datos y procesamiento de lenguaje natural.
Su innovadora propuesta elimina la barrera técnica para entender proyectos DBT complejos, traduciéndolos en lenguaje claro y visualizaciones intuitivas que cualquier perfil puede asimilar. Al ser un proyecto abierto y extensible, está llamado a convertirse en una herramienta clave para democratizar el acceso y comprensión de los datos en organizaciones modernas, impulsando una cultura data-driven exitosa y colaborativa. La invitación es clara: quienes trabajen con DBT o estén interesados en mejorar la interacción con sus datos pueden sumarse a esta iniciativa, contribuir con ideas o código y aprovechar una herramienta que ya está cambiando la forma en que se genera y consume la documentación técnica en analítica de datos. La comunidad y el futuro de la documentación inteligente están aquí, y el momento de adoptarlos es ahora.