En el mundo tecnológico actual, donde la comunicación eficiente y en tiempo real entre sistemas es fundamental, surge la necesidad de métodos que permitan transmitir eventos de manera sencilla y escalable. HTTP Feeds emerge como una especificación minimalista que facilita la transmisión y replicación de eventos mediante simples APIs HTTP. Esta metodología innovadora se presenta como una alternativa viable para quienes buscan decouplar sistemas sin la complejidad o costos asociados con intermediarios tradicionales como Kafka o RabbitMQ. HTTP Feeds funciona a partir de un endpoint HTTP que responde a solicitudes GET devolviendo secuencias cronológicas de eventos. Estos eventos están serializados bajo el estándar CloudEvents y se entregan en lotes utilizando el tipo de contenido application/cloudevents-batch+json.
Además, para navegar por la transmisión y evitar pérdidas o repeticiones, se utiliza un parámetro de consulta llamado lastEventId, que permite al cliente mantener el seguimiento de los eventos ya procesados y continuar la lectura desde el último punto. El mecanismo provoca una serie de ventajas importantes para la sincronización y el consumo de eventos. En primer lugar, al utilizar HTTP, que es un protocolo universalmente soportado y ampliamente conocido, se elimina la complejidad inherente a la configuración y mantenimiento de infraestructuras para mensajería asíncrona específica. En segundo lugar, el uso de CloudEvents garantiza que los eventos sean entendidos de forma estandarizada, favoreciendo la interoperabilidad entre sistemas heterogéneos. La propuesta de HTTP Feeds también contempla distintas modalidades de polling que el cliente puede emplear para mantener la suscripción a feeds en tiempo real.
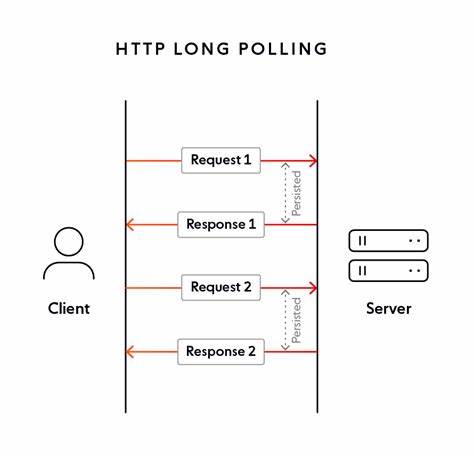
El método más básico, el polling simple, consiste en realizar consultas periódicas al servidor enviando el último ID de evento procesado. Si la respuesta es un array vacío, esto indica que no hay eventos nuevos, por lo que el cliente espera un tiempo antes de consultar nuevamente. Este flujo asegura que los sistemas no se saturen con peticiones innecesarias y que se mantenga la coherencia en la recepción de datos. Por otra parte, para mitigar los tiempos de latencia y mejorar la eficiencia en la transferencia de información, HTTP Feeds también contempla el uso de long polling. En este caso, el cliente incluye un parámetro de timeout que especifica cuánto tiempo está dispuesto a esperar por la respuesta.
El servidor mantiene la conexión abierta hasta que aparezcan nuevos eventos o que expire el tiempo indicado. Esta técnica reduce considerablemente las consultas repetitivas y ofrece una experiencia más fluida para el consumidor final. La especificación también aborda retos importantes en la ordenación y gestión de eventos. Dado que la navegación entre eventos depende de lastEventId, es imprescindible que los eventos estén fuertemente ordenados. Para conseguirlo, se sugieren identificadores tipo UUIDv6 generados temporalmente o la incorporación de secuencias numéricas delegadas por la base de datos que contienen el feed.
Esta organización asegura que incluso si eventos antiguos se eliminan por motivos de compactación o limpieza, la consistencia y continuidad del flujo no se ven comprometidas. Por otra parte, HTTP Feeds resulta extremadamente útil para la llamada replicación de datos asíncrona y la sincronización entre sistemas, especialmente mediante lo que se denomina como aggregate feeds. Estos feeds representan colecciones de objetos mutables donde cada evento refleja el estado actual actualizado de un objeto identificado por un subject. De esta manera, los consumidores pueden construir y mantener completos modelos locales de lectura, obteniendo así una visión casi en tiempo real de la información. La compaction o compactación es un concepto fundamental para mantener estos feeds manejables y efectivos.
Debido a que cada actualización genera una nueva entrada en el feed con el estado completo, el volumen de datos puede crecer rápidamente causando retrasos en la sincronización de nuevos clientes. Para evitarlo, los servidores pueden eliminar eventos previos relacionados con el mismo subject, garantizando que la última versión del objeto sea la que predomina, reduciendo así el tamaño de los streams y acelerando el tiempo de puesta al día. Otro aspecto crucial que contempla la especificación es la posibilidad de eliminar agregados por razones como el cumplimiento normativo o la gestión del ciclo de vida de los datos. En este sentido, se utiliza un campo especial method con valor DELETE para señalizar a los consumidores que un objeto debe ser eliminado localmente. Esta acción va acompañada de posteriores procesos de compactación para limpiar el feed y mantenerlo actualizado.
Respecto a la arquitectura de seguridad, HTTP Feeds aprovecha las capacidades de autenticación y autorización existentes en HTTP, pudiendo integrar esquemas estándar como Basic Auth o tokens Bearer. Esto permite proteger el acceso a los feeds y aplicar filtros basados en la identidad del consumidor si es necesario. Es importante destacar que el filtrado personalizado puede afectar a la posibilidad de cacheo, una consideración importante para el diseño del sistema y la gestión del rendimiento. El uso de cabeceras HTTP estándar para el control de cacheo también está contemplado para optimizar la entrega de contenido estable y limitar el tráfico innecesario. Por ejemplo, cuando una respuesta es inmutable, servidores pueden entregar indicaciones claras para mantener los datos almacenados en caché durante períodos prolongados.
El impacto de HTTP Feeds en el ecosistema tecnológico es considerable, pues ofrece una solución sencilla pero poderosa para escenarios donde se requieren sistemas acoplados de manera laxa y eficientes en cuanto a infraestructura. Su implementación puede favorecer la realización de arquitecturas basadas en eventos con menor complejidad operativa y reducir la dependencia de tecnologías propietarias o pesadas. Para desarrolladores interesados en adoptar HTTP Feeds, existen diversas librerías y ejemplos disponibles, incluyendo implementaciones en Spring Boot y ejemplos serverless en AWS, que demuestran cómo arrancar con esta tecnología. Estas herramientas facilitan la integración con sistemas existentes y la construcción de endpoints que sigan la especificación de forma correcta. La evolución de HTTP Feeds proviene del estándar rest-feeds, mejorando su simplicidad y aplicabilidad para casos modernos donde el consumo de eventos debe ser ligero, accesible y flexible.
El mantenimiento activo y la apertura a contribuciones permiten que la comunidad pueda adaptar y expandir sus funcionalidades conforme surjan nuevas necesidades o mejoras tecnológicas. En definitiva, HTTP Feeds representa una apuesta práctica para la transmisión asíncrona de eventos con alta interoperabilidad y simplicidad. La utilización de mecanismos estándar como HTTP y CloudEvents, junto con la posibilidad de implementación tanto de polling tradicional como de long polling, ofrecen a las organizaciones una herramienta robusta para lograr sincronización eficiente y comunicación con baja latencia entre sistemas distribuidos. Dado el auge de arquitecturas orientadas a eventos y la necesidad de integración constante de sistemas heterogéneos, entender y aplicar HTTP Feeds puede marcar la diferencia en proyectos que busquen escalabilidad, facilidad de mantenimiento y reducción de costes operativos. La especificación, aunque minimalista, cubre aspectos esenciales como ordenación, compaction, eliminación de agregados y autenticación, lo que permite construir soluciones completas y adaptadas a diversos dominios de negocio.
Es clave para futuros desarrollos considerar la idempotencia en el procesamiento de eventos y persistir los identificadores últimos procesados para evitar duplicidades o pérdidas. Con buenas prácticas y una implementación adecuada, HTTP Feeds puede ser la base para arquitecturas desacopladas y sistemas reactivos que respondan a la dinámica del mundo digital con eficiencia y fiabilidad.