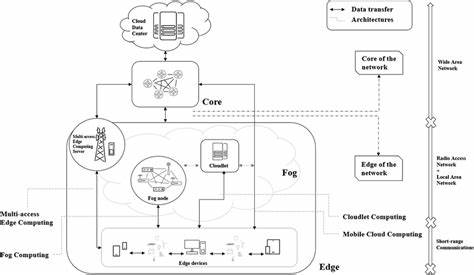
En la era digital actual, los modelos de lenguaje grandes (LLMs, por sus siglas en inglés) se han convertido en la avanzada tecnología que revoluciona la inteligencia artificial, permitiendo desde asistentes virtuales hasta aplicaciones de procesamiento de lenguaje natural de alto nivel. Sin embargo, el desafío más grande es su implementación efectiva, especialmente cuando se busca operar en entornos de computación en el borde u edge computing. Estos entornos se caracterizan por la proximidad del procesamiento de datos al origen donde se generan, como dispositivos IoT, teléfonos inteligentes u otros aparatos con recursos limitados. El potencial de desplegar LLMs en estos dispositivos es enorme, ya que se puede disminuir considerablemente la latencia de respuesta y proteger la privacidad del usuario al evitar el envío constante de datos a la nube.\n\nAun así, la complejidad de los LLMs, que pueden contener miles de millones de parámetros, requiere un nivel de capacidad computacional y almacenamiento que supera por lejos los recursos disponibles en la mayoría de los dispositivos de borde.
Por ello, la innovación en estrategias de optimización resulta indispensable para lograr un despliegue exitoso. Existen cuatro enfoques clave que deben combinarse de manera armónica para obtener resultados prácticos: la compresión del modelo, la cuantización, la inferencia distribuida y el aprendizaje federado. Cada uno aporta soluciones específicas a las limitaciones intrínsecas del hardware del borde y juntos conforman el camino para lograr despliegues eficientes y escalables.\n\nLa compresión de modelos es una técnica que reduce el tamaño y los requisitos computacionales mediante métodos como la poda de redes neuronales, la eliminación de parámetros redundantes y el uso de redes más livianas, sin sacrificar significativamente la precisión del modelo. Esta técnica permite ajustar modelos originalmente gigantescos a formatos que puedan adaptarse a los recursos limitados sin perder funcionalidades críticas.
\n\nLa cuantización complementa la compresión al reducir la precisión numérica de los cálculos realizados dentro del modelo. Por ejemplo, en lugar de utilizar números de 32 bits, se pueden emplear valores de 8 o incluso 4 bits para representar pesos y activaciones. Si bien este procedimiento puede introducir algún grado de error, las técnicas modernas han conseguido mantener la calidad y eficiencia, logrando una disminución considerable en el consumo energético y memoria requerida.\n\nLa inferencia distribuida es otra pieza clave que aprovecha la colaboración entre distintos dispositivos del borde o con la nube para ejecutar diferentes partes del modelo en paralelo o secuencialmente. Esto no sólo ayuda a superar limitaciones individuales de hardware, sino que también mejora la eficiencia general y la capacidad de respuesta del sistema.
Mediante la segmentación inteligente y la orquestación dinámica, sistemas complejos pueden funcionar en tiempo real, incluso en contextos con conectividad variable.\n\nEl aprendizaje federado aporta adicionalmente un mecanismo para entrenar modelos directamente en los dispositivos de borde, utilizando los datos locales sin necesidad de centralizar la información. Esto fortalece la privacidad, pues los datos sensibles nunca abandonan su punto origen, y también potencia la personalización de los modelos para contextos particulares. Al compartir solo las actualizaciones del modelo en lugar de los datos, se reducen los riesgos de seguridad y se optimiza el uso del ancho de banda.\n\nLa unión de estos métodos crea una solución integral para el despliegue de LLMs en entornos de computación en el borde.
No obstante, el diseño de algoritmos específicos que integren estas técnicas en un marco coherente es esencial para superar desafíos técnicos. En investigaciones recientes, se han desarrollado nuevos algoritmos que permiten combinar la compresión y cuantización con estrategias de distribución e inteligencia colaborativa adaptada. Estos avances empíricos demuestran mejoras significativas en términos de rendimiento y viabilidad real en dispositivos limitados.\n\nAdemás, la optimización tiene un impacto directo en distintos sectores. En áreas como la salud, la inteligencia artificial en el borde puede proporcionar diagnósticos inmediatos y personalizados, manteniendo la privacidad del paciente.
En ciudades inteligentes, sensores con LLMs optimizados permiten gestionar tráfico y recursos en tiempo real sin depender exclusivamente de la comunicación con servidores remotos. En la industria, la automatización puede alcanzar niveles superiores, respondiendo a las condiciones del entorno con rapidez y autonomía.\n\nLa reducción de la latencia representa una ventaja competitiva crucial. Al evitar la dependencia constante de la nube, las aplicaciones pueden reaccionar más rápido y con mayor fiabilidad, especialmente en lugares con conectividad deficiente o intermitente. Este factor es vital para sectores como vehículos autónomos o sistemas de seguridad, donde la velocidad en la toma de decisiones es crítica.
\n\nSi bien el avance en hardware continúa ofreciendo dispositivos más poderosos, la necesidad de optimización en software y arquitectura sigue siendo prioritaria. De hecho, la escalabilidad y sustentabilidad de soluciones basadas en LLMs dependerán cada vez más de la habilidad para integrar estas técnicas de manera eficiente. La investigación en este campo también abre oportunidades para la democratización del acceso a inteligencia artificial avanzada, haciendo posible que más usuarios y dispositivos se beneficien de capacidades inteligentes sin infraestructura costosa.\n\nFinalmente, es relevante mencionar que el marco de optimización para el despliegue de modelos de lenguaje grandes en el borde no es válido solo para ámbitos específicos, sino que establece las bases para la próxima generación de sistemas inteligentes distribuidos. La convergencia de IA, redes de computación y privacidad configurará un nuevo ecosistema tecnológico que potenciará múltiples innovaciones.
Por lo tanto, continuar profundizando en la investigación, desarrollo y adopción de estas técnicas resulta fundamental para revolucionar la forma en la que interactuamos con la tecnología y los datos en tiempo real.