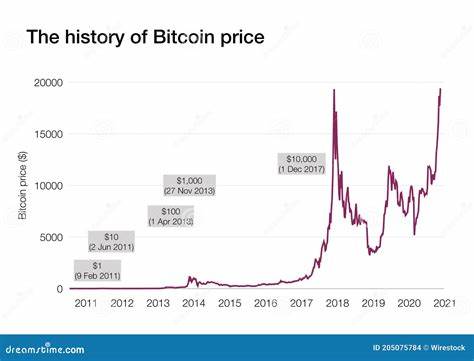
El mundo de las criptomonedas es uno de los mercados financieros más volátiles y dinámicos en la actualidad. La naturaleza cambiante de los precios y la influencia de múltiples factores hacen que predecir con exactitud la tendencia de estas monedas digitales sea un desafío considerable. Sin embargo, las tecnologías de inteligencia artificial, en particular el aprendizaje automático y aprendizaje profundo, han abierto nuevas oportunidades para abordar estos desafíos y generar predicciones más acertadas basadas en datos históricos y patrones complejos. Uno de los enfoques más innovadores en la predicción de precios criptográficos combina modelos de regresión clásica con redes neuronales profundas, específicamente redes LSTM (Long Short-Term Memory). Este tipo de arquitecturas están diseñadas para capturar dependencias temporales y secuenciales en los datos, algo fundamental en series temporales como las cotizaciones diarias de criptomonedas.
El punto de partida en esta metodología es la recopilación y preparación de datos utilizados en el entrenamiento de los modelos. La información histórica que incluye precios de apertura, cierre, máximos, mínimos y volumen de transacciones se obtiene generalmente de bases de datos o archivos CSV. Antes de alimentar esta información a los modelos, es necesario realizar un proceso riguroso de limpieza y preprocesamiento, que incluye convertir los formatos de fecha y hora, manejar valores faltantes y asegurar la correcta uniformidad de los datos numéricos para evitar sesgos. Un aspecto crucial en este proceso es la ingeniería de características, donde a partir de los datos básicos se generan indicadores técnicos que reflejan el comportamiento del mercado. Indicadores como las medias móviles exponenciales (EMA) para distintos períodos, el índice de fuerza relativa (RSI), el MACD con sus componentes de señal e histograma, bandas de Bollinger, el oscilador estocástico y el rango verdadero promedio (ATR), proporcionan una visión más enriquecida y compleja de la dinámica del mercado.
Estos elementos permiten a los modelos aprender patrones no lineales y captar señales que podrían predecir movimientos futuros. Al construir el conjunto de datos final, además de los indicadores técnicos, se añade la variable objetivo conocida como “Next_Close”, que representa el precio de cierre del día siguiente, el valor que los modelos intentan predecir. La división de los datos en conjuntos de entrenamiento y prueba debe respetar el carácter temporal de las series. Normalmente se reserva alrededor del 80% de los datos cronológicamente más antiguos para entrenar los modelos y el 20% restante para evaluar su desempeño. Esta segmentación evita que el modelo tenga información futura durante el entrenamiento, lo que garantizaría una evaluación poco realista.
En cuanto a los modelos usados, se combinan técnicas clásicas con una aproximación avanzada. Los modelos de regresión basados en Random Forest y XGBoost se emplean para identificar patrones no lineales y gradualmente mejorar la precisión de predicción mediante ensamblajes de árboles. Random Forest ofrece la ventaja de ser relativamente robusto frente al ruido y la posibilidad de examinar la importancia de las variables, mientras que XGBoost, un método de gradient boosting, destaca por su eficiencia y capacidad para manejar grandes conjuntos de datos con alta dimensionalidad. La incorporación de una red neuronal LSTM representa el componente más avanzado del proyecto. Su estructura especializada en memoria a largo plazo le permite manejar secuencias temporales de datos con mayor efectividad que las redes neuronales tradicionales.
A través de la creación de secuencias de entrada derivadas de los datos históricos y las características calculadas, el modelo LSTM puede extraer información sobre tendencias y ciclos que no son evidentes a simple vista. El entrenamiento de estos modelos implica el ajuste de hiperparámetros, que son configuraciones internas que impactan la calidad y velocidad del aprendizaje, tales como el número de árboles en los modelos de regresión o la cantidad de neuronas y capas en la red LSTM. La experimentación y ajuste continuo permiten encontrar el equilibrio adecuado para evitar tanto el sobreajuste como el subajuste, optimizando la capacidad predictiva. La evaluación se realiza utilizando métricas estadísticas estándar como el error cuadrático medio (MSE), que mide la desviación promedio al cuadrado entre los valores predichos y reales, el error absoluto medio (MAE), que mide la desviación promedio sin considerar el signo, y el coeficiente de determinación R², que indica la proporción de variabilidad explicada por el modelo. Además de las métricas, la visualización de resultados mediante gráficos comparativos entre predicciones y valores reales ayuda a interpretar la calidad del modelo y detectar posibles anomalías o patrones no captados.
Una de las fortalezas destacadas en este tipo de proyectos es la modularidad y la capacidad de mejorar iterativamente a través del tiempo. La flexibilidad para incorporar nuevos indicadores técnicos, modificar arquitecturas de redes neuronales, o implementar técnicas de tuning más sofisticadas, ofrece un camino claro para incrementar el rendimiento del modelo. Asimismo, este enfoque es una puerta de entrada para explorar nuevas estrategias como el uso de modelos híbridos que combinen algoritmos de machine learning con técnicas de deep learning, la integración de noticias y análisis de sentimiento en redes sociales para enriquecer los datos, o la aplicación de métodos de aprendizaje por refuerzo para adaptarse mejor a las condiciones cambiantes del mercado. El uso de herramientas ampliamente disponibles en el ecosistema Python, como Pandas para manipulación de datos, NumPy para cálculos numéricos, pandas_ta para el cálculo de indicadores técnicos, Scikit-Learn para la implementación de modelos clásicos, XGBoost para boosting eficiente, y TensorFlow/Keras para construir redes LSTM, facilita el desarrollo y la replicabilidad del proyecto. Este enfoque también se beneficia del entorno flexible de Jupyter o Google Colab para pruebas interactivas y visualización en tiempo real.
En resumen, la predicción del precio de criptomonedas mediante modelos de regresión y aprendizaje profundo representa una combinación poderosa que puede adaptarse a la naturaleza compleja y volátil de los mercados digitales. A través de un proceso detallado que incluye limpieza y enriquecimiento de datos, ingeniería de características, entrenamiento y evaluación rigurosa, es posible generar predicciones con un grado notable de precisión. Este avance tecnológico no solo ilumina potenciales estrategias de inversión más informadas, sino que también contribuye a una mejor comprensión de cómo se comportan las criptomonedas a lo largo del tiempo, abriendo caminos para futuros desarrollos y aplicaciones tanto en finanzas como en análisis de datos. Con la continua evolución de herramientas y algoritmos, es esperable que las técnicas de inteligencia artificial desempeñen un papel cada vez más crucial en la gestión y previsión de activos digitales, ayudando a comunidades, inversores y desarrolladores a navegar un mercado en constante cambio con mayor confianza y eficacia.