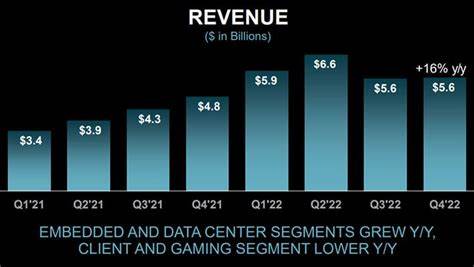
En la era digital actual, donde el acceso a la información en tiempo real es crucial, la relación entre Redis, uno de los sistemas de cache más populares, y las bases de datos SQL, se ha convertido en un pilar fundamental para garantizar un rendimiento óptimo en aplicaciones de alto tráfico. Mantener la consistencia entre estos dos sistemas de almacenamiento, que operan con diferentes mecanismos y objetivos, representa un reto importante para desarrolladores e ingenieros de software. Redis destaca por ser un almacén de datos en memoria, rápido y eficiente, ideal para almacenar información temporal o “hot data”. Por otro lado, las bases de datos SQL ofrecen propiedades robustas como ACID, que aseguran la atomicidad, consistencia, aislamiento y durabilidad en las transacciones, garantizando que los datos sean precisos y confiables. Sin embargo, cuando ambos sistemas se combinan para mejorar el rendimiento general, la duplicidad en el almacenamiento de datos plantea problemas críticos sobre la sincronización y actualización correcta de la información.
Uno de los desafíos clave radica en que la base de datos SQL es la fuente de verdad, pero acceder a ella directamente en cada operación puede generar cuellos de botella y latencias elevadas, especialmente en escenarios con alta concurrencia. Por esta razón, muchos sistemas optan por implementar una capa de cache con Redis para almacenar temporalmente datos que son frecuentemente solicitados. Esta práctica ayuda a disminuir la carga sobre el sistema de base de datos y a acelerar considerablemente los tiempos de respuesta. Para garantizar que el cache no se convierta en una fuente de datos obsoleta o “sucia”, es necesario definir mecanismos claros para manejar la coherencia entre la cache y la base de datos. Estas estrategias deben balancear la necesidad de rendimiento con la integridad y precisión de la información.
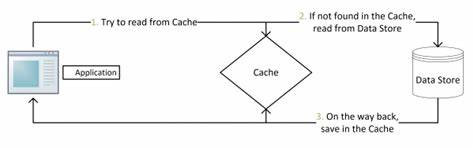
Una aproximación común es el patrón conocido como Cache Aside. Bajo esta metodología, cuando se realiza una lectura, el sistema primero verifica si el dato está presente en la cache. En caso afirmativo, devuelve la información directamente, evitando la consulta a la base de datos. Si por el contrario el dato no está en la cache, entonces se hace la consulta a la base de datos, se almacena el resultado en Redis y se entrega la respuesta al cliente. Para operaciones que modifican datos, el patrón indica primero modificar la base de datos y luego eliminar la entrada correspondiente en la cache para evitar inconsistencia futura.
Aunque esta técnica es ampliamente utilizada y funciona bien en la mayoría de los casos, puede presentar escenarios en los que se lea información desactualizada debido a pequeñas ventanas de inconsistencia, especialmente bajo condiciones de alta concurrencia y fallas inesperadas del sistema. Por ejemplo, si una operación actualiza la base de datos pero falla al eliminar la cache, las solicitudes siguientes podrían seguir leyendo datos obsoletos almacenados en Redis. Para mitigar estos riesgos, se han propuesto variantes y mejoras. Una consiste en implementar el patrón de doble eliminación o Double Delete, que agrega un corto retardo tras la actualización de la base de datos para borrar nuevamente la entrada en la cache. Así, se busca capturar y eliminar posibles datos sucios que hayan sido recreados en la cache por procesos concurrentes tras la primera eliminación.
Aunque no garantiza una consistencia estrica, reduce considerablemente la probabilidad de leer datos desactualizados. Otra solución avanzada se basa en aprovechar los registros de binlog que generan las bases de datos SQL, como MySQL. Herramientas como Canal, desarrollada por Alibaba, suscriben y reproducen cambios directamente desde el log de transacciones hacia Redis. Esta técnica asegura que las modificaciones en la base de datos se reflejen con alta fidelidad en la cache, proporcionando una mayor durabilidad y confiabilidad en la sincronización, sin depender únicamente de la lógica de la aplicación para mantener el cache actualizado. Patrones como Write Through y Write Behind proponen también alternativas interesantes.
Write Through implica que las modificaciones se realicen primero en la cache y de manera sincronizada se reflejen inmediatamente en la base de datos. Esto puede mejorar la latencia de escritura pero introduce riesgos en caso de que la cache sufra pérdidas antes de la replicación. Write Behind, en cambio, registra los cambios primero en la cache y replica asíncronamente en la base de datos usando mecanismos como colas de mensajes, ofreciendo mayores rendimientos pero incrementando la ventana de inconsistencia. Es importante destacar que ninguna de estas soluciones ofrece una garantía absoluta de consistencia fuerte sin sacrificar rendimiento o complejidad. La mayoría de los sistemas optan por la consistencia eventual, aceptando un pequeño margen de error en aras de ofrecer una experiencia rápida y escalable a sus usuarios.
En la práctica, es fundamental identificar qué datos realmente requieren alta consistencia y cuáles pueden tolerar ligeras demoras en la actualización. La aplicación del principio de Pareto, almacenando en cache solo el 20% de los datos que generan el 80% del tráfico, ayuda a optimizar los recursos y enfocar los mecanismos de sincronización en la información crítica. Finalmente, para diseñar una arquitectura robusta con Redis y SQL, es indispensable contar con monitoreo constante y mecanismos de recuperación que detecten y corrijan posibles desalineamientos en los datos. Pruebas de estrés y simulaciones deben ser parte integral del proceso de desarrollo para entender cómo se comporta el sistema ante diferentes volúmenes y patrones de acceso. En resumen, la consistencia entre Redis cache y bases de datos SQL es un aspecto complejo que requiere un balance delicado entre rapidez, confiabilidad y manejabilidad.
Adoptar patrones adecuados, comprender sus limitaciones y aplicar soluciones complementarias como la monitorización y el uso inteligente de la cache son pasos esenciales para lograr un sistema eficiente y confiable. A medida que la tecnología evoluciona, nuevas técnicas y herramientas seguirán emergiendo para facilitar este desafío, pero el conocimiento de los fundamentos y sus implicaciones es imprescindible para cualquier desarrollador o arquitecto de sistemas.