En la era digital actual, el contenido audiovisual crece de manera exponencial, lo que plantea grandes retos para su análisis y comprensión eficiente. Los videos son una fuente invaluable de información, pero su volumen hace necesario contar con herramientas tecnológicas avanzadas que permitan procesarlos, extraer su esencia y facilitar el acceso rápido a los datos relevantes. En este contexto, la tecnología de modelos de lenguaje visual multimodal (VLM) como Gemma3, integrada en plataformas locales, se posiciona como una solución innovadora para la síntesis automática de videos. Esta herramienta no solo permite resumir contenidos de manera precisa, sino también ofrecer análisis semántico detallado y contextualizado, clave para múltiples sectores como la seguridad, la educación, el entretenimiento y el marketing digital. La ventaja principal de utilizar Gemma3 en un entorno local radica en la privacidad, rapidez y personalización que ofrece.
A diferencia de servicios basados íntegramente en la nube, esta arquitectura descentralizada facilita un control total sobre los datos y reduce significativamente la dependencia de la conectividad o las limitaciones asociadas a la latencia. Al procesar videos de hasta un minuto con esta tecnología, es posible extraer cuadros claves mediante técnicas de descomposición temporal que optimizan el análisis sin perder información fundamental. Los modelos de lenguaje visual multimodal combinan la capacidad de interpretar imágenes y texto, posibilitando una comprensión profunda y contextualizada del contenido audiovisual. Con la capacidad de interactuar con un motor gemma3 a través del marco Ollama, los usuarios pueden generar resúmenes a partir de indicaciones personalizadas. Esto significa que más allá de un simple testimonio visual, la herramienta contextualiza eventos, identifica objetos, personajes o acciones específicas, y responde a consultas orientadas a objetivos particulares.
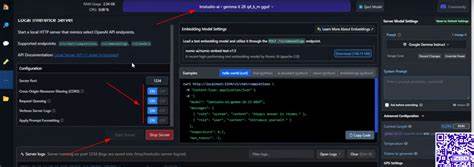
Implementar este sistema requiere una configuración técnica accesible con herramientas de código abierto y un entorno Python actualizado, específicamente Python 3.12 o superior. El flujo de trabajo inicia con la extracción de frames o cuadros del video a una tasa controlable acorde a la necesidad del análisis, ya sea para detalle fino o un resumen más general. Luego, estos cuadros se procesan en lote para alimentar al modelo gemma3, generando un análisis integral que comprende las dinámicas y el contenido del video. Uno de los aspectos revolucionarios que aporta esta solución es la capacidad de reemplazar análisis manuales extensos con interpretaciones automatizadas que no solo ahorran tiempo, sino que también aumentan objetividad.
Por ejemplo, en la industria de la vigilancia, identificar rápidamente actividades sospechosas o patrones recurrentes en grabaciones es esencial para mejorar la seguridad. Del mismo modo, en el ámbito educativo, resumir contenido audiovisual facilita la creación de materiales didácticos concisos y mejor dirigidos a las necesidades de los estudiantes. La configuración flexible mediante variables de entorno (.env) permite adaptar el sistema a diferentes modelos y endpoints, ya sea el servicio interno de Ollama o conectores externos como las API de OpenAI, manteniendo la posibilidad de intervenir sobre la calidad y costo del procesamiento. Esta adaptabilidad es crucial para que instituciones y empresas puedan implementar la herramienta manteniendo el equilibrio entre rendimiento y presupuesto.
El soporte local de Gemma3 ofrece resultados en tiempo casi real, dependiendo del hardware, lo que abre paso a aplicaciones en las que la latencia es un factor crítico, como la atención al cliente en plataformas de streaming, el análisis en tiempo real en centros de control o la mejora de interacciones en entornos inmersivos. Asimismo, la capacidad de procesar prompts personalizados aporta un grado de sofisticación que permite no solamente resumir una escena sino responder preguntas específicas sobre ella o elaborar descripciones detalladas para contenidos accesibles. Por supuesto, el sistema también presenta limitaciones que es importante considerar. El tiempo máximo de procesamiento establecido hasta ahora es de aproximadamente un minuto de contenido, debido a demandas computacionales y capacidad de memoria. Asimismo, un aumento en la tasa de cuadros extraídos o el tamaño de lotes incrementa el costo y el tiempo del análisis, por lo que la configuración debe ser cuidadosamente balanceada según las necesidades específicas.
La experiencia de usuarios que han probado este sistema indica que la precisión y riqueza de la interpretación dependen tanto del modelo elegido como del endpoint utilizado. De hecho, se han observado variaciones en resultados ejecutando el mismo modelo en Ollama frente a OpenAI, lo que invita a realizar pruebas previas para seleccionar la mejor opción a implementar. Es importante destacar que la licencia bajo la cual se distribuye la herramienta propicia una amplia libertad para su uso, modificación y distribución, consolidándola como una interesante propuesta de código abierto para desarrolladores y profesionales que desean incorporar capacidades avanzadas de visión computarizada y procesamiento del lenguaje natural en sus proyectos. El respaldo de VAST Data y la publicación abierta de Matthew Rogers contribuyen a impulsar la innovación y colaboración en este ámbito. En términos prácticos, el uso básico del sistema consiste en proporcionar un archivo de video y una indicación textual sobre lo que se desea analizar o resumir.
Las ejecuciones se pueden parametrizar con opciones como la tasa de cuadros por segundo a extraer y el tamaño de lotes procesados, lo que facilita la adaptación a distintos tipos de contenido y objetivos analíticos. Esta interfaz accesible hace de la herramienta una solución viable para profesionales no especializados en inteligencia artificial pero interesados en aprovechar los avances tecnológicos en sus campos. En conclusión, la combinación de tecnologías VLM y entornos locales para el procesamiento automatizado de video está marcando un antes y un después en la forma en que se aborda la comprensión audiovisual. La propuesta de procesamiento con Gemma3 local ofrece una alternativa robusta, flexible y escalable que potencia desde la generación automática de resúmenes hasta análisis contextuales más complejos. Su adopción podría traducirse en ahorros significativos de tiempo y recursos, una mejor toma de decisiones basada en datos visuales y una democratización del acceso a tecnologías de inteligencia artificial avanzadas.
Conforme evolucione la capacidad de los modelos y la infraestructura computacional, podemos anticipar aplicaciones aún más innovadoras que transformarán múltiples industrias y modos de interacción con el contenido audiovisual.