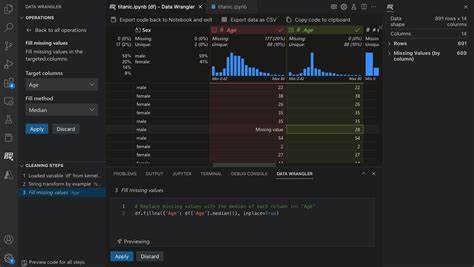
En el mundo actual, el manejo eficiente y ágil de datos se ha convertido en una competencia esencial para profesionales de distintas áreas, especialmente para aquellos que trabajan en desarrollo de software, análisis de datos y construcción de pipelines. Data Wrangler, el plugin de Microsoft para VSCode, se ha destacado por ofrecer una interfaz rápida y sencilla para inspeccionar y prototipar transformaciones de archivos en formatos como parquet y CSV. Sin embargo, como toda herramienta, puede que no se adapte a todas las necesidades o preferencias, lo que impulsa la búsqueda de alternativas que permitan realizar tareas similares o complementarias. La ventaja de Data Wrangler es su integración con un entorno de desarrollo popular como VSCode, facilitando tareas que, por lo general, requieren escribir código manualmente. No obstante, esta herramienta puede presentar limitaciones cuando se requiere mayor personalización o trabajar con conjuntos de datos complejos y variados.
Por esta razón, muchos profesionales exploran otras opciones que puedan ofrecer un mejor equilibrio entre facilidad de uso, potencia y capacidad de integración. Una de las alternativas más mencionadas en círculos de análisis de datos es Visidata, una herramienta que, aunque potente, presenta una curva de aprendizaje bastante pronunciada. Visidata es una aplicación basada en la terminal que permite una manipulación eficiente de datos, brindando operaciones rápidas para filtrar, transformar y explorar tablas. Su fuerza radica en la velocidad y la flexibilidad, pero debido a su interfaz y dinámica de uso, puede resultar intimidante para usuarios acostumbrados a herramientas con interfaces gráficas. Además, trasladar las transformaciones hechas con Visidata a un código Python reproducible puede no ser inmediato, lo que puede dificultar su inclusión en pipelines automatizados.
Para quienes buscan una alternativa que combine facilidad de uso con potencia, algunas herramientas visuales para la manipulación de datos pueden ser más adecuadas. Plataformas como Trifacta Wrangler (en que se basa parcialmente Data Wrangler) ofrecen entornos visuales robustos para transformar datos, permitiendo que usuarios sin profundos conocimientos en programación generen reglas de transformación de manera intuitiva. Estas soluciones suelen ser utilizadas en entornos empresariales, donde la colaboración y la escalabilidad son requisitos clave. Sin embargo, suelen ser herramientas de pago y pueden requerir considerables recursos para su explotación total. Otra opción valiosa en el ecosistema open source es PandasGUI, una interfaz gráfica para la biblioteca Pandas en Python.
Este proyecto ofrece una ventana de exploración y transformación para DataFrames, facilitando operaciones comunes como filtrado, agregación y limpieza de datos sin necesidad de escribir código extenso. Su ventaja es que permite un rápido prototipado y luego puede exportar esos procesos para ser integrados en scripts o pipelines más grandes. Si bien puede no ser tan sofisticado como Data Wrangler en algunos aspectos, su capacidad de integración con Python hace que sea una opción popular para equipos que trabajan con este lenguaje. Para aquellos que prefieren plataformas basadas en la nube, herramientas como Google Cloud Dataprep (también impulsada por Trifacta) ofrecen una experiencia visual para la limpieza, transformación y preparación de datos. Estas plataformas suelen integrarse con otros servicios de nube, facilitando pipelines end-to-end para análisis avanzado y aprendizaje automático.
Su desventaja puede ser la dependencia de una infraestructura y posibles costos asociados al uso. En el ámbito de las bibliotecas y lenguajes, la llegada de nuevas librerías y entornos que simplifican la manipulación de conjuntos de datos ha sido notable. Por ejemplo, Polars es una biblioteca en Rust con enlaces a Python que promete ser una alternativa más rápida y eficiente frente a Pandas, especialmente para grandes volúmenes de datos. Si bien Polars no es una herramienta visual, se considera una opción para quienes buscan mayor rendimiento a nivel de código. Otra línea de alternativas la constituyen herramientas de código bajo o sin código (low-code/no-code), que permiten al usuario transformar y analizar datos mediante interfaces gráficas, flujos visuales y acciones predefinidas.
Ejemplos populares incluyen Airtable, Tableau Prep y Alteryx. Aunque están más orientadas hacia usuarios con poca experiencia técnica, su adopción puede ser una solución efectiva para acelerar procesos y disminuir errores. La elección entre estas herramientas dependerá en gran medida del contexto de trabajo, las habilidades del equipo y las necesidades específicas del proyecto. Por ejemplo, equipos muy técnicos, familiarizados con Python y la línea de comandos, pueden beneficiarse de la potencia de Visidata, PandasGUI o Polars, mientras que equipos con perfiles mixtos o menos técnicos pueden inclinarse por soluciones visuales como Trifacta o herramientas low-code. Es importante destacar que la aplicación continua y la integración con pipelines automatizados es un factor crucial en la selección.
Por consiguiente, contar con herramientas que permitan exportar las transformaciones en forma de scripts reutilizables o conectarse con orquestadores como Airflow o Prefect puede marcar una diferencia significativa en términos de eficiencia y mantenimiento en el largo plazo. También merece atención los recursos educativos y la comunidad que acompaña a cada herramienta. Una herramienta con extensa documentación, tutoriales y una comunidad activa facilita la resolución de dudas y la adopción dentro de una organización. Finalmente, el desarrollo tecnológico es dinámico y las herramientas evolucionan constantemente. Por ello, mantenerse actualizado y probar varias opciones puede ayudar a encontrar la mejor solución para cada contexto.
En conclusión, existen diversas alternativas a Data Wrangler que pueden satisfacer necesidades similares en la manipulación y transformación de datos. Tanto herramientas visuales como basadas en código, y soluciones en la nube o locales, ofrecen distintas ventajas que pueden favorecer distintos perfiles y escenarios laborales. La clave está en evaluar las características específicas de cada opción y su alineación con los objetivos y capacidades del equipo para optimizar el flujo de trabajo en la gestión de datos.








