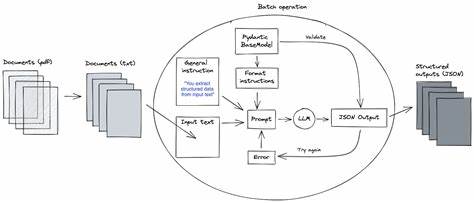
El mundo digital moderno está inundado por cantidades masivas de datos no estructurados, aquellos que no se adecuan fácilmente a los formatos tradicionales de bases de datos y sistemas de procesamiento convencionales. Este tipo de información puede encontrarse en contratos, correos electrónicos, documentos legales, informes financieros, imágenes escaneadas, y una variedad casi infinita de documentos y formatos. En este contexto, los Modelos de Lenguaje Grandes (LLMs, por sus siglas en inglés) han emergido como una promesa revolucionaria para la comprensión y procesamiento de lenguaje natural. Sin embargo, a pesar de su potencial, aún no son la solución definitiva que muchos anticipan para el procesamiento de datos no estructurados. Este análisis profundiza en las razones detrás de esta realidad y examina las tendencias tecnológicas que podrían modificar el panorama en el futuro cercano.
El primer aspecto que hay que considerar es la naturaleza intrínsecamente compleja de los datos no estructurados. A diferencia de los datos estructurados, que se organizan de manera ordenada en tablas y bases de datos con formatos predefinidos, los datos no estructurados presentan un volumen enorme, variantes ilimitadas y una alta variabilidad tanto en la forma como en el contenido. La mayoría de los sistemas de gestión de datos y procesos ETL (Extracción, Transformación y Carga) están diseñados para tratar con datos estructurados donde las reglas y los esquemas son claros y estables. El reto surge entonces cuando se intenta aplicar las mismas técnicas o incluso tecnologías avanzadas como los LLMs a materiales que no tienen un formato estándar o contenido fácilmente interpretable. Los LLMs tienen la capacidad de interpretar y generar lenguaje natural con una precisión impresionante y son capaces de procesar textos complejos, reconocer contextos e incluso aprender de manera continua.
Aun así, estos modelos presentan limitaciones significativas cuando se utilizan para procesar grandes volúmenes de datos no estructurados en escenarios empresariales o industriales reales. El principal obstáculo es la escala. Muchas organizaciones manejan terabytes, o incluso petabytes, de información que no está organizada, y alimentar esta cantidad inmensa de datos en un LLM es pocas veces viable debido a restricciones de tiempo de cómputo, costos y capacidad del modelo para mantener contexto a largo plazo. La cuestión del costo es esencial. El uso extensivo de LLMs puede implicar gastos muy elevados derivados del consumo computacional y el acceso a APIs pagas.
Además, estos procesos no suelen contar con garantías absolutas de precisión; los LLMs pueden incurrir en errores conocidos como alucinaciones, donde generan información incorrecta o imprecisa que puede comprometer la confianza en los resultados. Este factor es especialmente crítico en sectores regulados, como finanzas o derecho, donde la precisión y la trazabilidad son fundamentales. Otra limitación radica en la ventana de contexto que los LLMs pueden manejar efectivamente. Aunque estos modelos están mejorando constantemente, la mayoría tienen límites en la cantidad de texto que pueden procesar en una sola operación—lo que dificulta trabajar con documentos extensos o con un gran número de campos a extraer. Para superar esta limitación, se requieren enfoques complementarios, como técnicas de recuperación y generación (Retrieval-Augmented Generation, RAG) y pipelines que segmenten y recombinen la información de manera inteligente, lo que añade complejidad adicional a la solución global.
En cuanto a la integración, las pilas tecnológicas actuales están muy optimizadas para datos estructurados, con sistemas robustos de bases de datos, herramientas ETL y ecosistemas bien desarrollados que facilitan la manipulación, transformación y análisis. Los LLMs, aunque potentes como un nuevo tipo de “CPU de procesamiento de lenguaje”, aún necesitan trabajar como un puente entre estos sistemas y los datos no estructurados. Esto significa que se vuelve necesario un ecosistema híbrido donde los LLMs faciliten la interpretación inicial y mapeo de esos datos a esquemas estructurados, permitiendo así que el resto de la infraestructura ya asentada gestione el procesamiento a gran escala. Dentro de este contexto surge el concepto de “mapeo de esquemas” como uno de los mayores desafíos. No basta con que un LLM comprenda un documento; es indispensable que convierta la información en un esquema común, consistente y uniforme que permita realizar consultas, análisis y automatizaciones posteriores.
Las variaciones ilimitadas en formatos de documentos, desde contratos hasta facturas o reportes, implican que el sistema debe ser extremadamente flexible y capaz de manejar lógica comercial compleja para interpretar correctamente los datos. Este proceso requiere gran expertise y un entorno especializado que facilite la creación y ajuste de tales mappings, con herramientas que permitan probar, comparar y depurar resultados sin sacrificar la eficiencia ni la precisión. El entorno humano-computadora es otro factor crítico. A pesar de los avances en automatización, para muchas tareas complejas aún es necesario mantener un componente de supervisión humana, especialmente cuando se trabaja con documentos sensibles o con alta complejidad semántica. Integrar a los humanos en el ciclo, de forma eficiente y práctica, mediante interfaces que permitan revisar, corregir y validar los resultados, es fundamental para mantener la calidad y cumplir con regulaciones legales o políticas internas.
Las tecnologías como el “source document highlighting” o el uso de sistemas duales que contrastan resultados para reducir errores (como la técnica LLMChallenge que utiliza dos modelos para validar las extracciones) son reflejo de la madurez necesaria para poder escalar estas soluciones con confianza. También es importante abordar las tecnologías incumbentes como OCR, NLP tradicional y otros métodos de procesamiento de documentos. Estos métodos, aunque con limitaciones evidentes frente a la complejidad máxima, siguen siendo altamente eficientes y económicos para casos simples o de baja variabilidad, donde la estructura y el contenido siguen patrones reconocibles. Por ello, soluciones basadas exclusivamente en LLMs podrían no ser necesarias o costo-efectivas cuando las alternativas actuales funcionan adecuadamente. Sin embargo, en el extremo opuesto del espectro, para documentos de gran complejidad, con múltiples variantes, lenguaje legal o técnico, formatos no estandarizados y alto volumen, los LLMs abren oportunidades reales para automatizar labores complejas que antes solo podían ser realizadas manualmente por expertos humanos.
En estos casos, el retorno de inversión se justifica, proliferan las innovaciones y la integración de sistemas nativos basados en LLM adquiere sentido. Un punto especialmente prometedor en esta evolución tecnológica son los modelos de visión integrados con capacidades de lenguaje que están emergiendo rápidamente. A diferencia de los procesos actuales, que requieren primero extraer el texto mediante OCR para luego procesarlo con un LLM, las futuras generaciones de modelos multimodales serán capaces de interpretar directamente imágenes, formularios complejos, manuscritos, cuadros, checkboxes y otros elementos visuales complejos sin intermediarios. Este avance potencial puede simplificar enormemente las cadenas de procesamiento y abrir nuevas fronteras para la automatización precisa y eficiente. En resumen, aunque los Modelos de Lenguaje Grandes aportan capacidades avanzadas para entender y procesar datos no estructurados, aún están lejos de ser la bala de plata que resuelva de forma definitiva todos los desafíos que plantea este tipo de información.
Su utilización requiere arquitecturas híbridas que combinen lo mejor de tecnologías tradicionales y emergentes, un enfoque cuidadoso en el mapeo y la estandarización de esquemas, y una integración inteligente de la supervisión humana para asegurar la calidad y confianza. El futuro apunta hacia una convergencia tecnológica en la que LLMs y modelos de visión trabajarían de forma conjunta, complementados por herramientas especializadas que permitan enfrentar escenarios reales con grandes volúmenes y alta variabilidad. Para los negocios que dependen fuertemente de la gestión de documentos complejos, entender estas dinámicas y evaluar cuidadosamente cuándo y cómo incorporar estas tecnologías será clave para transformar sus procesos y mantenerse competitivos en la era digital.