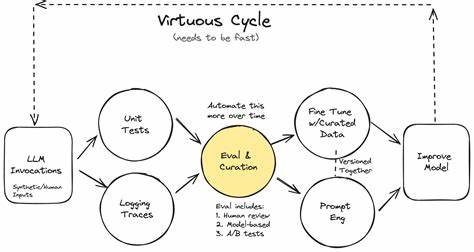
En el dinámico y vertiginoso mundo de la inteligencia artificial, la capacidad para mejorar constantemente los sistemas no solo es una ventaja, sino una necesidad. Para los ingenieros de IA, uno de los conceptos más transformadores y a menudo subestimados es que las evaluaciones —o 'evals'— no son únicamente una fase del desarrollo sino, de hecho, el producto en sí mismo. Comprender esta verdad puede cambiar la forma en que se diseñan, construyen y mejoran las soluciones inteligentes. Para empezar, es fundamental reconocer que los sistemas de inteligencia artificial más exitosos y avanzados no se definen solamente por su rendimiento en un momento dado, sino por cómo se evalúan día a día durante su evolución constante. En otras palabras, lo que diferencia a múltiples agentes de IA que operan en el mismo mercado no es solo su capacidad técnica o el acceso a datos, sino la calidad y agilidad de sus métodos de evaluación.
Es ese proceso de evaluación lo que asegura que los modelos mejoren de manera sostenida, respondan rápidamente a nuevos desafíos y mantengan la funcionalidad esperada. En el ámbito de los productos nativos de IA, las evals son el núcleo de desarrollo e innovación. Sin una medida fiable y bien estructurada, las mejoras se vuelven poco efectivas o, peor aún, se basan en intuiciones e hipótesis erróneas. Un enfoque tradicional y rígido para evaluar sistemas puede resultar insuficiente debido a la velocidad a la que evolucionan los modelos de lenguaje y los productos de IA en general. Por ello, las evaluaciones deben ser flexibles, adaptativas y, lo más importante, ligeras para que se puedan implementar continuamente y con rapidez.
Un caso ilustrativo proviene de Tusk, una startup que desarrolla un agente de generación automatizada de pruebas unitarias basado en inteligencia artificial. Desde sus inicios, Tusk enfrentó el reto de operar en un entorno de constante cambio, donde las arquitecturas de código y los flujos de trabajo evolucionan minuto a minuto. La necesidad de tener evaluaciones que pudieran adaptarse sin perder precisión fue clave para su proceso de desarrollo exitoso. El equipo de Tusk se topó con tres grandes desafíos. Primero, la naturaleza acelerada del desarrollo significaba que las plantillas de evaluación tradicionales resultaban rápidamente obsoletas.
Segundo, la complejidad del sistema, que no se limita a una simple consulta y respuesta, sino que se compone de múltiples herramientas y etapas interconectadas, exigía evaluar componentes específicos de forma aislada para poder mejorar cada uno detalladamente. Tercero, la entrada y salida de datos variaba en estructura y forma constantemente, complicando la tarea de aplicar un único marco de evaluación inflexible. En respuesta a estas circunstancias, la solución encontró un pilar fundamental en la manera en que se escribió el código. Optar por la programación funcional, evitando estructuras orientadas a objetos y dependencias profundas, permitió al equipo de Tusk diseñar componentes que funcionan como funciones puras: transforman una entrada en una salida sin estados globales ni dependencias ocultas. Esta estrategia facilita evaluar cada pieza individualmente, similar a cómo se escriben las pruebas unitarias en desarrollo de software convencional.
Una parte crucial de su producto es la incorporación de archivos de prueba existentes y nuevos. En lugar de generar pruebas de manera aleatoria, el sistema de Tusk integra inteligentemente casos nuevos manteniendo la integridad del formato, las importaciones y el estilo del archivo. Para perfeccionar esta funcionalidad, el equipo creó evaluaciones que podían comparar distintas aproximaciones, medir la confiabilidad y analizar la latencia, todo ello sin depender de infraestructuras externas o complejas. El enfoque pragmático de Tusk se basa en evaluaciones ligeras. No necesitaron implementar una infraestructura enorme ni sistemas sofisticados.
En lugar de eso, establecieron un contrato claro: definir con precisión qué debe entrar en el componente, qué salida esperamos y cómo interpretar esos resultados. A partir de allí, simplemente usan pequeños scripts capaces de ejecutar el componente en un conjunto representativo de datos, generar informes visuales en HTML y mostrar resultados detallados para un análisis rápido. Herramientas basadas en inteligencia artificial como Cursor y Claude facilitan la automatización en la generación de estos reportes visuales, permitiendo inspeccionar entradas, salidas y conclusiones en un formato accesible y claro. Esta simplicidad trae ventajas invaluables. La velocidad es uno de sus fuertes, pudiendo levantar evaluaciones en apenas minutos.
La flexibilidad es otra, ya que basta con actualizar el conjunto de datos para adaptarse a cambios en entradas o salidas, pudiendo regenerar los reportes rápidamente. Finalmente, el costo se mantiene bajo gracias a la eliminación de dependencias de infraestructuras externas o plataformas de evaluación complejas. Al disponer de un sistema de evaluación accesible y reutilizable, Tusk pudo experimentar con distintas estrategias para problemas específicos, comparar resultados y tomar decisiones fundamentadas. Esta transparencia permitió validar mejoras en modelos o cambios en el pipeline sin depender de intuiciones, apoyando un desarrollo guiado exclusivamente por datos. El hecho de que estas evaluaciones sean sencillas y útiles combate una problemática común entre los ingenieros de IA: la tediosidad de realizar evaluaciones rutinarias.
Muchos comienzan desarrollos con más sentimiento que análisis estructurado, lo que puede ser suficiente para un producto inicial, pero limita la escalabilidad y la calidad final al no implementarse un proceso sólido de evaluación. Por ello, adoptar un desarrollo guiado por evaluaciones—eval-driven development—se vuelve la estrategia más adecuada para crear productos de IA robustos, escalables y de alta calidad. Esta metodología no debe ser vista como una carga, sino como el motor que impulsa la mejora continua, la innovación rápida y la confianza en el producto final. En resumen, para los ingenieros y equipos que trabajan en productos basados en inteligencia artificial, las evaluaciones son mucho más que una simple medida de rendimiento: son el producto. El secreto está en mantener el código funcional, garantizar que las evaluaciones sean ligeras y usar herramientas que automaticen la generación de informes para poder iterar velozmente.
Conforme los agentes evolucionan y las demandas del mercado se hacen más exigentes, quienes sepan aprovechar evaluaciones ágiles y efectivas estarán un paso adelante. Si aún se sienten atrapados en la incertidumbre de cómo medir sus sistemas o cómo integrar evaluaciones rápidas y útiles en su flujo de trabajo, empezar con evaluaciones ligeras basadas en funciones y reportes visuales sencillos puede marcar una diferencia sorprendente. No solo ayudará a identificar fallas o mejoras, sino que también acelerará el desarrollo y elevará la calidad del producto a niveles que antes parecían inalcanzables. En definitiva, recordar que las evaluaciones son el verdadero producto en la ingeniería de inteligencia artificial no es únicamente una idea revolucionaria; es una llamada a transformar la manera en que abordamos el desarrollo, garantizando que cada iteración sea mejor y más inteligente que la anterior.








