En el mundo del aprendizaje automático y las redes neuronales, la búsqueda constante por modelos que sean a la vez potentes y eficientes ha llevado a desarrollos innovadores como la arquitectura Mixtura de Expertos con Puertas Dispersas, conocida en inglés como Sparsely-Gated Mixture of Experts (MoE). Esta técnica representa un avance significativo en el diseño de modelos transformadores, utilizados ampliamente en procesamiento de lenguaje natural, visión por computadora y otras áreas. Su éxito radica en combinar la capacidad de grandes modelos con un uso selectivo y eficiente de los recursos computacionales, optimizando tanto el rendimiento como el costo durante el entrenamiento y la inferencia. Los modelos transformadores se componen principalmente de bloques de atención y capas feed-forward, siendo estas últimas las que usualmente contienen la mayoría de los pesos del modelo debido a la gran dimensión oculta que poseen. En estos bloques feed-forward, una red neuronal simple con una capa oculta realiza transformaciones en los vectores de entrada, enriqueciendo la representación de los datos antes de ser procesados nuevamente por la red.
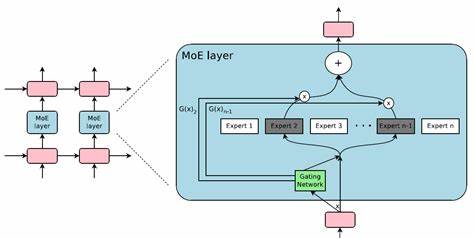
La dimensión oculta suele ser cuatro veces mayor que la dimensión de la representación de los vectores, lo que implica una gran cantidad de parámetros y, consecuentemente, una considerable carga computacional. La arquitectura MoE propone dividir esta capa feed-forward en múltiples bloques independientes conocidos como expertos. Cada uno de estos expertos funciona como una subred especializada encargada de procesar una parte del input, pero lo que diferencia esta técnica es la inclusión de un sistema de enrutamiento, o gate, que decide dinámicamente qué expertos deben procesar cada token de entrada. El gate actúa como un filtro inteligente: recibe cada vector de entrada y asigna una puntuación a cada experto mediante un cálculo lineal con pesos entrenables. Solo los expertos con las puntuaciones más altas para ese token específico participan en el procesamiento, generalmente dos o tres, dependiendo de la configuración.
Este mecanismo resulta en que la mayoría de los expertos permanecen inactivos para ese token, reduciendo significativamente la cantidad de cálculos realizados sin comprometer la capacidad global del modelo. Una vez que se seleccionan los expertos para un token, el vector es enviado a cada uno de ellos. Los resultados se ponderan según las puntuaciones del gate, normalizadas mediante una función softmax para asegurar que la suma de ponderaciones sea uno. Finalmente, las salidas de esos expertos ponderadas se combinan para producir la representación procesada final del token. Esta operación se realiza para cada token en el lote y la secuencia, lo que implica un procesamiento altamente paralelo aunque con patrones de sparsidad que desafían la vectorización tradicional.
La implementación de MoE conlleva retos técnicos, especialmente en la optimización del procesamiento de datos divididos entre expertos diferentes. Debido a que cada token puede activar distintos expertos, agrupar las operaciones para maximizar la eficiencia en hardware como GPUs es complejo. Sin embargo, han surgido técnicas y estudios que abordan este problema, como las propuestas de MegaBlocks, que optimizan el trabajo disperso mediante estructuras y algoritmos especializados. Además de la eficiencia, un aspecto crucial de MoE es el balance de carga entre expertos. Sin una adecuada regulación, el modelo podría aprender una preferencia por ciertos expertos, dejando a otros subutilizados y desaprovechando parte de la capacidad del modelo.
Para evitarlo, se implementan estrategias tales como la introducción de ruido en el proceso de selección y la incorporación de términos de pérdida que incentivan que la distribución de tokens a través de expertos sea más uniforme. Esta arquitectura no solo aumenta la potencia del modelo sino que mantiene la demanda computacional bajo control, permitiendo entrenar modelos con cientos de miles de millones de parámetros que de otro modo serían inaccesibles. Ejemplos emblemáticos de modelos que emplean MoE incluyen variantes que multiplican la cantidad de parámetros hasta por ocho sin que el costo de inferencia se incremente en la misma proporción. Desde una perspectiva conceptual, cada experto puede especializarse en ciertos patrones o tareas. Aunque en la práctica la especialización no es estrictamente definida, esta diversidad permite al modelo adaptarse a una amplia variedad de contextos y tipos de datos.




![Gigapixels of Andromeda [4K] [video]](/images/CC3F7629-85AB-4DF5-880A-2BCAE5825179)

