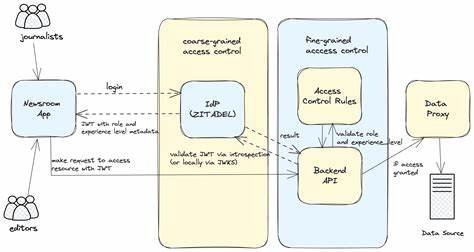
El juego de Go ha sido durante décadas un campo de batalla intelectual para el desarrollo de inteligencia artificial debido a su simplicidad en reglas pero complejidad estratégica inimaginable. Mientras la IA avanzaba, el recorrido desde las primeras aproximaciones basadas en sistemas expertos como GnuGo hasta la sofisticada inteligencia artificial de AlphaGo Zero ha marcado un camino paradigmático que ofrece un modelo aplicable para resolver otros desafíos complejos en distintas disciplinas tecnológicas. Esta exploración no solo revela cómo ha evolucionado la solución a un problema específico, sino también sostiene una analogía valiosa para ámbitos como la conducción autónoma, asistentes digitales, robótica o comprobación automatizada de teoremas, donde la incertidumbre y la vastedad del espacio de soluciones dificultan encontrar respuestas óptimas. Go, en apariencia, es un juego simple de aprender ya que se fundamenta en solo tres reglas básicas: los jugadores alternan colocando piedras en un tablero de 19 por 19; las cadenas de piedras rodeadas son capturadas y removidas; y se prohíbe repetir posiciones anteriores para evitar ciclos infinitos. Sin embargo, a pesar de su simplicidad normativa, aprender a jugar bien exige comprender sutilezas estratégicas que no emergen directamente de las reglas.
Aspectos como la importancia del balance entre separar las piedras lo suficiente para avanzar rápidamente en la ocupación del territorio y mantenerlas lo suficientemente unidas para defenderse constituyen lecciones que se aprenden con la experiencia pero que son extremadamente difíciles de formalizar para las máquinas. El camino hacia la creación de un programa capaz de jugar Go a nivel competitivo comenzó en la era de los sistemas expertos en los ochenta, con exponentes como GnuGo. Este tipo de sistemas se basa en reglas codificadas a mano, heurísticas definidas por expertos y estructuras de decisión cuidadosamente diseñadas para abordar aspectos específicos del juego, como invasiones o capturas. Aunque conceptualmente atractivos y con cierta capacidad para jugar a niveles bajos, este enfoque estaba limitado por su incapacidad para captar el panorama global del tablero y su tendencia a tomar decisiones en absolutos rígidos sin matices necesarios para afrontar las sutilezas estratégicas que Go presenta. En palabras simples, los sistemas expertos trataban el Go como un conjunto de condiciones determinísticas, y por ello nunca alcanzaron más allá del nivel básico del jugador humano casual.
El mayor problema con los sistemas expertos residía en la dificultad para manejar toda la complejidad del tablero, dado que cada módulo o conjunto de reglas estaba orientado a situaciones locales sin considerar suficientemente las interdependencias globales. Además, la naturaleza estática y manual de las reglas impedía adaptaciones dinámicas o el aprendizaje a partir de la experiencia, dos características esenciales para abordar problemas con espacios tan vastos y variables como el Go. Con la llegada de la Computación Estadística y la reducción de costos en potencia de cálculo, emergió una nueva metodología en la década de 2000: la Búsqueda de Árbol Monte Carlo (Monte-Carlo Tree Search - MCTS). Este método revolucionó la forma de aproximarse al problema, reemplazando la fragmentación en módulos por una única estrategia probabilística que exploraba selectivamente las ramas más prometedoras del árbol de juego. Usando simulaciones aleatorias para estimar el valor de posiciones hasta estados de juego terminal, la técnica consiguió un equilibrio entre exploración y explotación que propició una búsqueda amplia y profunda del espacio de posibles movimientos.
Este avance permitió superar algunas limitaciones notables de los sistemas expertos, dejando atrás la dependencia de reglas rígidas y abiertas a sesgos humanos, y abrió la puerta a una evaluación basada en la estadística y la probabilidad. No obstante, MCTS aún tenía sus puntos débiles, especialmente en posiciones tácticas complejas donde los procesos de simulación basados en movimientos aleatorios con heurísticas superficiales generaban evaluaciones poco confiables. Sin embargo, en términos generales, MCTS permitió que programas de Go ascendieran significativamente en el ranking de jugadores humanos, llegando a niveles competitivos mucho más altos que sus predecesores. La siguiente gran etapa fue impulsada por las redes neuronales profundas, que comenzaron a ganar terreno en inteligencia artificial debido a su capacidad para identificar patrones complejos sin intervención humana directa. En el contexto de Go, se utilizaron redes neuronales convolucionales para aprender directamente de datos de partidas profesionales, generando heurísticas de juego mucho más sofisticadas.
Las redes neuronales demostraron poder jugar con una calidad cercana a la de jugadores humanos expertos incluso sin realizar búsqueda, mostrando que la capacidad de generalización y reconocimiento de patrones de estas redes era un recurso muy potente para abordar un problema tradicionalmente tan difícil. AlphaGo, el emblemático proyecto de DeepMind, fusionó estas redes neuronales con técnicas de búsqueda como MCTS, incorporando tres redes especializadas para proponer movimientos, evaluar posiciones y controlar simulaciones rápidas. Este sistema mostró un estilo de juego sorprendentemente humano e incluso estético, capaz de realizar intercambios de gran complejidad y de revisar evaluaciones en cada posición. La combinación de aprendizaje supervisado a partir de partidas humanas con una búsqueda computacional intensiva contribuyó a un rendimiento que ningún programa anterior había alcanzado, incluido el histórico triunfo de AlphaGo sobre Lee Sedol en 2016. Sin embargo, AlphaGo seguía dependiendo en gran medida de datos procedentes de expertos humanos y de un costoso uso de recursos computacionales: más de 700 GPUs para ejecutar partidas y entrenamientos.
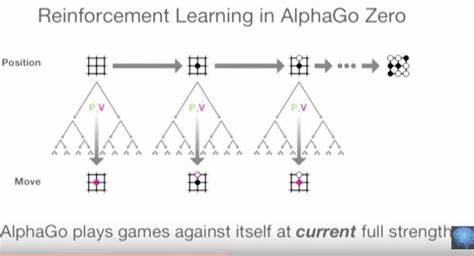
La ambición por superar estas barreras condujo al desarrollo de AlphaGo Zero, un salto cualitativo sustancial que eliminó la necesidad de conocimiento humano previo. AlphaGo Zero aprendía exclusivamente desde el juego aleatorio —al principio puramente azaroso— evolucionando mediante un bucle de autoaprendizaje por refuerzo. El enfoque de AlphaGo Zero se basó en una integración completa del aprendizaje profundo y la búsqueda de árbol. Al generar su propio conjunto infinito de datos mediante partidas de autoentrenamiento, mejoró progresivamente sus redes neuronales de política y valor sin depender de supervisión externa. Los resultados fueron asombrosos: su red de política sin búsqueda ya jugaba por encima del 99% de los jugadores humanos y el sistema completo alcanzó una fuerza competitiva superhumana, con una diferencia de más de 1000 puntos Elo sobre los mejores profesionales del mundo.
Más allá de su impacto en Go, esta evolución representa una hoja de ruta crucial para resolver problemas con propiedades similares a las del juego, caracterizados por especificaciones imprecisas y inmensos espacios de soluciones posibles. La clave está en comenzar con métodos simples posiblemente basados en reglas y búsqueda exhaustiva apoyada en heurísticas manuales, pasar a métodos que combinan búsqueda y heurísticas aprendidas automáticamente, refinar iterativamente estos componentes para crear ciclos de mejora, y finalmente automatizar todo el proceso a través de aprendizaje por refuerzo que puede explotar su propio poder computacional para descubrir soluciones inesperadamente efectivas. Una enseñanza fundamental de esta historia es que tratar de saltar directamente a la técnica más avanzada, como el aprendizaje por refuerzo profundo, sin contar con una base sólida y detallada infraestructura, resulta muchas veces inefectivo y hasta contraproducente. La experiencia práctica demuestra que la construcción paso a paso, la creación de herramientas de monitoreo precisas, el diagnóstico frecuente de errores y la validación constante de los objetivos son esenciales para construir sistemas robustos y escalables. Estas reflexiones tienen mucho que ofrecer a los proyectos actuales en inteligencia artificial, donde la presión para integrar soluciones novedosas puede conducir a expectativas poco realistas.
La combinación de búsqueda intensiva, aprendizaje supervisado a partir de expertos, mejoras iterativas mediante ciclos que alternan aprendizaje y optimización, y finalmente el despliegue de aprendizaje autónomo brindan una aproximación metodológica que, aunque laboriosa, resulta mucho más efectiva y sostenible. En síntesis, la evolución de la inteligencia artificial en Go no solo refleja avances técnicos revolucionarios, sino que también invita a adoptar una mentalidad pragmática y escalonada para enfrentar complejidades similares en campos tan diversos como la navegación autónoma, los asistentes digitales inteligentes o la robótica avanzada. El camino desde GnuGo hasta AlphaGo Zero es un testimonio claro de que el éxito en problemas difíciles depende tanto de la innovación en técnicas fundamentales como de la paciencia para construir infraestructuras estables que faciliten su aplicación real, sin atajos ni ilusiones fáciles. Este legado sigue inspirando y guiando nuevas fronteras en la inteligencia artificial aplicada.