La reciente liberación de DeepSeek-R1, un modelo de razonamiento con pesos abiertos que iguala el desempeño del reconocido modelo o1 de OpenAI en diversas pruebas, ha generado una gran atención en el ámbito de la inteligencia artificial. Este fenómeno no solo se debe a su rendimiento competitivo, sino también al debate que ha surgido en torno a los costos y la metodología empleada para entrenarlo. Es fundamental entender el proceso y los componentes que hicieron posible desarrollar un modelo con estas características, desde su arquitectura hasta las fases de entrenamiento que incluyen pre-entrenamiento y aprendizaje por refuerzo. DeepSeek-R1 no fue construido desde cero; su base es DeepSeek v3, una versión anterior lanzada en diciembre de 2024 que integra innovaciones significativas tanto en estructura como en eficiencia. Este modelo se caracteriza por una arquitectura de mezcla de expertos (MoE, por sus siglas en inglés) muy dispersa, con un total impactante de 671 mil millones de parámetros, aunque apenas 37 mil millones activos para cada token procesado.
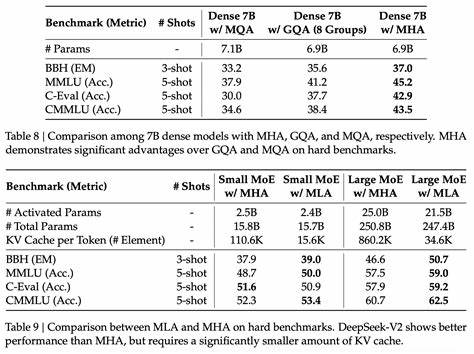
La estrategia de expertos se divide en un experto compartido que siempre está activo para todos los tokens y 256 expertos adicionales que se activan selectivamente, con ocho de ellos involucrados en el procesamiento de cada token. Esta elección permite una optimización y balance en la carga de cómputo, ayudando a mantener el rendimiento elevado mientras se controla la complejidad de cómputo. Una de las innovaciones técnicas destacadas en DeepSeek v3 es el mecanismo denominado atención latente multi-cabezal (MLA), diseñado para reducir el tamaño del caché de claves y valores sin la merma en desempeño común en otras técnicas habituales, tales como la atención por consulta agrupada o multi-consulta. MLA aumenta el costo aritmético durante la decodificación, haciendo que DeepSeek v3 sea un modelo atípico que depende más de operaciones aritméticas que de la memoria durante la inferencia con contextos largos. Por ejemplo, dicha atención aritmética se iguala a la multiplicación de parámetros y acumulaciones en contextos de alrededor de 5000 tokens, una cifra mucho menor comparada con modelos como Llama 3 70B que alcanzan esa equivalencia solo a los 50.
000 tokens. El avance de R1 respecto a v3 no recae en cambios arquitectónicos internos, sino en la incorporación de técnicas de aprendizaje por refuerzo para optimizar sus capacidades de razonamiento. Este método es más efectivo cuando el modelo de base, como v3, ya muestra un rendimiento intrínseco elevado, facilitando señales más consistentes durante el entrenamiento reforzado. El entrenamiento de DeepSeek-R1 se divide claramente en dos fases: pre-entrenamiento y aprendizaje por refuerzo, cada una con características y desafíos únicos. La fase de pre-entrenamiento de DeepSeek-R1 corresponde a la construcción de DeepSeek v3.
Este proceso implicó el uso de precisión mixta FP8 y un clúster de 2048 GPUs H800, donde el procesamiento de un billón de tokens demandaba aproximadamente 3.7 días, equivalentes a unas 180.000 horas de GPU H800. Con un dataset de entrenamiento de cerca de 14.8 billones de tokens, el costo estimado en horas GPU alcanzó 2.
66 millones, con un valor aproximado de 5.3 millones de dólares al asignar un precio de 2 dólares por hora GPU. Aunque estas cifras han sido objeto de escepticismo, resultan razonables para la escala y arquitectura utilizada. Uno de los aspectos más críticos y complejos durante esta fase fue la gestión de la paralelización entre expertos. Con 64 formas de paralelismo experto, la comunicación entre GPUs se volvió un punto delicado debido al necesario intercambio masivo de datos para pasar el flujo residual entre múltiples expertos activos en diferentes ubicaciones.
La volumetría estimada de comunicaciones alcanzó niveles sorprendentes, tanto así que la transferencia teórica de estos activaciones podría llevar más tiempo que toda la duración del entrenamiento en un entorno ideal con redes InfiniBand. Para contrarrestar esta limitación, DeepSeek implementó un solapamiento eficiente entre cálculos y comunicaciones, agrupó expertos con activaciones correlacionadas en posiciones topológicas cercanas para aprovechar conexiones NVLink de mayor velocidad y optimizó su configuración para reducir el impacto de latencias. Pese a estos esfuerzos la utilización efectiva (MFU) durante el entrenamiento preentrenamiento apenas superó el 23%, lo que pone de relieve la complejidad y menor eficiencia práctica de entrenar modelos MoE en comparación con lo que indican las métricas teóricas aritméticas. Este dato ayuda a entender que la relación costo-beneficio del entrenamiento de DeepSeek v3 no es una subestimación, sino que evidencia el alto esfuerzo computacional detrás de su desarrollo. La segunda etapa vital fue la aplicación del aprendizaje reforzado para convertir a DeepSeek v3 en DeepSeek-R1, el modelo pensado para el razonamiento avanzado.
La técnica empleada, llamada optimización de política relativa grupal (GRPO), es una variante más económica que el popular PPO, y se basa en muestrear lotes de preguntas a las que el modelo responde generando varias posibles respuestas, asignando recompensas bien mediante reglas automatizadas o con la ayuda de otro modelo de lenguaje para la evaluación. Estas recompensas se normalizan para estabilizar el entrenamiento, y el modelo ajusta sus parámetros con gradientes que promueven las respuestas de alto valor esperado y desalientan la desviación excesiva del comportamiento previamente aprendido. Los parámetros clave para este proceso incluyen un tamaño de lote B de 1024, generación de 64 respuestas por entrada y una longitud promedio L de tokens cercana a 4000 por secuencia, lo que convierte esta fase en un consumo masivo de cálculos. Un análisis profundo plantea que el costo total en FLOPs para esta fase de aprendizaje por refuerzo sería aproximadamente de 6.1e23 FLOPs, lo que traducido a horas y costos de GPU se ubica alrededor del millón de dólares, menor que los costos de preentrenamiento pero no despreciable.
La correlación entre tokens serialmente generados y la velocidad de inferencia estimada en 50 tokens por segundo permite concluir que esta fase pudo realizarse en una ventana razonable de entre 7 y 8 días en el clúster antes mencionado, manteniendo la coherencia en los esfuerzos computacionales. Después del entrenamiento por refuerzo inicial, DeepSeek aplica una etapa adicional conocida como cold-start, que utiliza un conjunto de datos curados, incluyendo resultados corregidos del R1-Zero, para afinar el modelo y estabilizar la calidad de las cadenas de pensamiento y la legibilidad humana de las respuestas generadas. Posteriormente se realiza un refinamiento supervisado con unas 600 mil muestras de razonamientos para mejorar aún más la precisión. Estas etapas finas consumen relativamente pocos recursos en comparación con las anteriores, pero son esenciales para afinar el modelo y adaptar su rendimiento a casos prácticos. En cuanto a rendimiento, DeepSeek-R1 compite estrechamente con OpenAI o1, con resultados de benchmarks donde ambos se superan mutuamente en distintas pruebas, mostrando una equivalencia práctica que promete elegir según el uso y costos.
Sin embargo, el factor diferenciador clave radica en los precios de acceso para el consumidor. DeepSeek-R1 se ofrece a un costo de aproximadamente 2.2 dólares por millón de tokens de salida, frente a los 60 dólares por millón de tokens de o1, una diferencia sustancial que marca la ventaja competitiva de DeepSeek en el mercado. Esta diferencia significativa en el precio no se explica tanto por una superioridad intrínseca de eficiencia del modelo, sino más bien por un margen comercial más ajustado de parte de DeepSeek y posiblemente una estrategia para ganar adopción en un sector dominado por grandes márgenes de laboratorios estadounidenses. Se prevé que esta dinámica influirá en la tensión competitiva y en las políticas de precios de los proveedores líderes, sobre todo ante la presión de laboratorios chinos y otras entidades que buscan entrar con propuestas económicamente atractivas y técnicamente sólidas.
En conclusión, el entrenamiento de DeepSeek-R1 revela un panorama muy avanzado en la ingeniería de modelos de inteligencia artificial, donde arquitecturas innovadoras, optimizaciones profundas en hardware y métodos eficientes de aprendizaje por refuerzo se combinan para generar modelos razonadores potentes y accesibles. Más allá de las controversias iniciales sobre costos, los datos técnicos y estimaciones sugieren que los valores reportados son coherentes con la envergadura y sofisticación del entrenamiento efectuado. El horizonte de la inteligencia artificial se ve influenciado por estas estrategias que buscan equilibrio entre calidad, costo y accesibilidad, configurando la competencia global y el futuro de los modelos de lenguaje avanzados.








