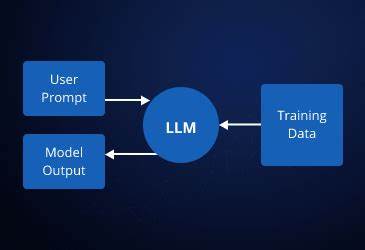
La revolución tecnológica impulsada por los modelos de lenguaje a gran escala o LLMs (por sus siglas en inglés) está transformando rápidamente la manera en que desarrollamos y utilizamos aplicaciones de inteligencia artificial. Sin embargo, construir proyectos funcionales y adaptados a necesidades específicas puede resultar una tarea compleja para muchos desarrolladores. Compartir experiencias y estrategias efectivas resulta crucial para avanzar en este campo y facilitar el acceso a soluciones innovadoras. A partir de una experiencia directa en la creación de un proyecto base impulsado por un LLM, es posible identificar patrones y técnicas que pueden ser aplicados para optimizar y simplificar el desarrollo, sobre todo en las etapas iniciales donde la prioridad es consolidar el motor central antes que la interfaz personalizada. Para ello, utilizar una interfaz web de código abierto como Open WebUI representa una ventaja.
Este front-end ofrece una interfaz de chat que incorpora características esenciales, desde renderizado de elementos de IA en formato Markdown hasta el manejo de etiquetas especiales para la interacción. La personalización es sencilla y su estructura modular permite adaptarla a necesidades específicas sin desgastar recursos en construir una interfaz desde cero, proporcionando un excelente punto de partida para aplicaciones basadas en LLMs. Un aspecto fundamental para manejar la comunicación entre la interfaz y el motor de LLMs es la adaptación y filtrado de mensajes. Open WebUI introduce el concepto de filtros o adaptadores que transforman los datos que recibe para que coincidan con el formato requerido por el motor. Por defecto, ciertos datos relevantes como identificadores de usuario pueden no estar incluidos, lo que puede ser problemático para aplicaciones que manejan conversaciones específicas o que requieren un seguimiento detallado del contexto.
Mediante un script en Python sencillo se pueden extraer datos como el chat ID, el identificador del usuario y el mensaje nuevo para enviarlos a la lógica del motor. Este enfoque evita la necesidad de reenviar toda la conversación en cada llamada, confiando en que el motor gestione internamente el estado del diálogo. Así, se optimiza el uso de recursos y se simplifica la arquitectura del sistema. La configuración administrativa también tiene un papel decisivo. Al conectar el adaptador al Open WebUI, se deben definir los endpoints de la aplicación y nombrar los modelos que se están utilizando.
En ambientes de desarrollo, herramientas como Tailscale permiten exponer un servidor local mediante URLs accesibles en la red tailnet, facilitando pruebas y despliegues rápidos sin complejidades de configuración de infraestructura. Otra ventaja de Open WebUI es la capacidad de crear espacios de trabajo o workspaces que permiten superponer configuraciones o adaptadores sobre modelos existentes. Esto habilita la personalización de la experiencia sin interferir con la funcionalidad básica de los modelos, otorgando flexibilidad y modularidad a la hora de escalar o diversificar los proyectos basados en LLMs. Una de las características más relevantes en el desarrollo de aplicaciones que usan LLMs es el manejo de las respuestas en streaming, que permite obtener resultados parciales en tiempo real mientras el modelo genera la respuesta completa. Para habilitar esta capacidad, es necesario implementar un endpoint compatible con el estándar OpenAI para /chat/completions, que mantenga abierta la conexión y transmita fragmentos de datos conforme están disponibles.
En la arquitectura del backend, el framework Elixir destaca por su modelo de concurrencia inherente, que permite mantener múltiples conexiones abiertas sin comprometer la eficiencia ni la estabilidad del sistema. En este contexto, Phoenix, el framework web de Elixir, junto con bibliotecas como Plug, Req y PubSub, facilita la creación de flujos reactivos y concurrentes, ideales para la interacción continua con modelos de lenguaje. El mecanismo que mantiene la conexión abierta y transmite los fragmentos de respuestas se basa en un bucle de escucha que suscribe al servidor a un tópico específico, basado en el mensaje que se está procesando. Cada fragmento que llega se envía inmediatamente al cliente mediante el método chunk, hasta que se recibe la señal de fin del streaming, momento en el cual la conexión se cierra de manera ordenada. Esta implementación garantiza una experiencia de usuario fluida, sin tiempos muertos, y permite manejar las limitaciones de latencia o velocidad propias de los modelos.
El procesamiento de mensajes dentro del motor se realiza mediante una pipeline o cadena de procesamiento. Esta lógica analiza qué tipo de mensaje llegó, determina la estrategia para responder y, si es necesario, utiliza llamadas adicionales a LLMs para obtener respuestas contextuales o enriquecidas. Esta modularidad en el procesamiento aumenta la escalabilidad de la aplicación y permite incorporar capas de lógica de negocio o inteligencia adicional según la necesidad. Para administrar la transmisión y el almacenamiento de los fragmentos que llegan en streaming se recurre a agentes, estructuras simples y eficientes en Elixir que permiten mantener estados mutables locales. El agente actúa como un buffer que acumula cada fragmento enviado por el modelo, facilitando luego la reconstrucción completa del mensaje cuando termina el proceso.
La función encargada de ensamblar estos fragmentos filtra datos vacíos o la etiqueta de finalización y convierte las cadenas JSON en estructuras manipulables, extrayendo el contenido relevante que se concatenará para formar la respuesta final. Este procedimiento es compatible con cualquier LLM que siga el formato estándar provisto por OpenAI, lo que maximiza la interoperabilidad y facilita la integración de distintos motores de lenguaje. Más allá de la arquitectura técnica, la elección de Elixir como lenguaje y entorno resulta esencial por sus características de concurrencia y eficiencia, que permiten manejar sin dificultad la alta demanda de conexiones abiertas y procesos asíncronos propios de aplicaciones en tiempo real. La combinación de Elixir con Phoenix PubSub, agentes y la gestión eficiente de conexiones HTTP proporciona un marco de desarrollo poderoso, que se traduce en un código claro y fácilmente mantenible. Esta facilidad también se refleja en la experiencia del desarrollador, que puede razonar de forma lineal sobre el flujo de mensajes, sin tener que preocuparse excesivamente por problemas complicados de concurrencia tradicionales.
En definitiva, construir con LLMs requiere una combinación de herramientas robustas, diseño pensado para la concurrencia y adaptabilidad a distintos formatos e interfaces. La estrategia de priorizar el núcleo del motor, usar interfaces abiertas y enfocarse en la correcta manipulación y transmisión de mensajes permite acelerar los ciclos de desarrollo sin sacrificar la calidad ni la personalización. Al aprovechar patrones establecidos como adaptadores para la entrada, streaming con SSE, agentes para el buffer y pipelines de procesamiento, es posible diseñar aplicaciones avanzadas de inteligencia artificial con un alto grado de control y flexibilidad. A medida que la tecnología evoluciona, este tipo de enfoques marcarán la pauta para un desarrollo más eficiente, escalable y accesible de soluciones IA que pueden transformar múltiples industrias y áreas del conocimiento. Para quienes desean adentrarse más en este tipo de desarrollo, comunidades abiertas y recursos como repositorios de código y diagramas de flujo representan herramientas fundamentales para compartir conocimiento, resolver dudas y crear sinergias.
Así, el ecosistema de creación con modelos de lenguaje a gran escala se enriquece y crece de forma sostenible, potenciando la innovación en inteligencia artificial aplicada.