En el mundo actual de la inteligencia artificial, especialmente en el desarrollo y despliegue de sistemas de machine learning (ML), comprender las arquitecturas que sustentan las operaciones es clave para alcanzar un rendimiento óptimo y garantizar la escalabilidad a largo plazo. Uno de los conceptos que muchos ingenieros y científicos de datos deben dominar es la distinción entre pipelines de ML offline y online, un tema que Paul Iusztin aborda con claridad y profundidad en su análisis sobre este asunto. La terminología puede resultar inicialmente confusa, particularmente porque en la formación académica y en muchos tutoriales se suelen presentar estas dos modalidades en un mismo entorno, como suele ser un cuaderno de Jupyter, lo que puede dar una falsa impresión de que son procesos similares o incluso intercambiables. Sin embargo, en empresas y proyectos reales, sobre todo cuando se trabaja a escala y en producción, las pipelines offline y online son esencialmente diferentes tanto en función como en implementación. Las pipelines de ML offline corresponden a procesos que se ejecutan de forma batch, es decir, en intervalos de tiempo previamente establecidos o como respuesta a eventos específicos.
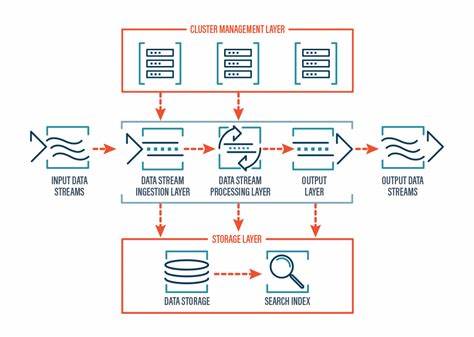
Estas tareas se encargan de actividades fundamentales que operan “detrás de cámaras”, tales como la recolección masiva de datos, la integración y transformación de esos datos (ETL), la generación de características (feature generation), y el entrenamiento continuo o periódico de los modelos. Una característica fundamental de estos procesos es que están desacoplados de las necesidades inmediatas del sistema en producción. Esto permite manejar grandes volúmenes de datos y realizar operaciones computacionales complejas sin afectar la latencia que experimentan los usuarios finales. Herramientas de MLOps como ZenML son comúnmente utilizadas para la orquestación, trazabilidad y versionado de estas pipelines offline, facilitando así la reproducibilidad y el mantenimiento de las mismas. Por otro lado, las pipelines online constituyen sistemas en tiempo real o casi real que responden de manera directa a las consultas de los usuarios o aplicaciones.
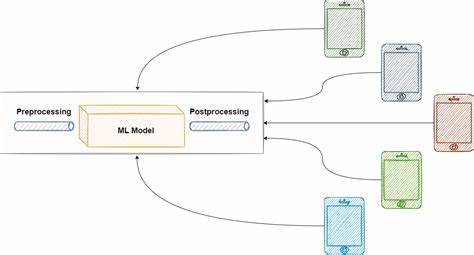
Este tipo de pipelines se les conoce también como pipelines de inferencia y su objetivo principal es proporcionar respuestas inmediatas, como predicciones o recomendaciones. En el contexto actual de la inteligencia artificial generativa (GenAI), ejemplos típicos incluyen flujos de trabajo de agentes conversacionales, endpoints RESTful que sirven modelos de lenguaje grande (LLM) y sistemas que sirven inferencias en tiempo real. La disponibilidad continua y la baja latencia son requisitos claves en las pipelines online, lo que implica que deben estar diseñadas para operar 24/7 y responder sin demoras perceptibles. Esto plantea desafíos técnicos distintos a los que enfrentan las pipelines offline, ya que aquí la prioridad es la rapidez y la robustez, no necesariamente el procesamiento masivo o complejidad computacional elevada. Una de las grandes enseñanzas que se desprende del enfoque de Paul Iusztin es la relevancia de mantener estas dos arquitecturas completamente separadas en entornos de producción.
Esta separación no solo ayuda a que cada componente funcione de manera óptima según su propósito, sino que también facilita el mantenimiento, la escalabilidad y la implementación de mejoras sin riesgos de afectar el servicio en vivo. Un ejemplo práctico de esta separación se observa en la construcción de asistentes de inteligencia artificial, como el curso “Second Brain AI Assistant” impartido por Iusztin, donde la pipeline offline es responsable de generar, procesar y almacenar datos en bases vectoriales o registros de modelos. El usuario final, al interactuar con el sistema, no está generando ni procesando datos en tiempo real sino consultando un repositorio previamente elaborado y optimizado para respuesta rápida. ¿Por qué es crítico entender estas diferencias? Porque sin esta distinción clara, los ingenieros corren el riesgo de construir sistemas que funcionen bien en ambientes controlados o en demo, pero que fracasen o presenten problemas graves cuando escalen a producción debido a cuellos de botella, problemas de latencia o dificultades en la actualización de modelos y datos. Además, la arquitectura desacoplada facilita innovar en cada segmento sin interferir en el otro.
Por ejemplo, se puede experimentar con nuevas técnicas de feature engineering o entrenar modelos más sofisticados en la pipeline offline mientras que la pipeline online sigue ofreciendo un servicio estable y eficiente. Intrínsecamente relacionado con las pipelines offline está el manejo y generación de datasets de alta calidad para los modelos, especialmente cuando se trabaja con modelos de lenguaje especializado o en fine-tuning de grandes LLMs. Construir estas datasets mediante pipelines es una tarea que debe manejar datos en bruto, evaluar la calidad, filtrar contenido, realizar procesos avanzados de resumen o distilación, y finalmente dividir el conjunto en partes para entrenamiento, evaluación y prueba. Estos procesos complejos, manejados mediante herramientas de orquestación como ZenML, garantizan no solo la calidad de los datos sino también la reproducibilidad y trazabilidad de las experimentaciones que alimentan la mejora continua de los modelos. Para aquellos involucrados en la construcción de aplicaciones basadas en IA, reconocer esta dualidad y adoptar arquitecturas diferenciadas para offline y online es un paso fundamental para construir soluciones robustas, escalables y de alto rendimiento.
Los modelos de inteligencia artificial no solo requieren datos y algoritmos potentes, sino también pipelines bien diseñadas y gestionadas que provean la base para su funcionamiento efectivo en entornos reales y exigentes. Finalmente, más allá de la teoría, la recomendación para ingenieros y equipos es comenzar a diseñar sus sistemas pensando en estas distinciones desde etapas tempranas, utilizando frameworks y arquitecturas que faciliten esta separación técnica y funcional. De esta manera, estará garantizado que el sistema no solo funcione hoy, sino que crezca y se adapte a futuras demandas con mayor facilidad y menor riesgo. Entender y aplicar correctamente los conceptos de pipelines offline y online es, en definitiva, un avance crucial para cualquier proyecto serio de machine learning y desarrollo de inteligencia artificial en producción. Gracias a este enfoque, se puede entregar a los usuarios experiencias más rápidas, precisas y confiables, al tiempo que se optimizan los recursos y se promueve la innovación continua dentro de los equipos de desarrollo.
Así, el mensaje clave es claro: piensa en las pipelines offline y online no como una única cadena de procesos sino como dos sistemas complementarios con objetivos específicos y características propias que deben ser diseñados y gestionados con herramientas y métodos adecuados para cada caso.