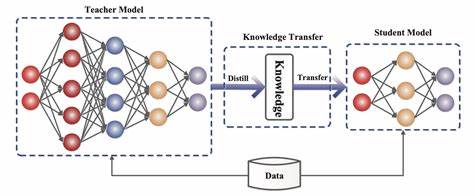
En el exigente campo de la inteligencia artificial y el procesamiento del lenguaje natural, la necesidad de optimizar modelos de lenguaje a gran escala (LLMs) para que sean más eficientes sin perder precisión es más urgente que nunca. La destilación del conocimiento, una técnica que consiste en transferir el saber de un modelo grande y pesado hacia otro más pequeño y ligero, se presenta como una estrategia fundamental para alcanzar este objetivo. En este contexto, surge DistilKitPlus, un innovador marco de trabajo de código abierto diseñado para facilitar la destilación entre cualquier modelo de lenguaje, aportando soluciones inteligentes y accesibles para entornos con limitaciones computacionales. DistilKitPlus nace con la misión de promover una destilación de conocimiento efectiva que se adapta a distintos escenarios y arquitecturas, incluso cuando los modelos docentes y los estudiantes emplean diferentes tokenizadores. Este enfoque elimina muchas barreras técnicas que tradicionalmente dificultaban la transferencia del conocimiento, ampliando así las posibilidades de aplicación en distintos dominios y proyectos.
Una de las características más importantes de DistilKitPlus es su soporte para la distilación por logits, que permite realizar la transferencia de conocimiento a nivel de salida de los modelos, lo que resulta en una replicación más fiel del comportamiento del modelo docente. Este proceso se puede ejecutar tanto cuando el modelo profesor y el alumno comparten el mismo tokenizador, como en casos donde estos difieren, a través de técnicas avanzadas de distilación universal y transporte óptimo multinivel. Dichas metodologías implementan algoritmos que alinean las distribuciones de salida de forma eficiente, superando las limitaciones habituales en la comparación directa de logits. El framework también se destaca por su almacenamiento y manejo eficiente de información, al permitir la generación previa de logits, lo que minimiza el consumo de memoria durante el entrenamiento, una ventaja clave para investigadores y desarrolladores que trabajan con recursos limitados o desean maximizar la velocidad de entrenamiento. Esta precomputación de salidas no solo optimiza el uso de hardware, sino que también contribuye a un flujo de trabajo más limpio y modulable.
Integrado con técnicas modernas de ajuste fino, DistilKitPlus incorpora soporte para LoRA (Low-Rank Adaptation), que posibilita un fine-tuning eficiente mediante adaptaciones de rango bajo en las capas del modelo. Esto se traduce en una notable reducción de parámetros que se deben ajustar, disminuyendo considerablemente el costo computacional y permitiendo la personalización del modelo estudiante sin la necesidad de recalibrar toda la arquitectura desde cero. En términos de optimización y eficiencia inferencial, DistilKitPlus brinda soporte para la cuantización de modelos a 4 bits, una técnica que reduce dramáticamente el tamaño del modelo y su consumo de memoria, manteniendo un rendimiento aceptable. Esta posibilidad abre puertas al despliegue de modelos robustos en dispositivos de capacidad limitada o en escenarios donde la latencia y los recursos son restricciones críticas. Respecto al entrenamiento a gran escala, el proyecto se ha asociado con frameworks reconocidos como Accelerate y DeepSpeed, que facilitan el entrenamiento distribuido y optimizan el uso de memoria en entornos multicore o que involucran clústeres.
Esta integración permite escalar las operaciones sin sacrificar la eficiencia, acelerando los procesos de investigación y desarrollo de modelos. DistilKitPlus se gestiona a través de una configuración flexible basada en archivos JSON, dando al usuario un control granular sobre aspectos clave como los modelos docente y alumno, el conjunto de datos, el tokenizador, hiperparámetros de entrenamiento, parámetros de destilación e incluso configuraciones específicas para LoRA y cuantización. Esta estructura modular no solo simplifica la experimentación, sino que también fomenta la reproducibilidad y la colaboración entre investigadores. La plataforma está preparada tanto para ejecutarse de manera local como para integrarse con Modal, una solución que automatiza y simplifica la ejecución de procesos de cómputo en la nube, gestionando internamente configuraciones de aceleración y distribución. De esta forma, abre la puerta a que usuarios con diferentes niveles de experiencia o capacidades técnicas puedan aprovechar distilKitPlus sin complicaciones adicionales.
Para comenzar a utilizar DistilKitPlus, el usuario debe clonar el repositorio oficial, instalar las dependencias necesarias y configurar los parámetros específicos a su proyecto mediante el archivo JSON. Posteriormente, se generan los logits del modelo profesor, para luego ejecutar el proceso de destilación que entrenará al modelo alumno bajo las condiciones definidas. Esta secuencia permite iterar y ajustar el sistema con facilidad, facilitando la convergencia hacia modelos más eficientes sin sacrificar el rendimiento. La comunidad alrededor de DistilKitPlus es activa y abierta, fomentando la colaboración mediante la contribución de mejoras, corrección de errores y expansión de funcionalidades. La licencia Apache-2.
0 que ampara el código promueve su uso y adaptación tanto en proyectos académicos como comerciales, garantizando un crecimiento orgánico y sostenible del proyecto. En conclusión, DistilKitPlus representa una herramienta esencial para profesionales e investigadores que buscan implementar destilación de conocimiento en modelos de lenguaje a gran escala de manera accesible, eficiente y adaptable. Su enfoque integral, combinando técnicas avanzadas de distilación, ajuste fino y optimización, junto con soporte para entornos distribuidos y cuantización, marca un antes y un después en el desarrollo y despliegue de LLMs. En un mundo donde la demanda por modelos IA más rápidos, ligeros y precisos solo aumenta, herramientas como DistilKitPlus ofrecen una vía clara para alcanzar estos objetivos, democratizando el acceso y el uso de tecnologías de vanguardia en inteligencia artificial.