En un mundo donde la inteligencia artificial está revolucionando la forma en que accedemos y procesamos la información, el concepto de Recuperación Aumentada por Generación (RAG, por sus siglas en inglés) emerge como una de las tendencias más potentes para integrar grandes volúmenes de datos y ofrecer respuestas más precisas y contextualizadas. Cloudflare, conocido por sus avanzadas soluciones en seguridad, redes y servidores, ha dado un paso importante lanzando AutoRAG, un producto que busca facilitar la implementación de RAG sin necesidad de una profunda especialización técnica. Aquí ofrecemos una evaluación detallada basada en pruebas reales de AutoRAG, enfocándonos en su utilidad práctica, características técnicas, y proyecciones en el ecosistema de inteligencia artificial. Recuperación Aumentada por Generación combina lo mejor del aprendizaje automático y la búsqueda semántica para entregar respuestas a partir de datos específicos y un modelo de lenguaje. La idea central detrás de esta tecnología es que no solo se genera texto basado en patrones aprendidos en un modelo, sino que también se involucra una etapa previa de recuperación de información relevante para alimentar al generador, lo que resulta en respuestas contextualizadas y con respaldo documental.
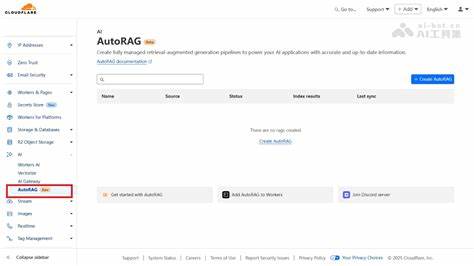
Esta propuesta resulta muy atractiva para quienes desean aprovechar bases de datos especializadas o documentos internos para obtener respuestas a preguntas complejas sin consultar manualmente enormes volúmenes de información. Cloudflare AutoRAG permite construir una aplicación RAG a partir de datasets personalizados alojados en sus sistemas, específicamente utilizando buckets en su plataforma R2 para almacenar y administrar archivos. Esto facilita a los desarrolladores y empresas probar esta tecnología con sus propios datos sin una infraestructura compleja. El proceso inicia con la carga de documentos, que son automáticamente indexados para permitir la búsqueda vectorial y la posterior generación de respuestas por parte de modelos avanzados de lenguaje. Uno de los aspectos positivos destacados por los primeros usuarios es la simplicidad y rapidez con que se puede desplegar un sistema RAG funcional.
AutoRAG viene con algunas opciones para adaptar el proceso de chunking o segmentación de documentos, algo fundamental para optimizar la recuperación de fragmentos de texto relevantes. Estas opciones contemplan el tamaño de los fragmentos y la superposición entre ellos, con valores predeterminados que funcionan bien para la mayoría de los casos, pero permiten personalización para necesidades específicas. En cuanto a los modelos de embeddings, que transforman texto en vectores para facilitar la búsqueda semántica, AutoRAG ofrece dos opciones: baai/bge-large-en-v1.5, orientado al inglés, y baai/bge-m3, que soporta múltiples idiomas. Sin embargo, se señala que las opciones son limitadas comparadas con otras ofertas en el mercado, y que la búsqueda se realiza exclusivamente mediante la métrica de distancia coseno, que si bien es estándar en búsqueda vectorial, no permite explorar otras técnicas o combinaciones más avanzadas.
Una ventaja considerable es la integración con la plataforma AI Gateway de Cloudflare, una pasarela para enrutar llamadas a modelos de lenguaje de distintos proveedores como Gemini, OpenAI, Anthropic y Mistral, aunque actualmente las llamadas se limitan a modelos LLama internamente. La elección por defecto recae en LLama 3.3 70B, un modelo potente pero que algunos consideran podría ser optimizado con alternativas como Gemma 27B para mejorar el rendimiento y costos. A nivel de configuración de recuperación, AutoRAG presenta dos variables esenciales: el número de resultados que retornará y el umbral mínimo de similitud para considerar una coincidencia válida. Además, incorpora cuatro niveles de similitud para las búsquedas: Exacta, Fuerte, Amplia y Suelta, que controlan el grado de coincidencia semántica y la cantidad de resultados obtenidos.
Sin embargo, el detalle sobre cómo están implementados estos filtros no es completamente transparente, lo que limita la comprensión del comportamiento bajo diferentes escenarios. Un elemento clave que genera satisfacción es que el sistema añade referencias visibles que indican la fuente de los datos usados para responder a una consulta, facilitando la trazabilidad y confianza en la información generada. También se aprecia la capacidad de añadir datos adicionales al bucket R2 en cualquier momento, que son automáticamente indexados para que el sistema los considere en futuras recuperaciones. Desde la perspectiva del usuario, la interfaz AI Gateway permite monitorear con claridad las consultas, prompts y contextos empleados en cada respuesta, lo que aporta transparencia y ayuda en la depuración o mejoramiento del sistema. También se hace notar que la ventana de contexto se llena con etiquetas que incluyen el nombre del documento utilizado, apoyando aun más la identificación de la fuente.
No obstante, existen aspectos aún por mejorar. Un ejemplo es la lentitud en la función de reescritura de consultas, que tarda alrededor de 1.7 segundos, un tiempo considerable para aplicaciones que demandan rapidez. Además, para que AutoRAG funcione correctamente, es indispensable que el bucket R2 tenga datos antes de crear la aplicación; de lo contrario, el sistema no opera como se espera. También falta una herramienta para optimizar prompts y algunas fallas menores que, si bien pueden atribuirse al estado beta del producto, deben resolverse para ofrecer una experiencia sólida.
En la práctica, las respuestas generadas con AutoRAG utilizando datasets especializados, como los relacionados con figuras emblemáticas de inversión Warren Buffett y Charlie Munger, resultaron satisfactorias en términos de calidad. Sin embargo, la etapa de recuperación se percibió como un área con potencial para mejoras significativas. Algunas respuestas carecían de enlaces precisos a los fragmentos más relevantes, lo que implica que la búsqueda semántica no siempre posiciona los mejores contenidos al tope. Es importante considerar que esta dificultad es común en sistemas generalistas, pues la recuperación óptima suele depender mucho de la naturaleza del dominio y los datos empleados. La utilidad práctica de AutoRAG se encuentra en facilitar pruebas rápidas para quienes quieren verificar si incorporar un enfoque RAG puede añadir valor a sus proyectos.
De esta forma, usuarios sin grandes inversiones pueden validar hipótesis con conjuntos de datos propios antes de embarcarse en desarrollos más complejos. En iniciativas innovadoras o startups, esta capacidad abre la puerta para experimentar con modelos y datos de forma ágil. Entre las características que interesaría ver para próximas versiones está la posibilidad de evaluar objetivamente la calidad de la recuperación, por ejemplo, con métricas que indiquen si el contexto utilizado fue el correcto para responder con precisión. También serían bienvenidas técnicas clásicas de búsqueda, como BM25, o la incorporación de re-rankers para refinar los resultados, aunque es posible que conforme la calidad de modelos base como GPT-4.1 mejore, la necesidad de estos componentes disminuya, como ha indicado una tendencia reciente en la industria.
Otras funcionalidades que añadirían valor son reglas personalizadas para la recuperación, que permitirían balancear diversidad y relevancia en las fuentes que alimentan la respuesta. Así, un sistema podría evitar saturar la ventana de contexto con documentos similares, favoreciendo diversidad informativa que puede enriquecer la interacción. Este tipo de personalización es clave para enfrentar desafíos reales donde los datos pueden ser heterogéneos y con distintos grados de confiabilidad. En un panorama más amplio, el posicionamiento de AutoRAG encaja bien con la estrategia de Cloudflare de ofrecer herramientas serverless que abstraen detalles complejos y permiten lanzar soluciones rápidamente. Este enfoque puede atraer a desarrolladores y empresas que priorizan la velocidad de implementación sobre un control fino en los parámetros técnicos.
La experiencia de usuario, en general, resalta por un diseño que entrega opciones suficientes sin sobrecargar, aunque con espacio para crecer y volverse más robusto. Es importante destacar una reflexión interesante observada durante pruebas paralelas. En pocos meses, la calidad de modelos como ChatGPT ha avanzado notablemente, logrando reducir errores en prompts específicos notablemente, mientras que soluciones RAG especializadas que en su momento superaban a modelos generales ahora pierden relevancia cuando los modelos base mejoran. Esto sugiere que la utilidad de RAG será cada vez más selectiva, con mayor enfoque en datasets exclusivos y propietarios que no son tan accesibles para los grandes modelos entrenados con datos públicos. En suma, Cloudflare AutoRAG representa una propuesta interesante y prometedora en la evolución de herramientas RAG accesibles y fáciles de implementar.