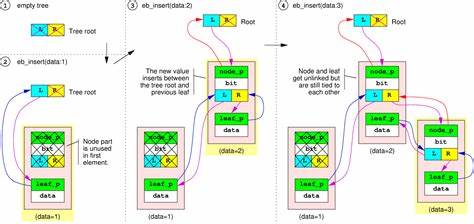
Los Compact Elastic Binary Trees, conocidos como Cebtree, representan una evolución significativa en la manera en que gestionamos y organizamos datos dentro de árboles binarios. Desarrollados originalmente a partir de los Elastic Binary Trees (ebtrees), el objetivo principal de Cebtree es ofrecer una estructura mucho más compacta y eficiente que permita manejar grandes volúmenes de información con un consumo de memoria reducido sin perder un rendimiento aceptable en las operaciones básicas de inserción, búsqueda y eliminación. La historia del desarrollo de Cebtree arranca en 2007 con la creación inicial de los ebtrees, donde se experimentó con estructuras autororganizadas capaces de manejar duplicados en los nodos. Una de las observaciones claves fue que para insertar, eliminar o recorrer nodos, sólo resultaba necesario conocer el punto de reinicio o dónde atar un nuevo nodo sin requerir referencias hacia arriba en el árbol. Esta característica facilitó la reflexión sobre la posibilidad de diseñar una estructura que no dependiera de guardar la profundidad o la relación entre la profundidad del nodo y la clave que transporta.
En este sentido, la técnica involucraba medir la profundidad de la penúltima rama para mantener el equilibrio ante nuevos duplicados insertados en secuencia. Una idea pionera fue el uso del operador XOR para optimizar la búsqueda en el árbol. Aproximadamente 18 meses después de los primeros experimentos surgió la intuición de que la comparación mediante XOR entre la clave buscada y la clave del nodo, y entre las ramas hijas, era suficiente para descubrir si el nodo buscado se hallaba en una rama o si ya se había alcanzado una hoja. Más concretamente, si el XOR entre las dos ramas hijos era mayor que el XOR entre la llave buscada y el nodo actual, se tenía la certeza de que el resultado no se encontraba bajo ese nodo, lo que permitió eliminar la necesidad de almacenar la profundidad en cada nodo y reducir el espacio utilizado. Estas ideas se plasmaron en implementaciones limitadas en 2014 durante el desarrollo de un asignador de memoria compacto denominado "water drop alloc" o "wdalloc".
Aquí, Cebtree se utilizó para indexar punteros de memoria como claves en lugar de almacenar claves explícitas, facilitando la gestión de bloques libres y fusionando espacios adyacentes mediante búsquedas sencillas. Una gran ventaja en esta aplicación fue el uso exclusivo de dos punteros por nodo, lo que implicaba un ahorro considerable de espacio en memoria frente a otras estructuras usadas comúnmente, que a menudo superaban los 40 bytes por nodo en arquitecturas de 64 bits. Sin embargo, este ahorro de memoria vino a costa de una reducción en el rendimiento de las operaciones de asignación y liberación, además de problemas de escalabilidad con accesos concurrentes en entornos multihilo. Tras varios intentos y periodos de pausa, en 2023 se decidió comenzar un proyecto desde cero para Cebtree, ignorando inicialmente la complejidad de gestionar claves duplicadas y dejando de lado algunas optimizaciones avanzadas. Este reinicio estuvo marcado por la intención de mantener un código más simple y modular, tratando de disminuir la carga de mantenimiento.
Se logró una versión inicial (v0.1) que ya podía ser utilizada para diferentes tipos de claves, excepto para clave duplicada, con una mejora clara en la compactación respecto a los ebtrees clásicos. Una de las aplicaciones prácticas más relevantes de Cebtree en su versión inicial fue su integración en HAProxy 3.1, donde el índice de variables pasó de estructuras lineales a Cebtree, logrando una mejora del 37% en rendimiento sin aumentar la memoria consumida, especialmente con configuraciones que contenían grandes cantidades de variables. Pero la ausencia de soporte para claves duplicadas representaba un obstáculo para otras funcionalidades esenciales de HAProxy, como map, ACLs o temporizadores, donde las duplicidades ordenadas son un requisito fundamental.
Para ello, se retomó el trabajo en 2024, ideando un mecanismo basado en listas enlazadas entre nodos y hojas para manejar duplicados sin necesidad de almacenamiento adicional significativo ni modificar la lógica básica del árbol. La clave de esta solución fue insertar los duplicados como elementos de lista entre las hojas y los nodos originales, usando punteros inteligentes cuya estructura permite recorrer los duplicados en orden de inserción, facilitando operaciones de búsqueda, inserción y eliminación en tiempo logarítmico amortizado. Esta gestión de duplicados fue implementada en la versión 0.2 de Cebtree, considerada a partir de ese momento como una estructura completa y lista para producción en situaciones donde se requiera un balance entre memoria y rendimiento, sin sacrificar la capacidad de manejar claves idénticas. Sin embargo, Cebtree no es tan rápido como los ebtrees tradicionales en términos de rendimiento.
Esto se debe principalmente a que en cada nivel es necesario comparar dos ramas para decidir la dirección del recorrido, lo que incrementa el número de accesos a memoria. Aun así, por la reducción notable en el tamaño de los nodos, la eficiencia en términos de utilización de la caché es mucho mejor, especialmente para claves pequeñas o datos que no presentan valores extensos. Otro avance clave fue la incorporación de punteros etiquetados (tagged pointers) para las hojas, lo que permitió optimizar las comparaciones de cadenas largas. Esto se tradujo en que, en lugar de volver a comparar desde el comienzo de la cadena en cada nivel del árbol, la comparación sólo se reinicia desde el punto donde ocurrieron las divergencias, reduciendo así el tiempo promedio de búsqueda y mejorando la eficiencia para datos string con longitud considerable. Actualmente, Cebtree se encuentra en un estado funcional y estable, con pruebas funcionales y de rendimiento.
Su API se ha simplificado para dejar claro si la estructura soporta o no duplicados mediante el nombre de las funciones, eliminando la necesidad de contextos o banderas adicionales que mejoran la legibilidad del código. Respecto a la complejidad algorítmica, todas las operaciones básicas están en orden logarítmico respecto al número de elementos N, aunque ciertas operaciones como next, previous o delete requieren más pasos que en ebtrees debido a la ausencia de retroceso en el árbol y a la necesidad de mantener punteros de reinicio durante el descenso. Los desarrollos futuros para Cebtree incluyen la terminación de la documentación, una mejora en el soporte para operaciones avanzadas como el longest match típico en búsquedas de rango (importante en IPs o máscaras de red), exploraciones para incorporar operaciones atómicas adecuadas para entornos multihilo, y la inclusión de punteros relativos para permitir indexar estructuras almacenadas en archivos sin necesidad de copias innecesarias. La simplicidad de Cebtree, con nodos que contienen solamente dos punteros, abre nuevas posibilidades para implementaciones con inserciones, búsquedas y eliminaciones eficientes, incluso en arquitecturas con limitaciones estrictas de memoria. Además, la gestión de duplicados mediante listas enlazadas internas supera las dificultades de estructuras anteriores, ofreciendo un modelo claro y fácil de mantener.
Se plantea la posibilidad de unificar ebtrees y cebtrees en un solo proyecto que cubra las ventajas de ambas implementaciones, aprovechando especialmente la gestión eficiente de duplicados y la reducción del tamaño de nodos de cebtree. También se exploran conceptos de auto-bloqueo basados en estructuras similares a mt_lists, aunque se requiere un análisis más profundo para evaluar el impacto sobre el rendimiento en visitas frecuentes. La experiencia práctica y las pruebas en HAProxy con cargas reales respaldan la utilidad de Cebtree en proyectos reales, particularmente donde la reducción del consumo de memoria y una gestión correcta de cadenas o claves pequeñas sean esenciales. Aunque existen penalizaciones en ciertos casos por la comparación de claves en cada nivel, las ventajas en espacio y mantenimiento lo convierten en una opción atractiva para aplicaciones de networking, bases de datos embebidas o sistemas donde los recursos limitados son un factor crítico. Finalmente, el código fuente de Cebtree está disponible públicamente y continúa evolucionando, con la contribución de la comunidad y basado en un enfoque abierto para optimizar la estructura y adaptarla a usos futuros.
La visión de Cebtree lleva hacia árboles binarios extremadamente compactos, eficientes y fáciles de mantener, que ofrecen una interesante alternativa a las estructuras de datos tradicionales para quienes buscan optimización avanzada en memoria sin sacrificar funcionalidad. En conclusión, Compact Elastic Binary Trees representan un avance importante en el diseño de estructuras de datos binarios, combinando ideas innovadoras como el uso de XOR para navegación, optimización mediante punteros etiquetados y una gestión sencilla pero efectiva de duplicados. Su impacto en proyectos como HAProxy y la promesa de mejoras futuras consolidan a Cebtree como un referente a tener en cuenta en el ámbito del desarrollo de algoritmos y estructuras eficientes para sistemas modernos.