En el mundo de las bases de datos, el rendimiento de las consultas es fundamental para garantizar que las aplicaciones funcionen de manera eficiente y rápida. Una de las herramientas clave para mejorar este rendimiento es la indexación, que permite acceder a los datos de manera acelerada. Dentro de esta práctica, surge una pregunta frecuente y crítica: ¿es mejor crear índices separados para cada columna de un filtro o un solo índice compuesto que abarque múltiples columnas? Ambos enfoques tienen implicaciones distintas en cuanto a eficiencia, mantenimiento y escalabilidad. Entender cuándo y cómo utilizar cada uno es vital para dominar la optimización en SQL. Los índices en SQL funcionan como una especie de diccionario para la base de datos, facilitando la localización rápida de filas específicas sin necesidad de analizar toda la tabla.
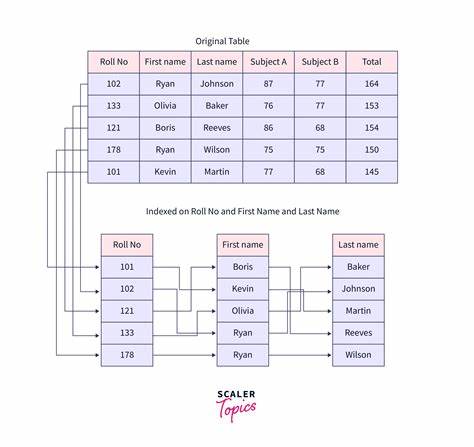
Cuando se trabaja con consultas que filtran los resultados usando varias columnas, la decisión sobre cómo indexar puede tener un gran impacto. Un índice separado significa que cada columna involucrada en las condiciones WHERE cuenta con su propio índice individual, mientras que un índice compuesto contiene todas estas columnas concatenadas en un único índice. Los índices compuestos están diseñados para aprovechar las consultas que filtran por múltiples columnas de manera conjunta. Por ejemplo, si una consulta busca registros según el apellido y fecha de nacimiento, un índice compuesto que incluya ambos campos concatenados será más eficaz cuando las condiciones estén presentes simultáneamente. Esta estructura permite que el motor de la base de datos recorra un solo árbol de índices, accediendo rápidamente a las entradas que coinciden con la combinación definida, lo que reduce el tiempo de búsqueda.
Sin embargo, la efectividad de un índice compuesto depende en gran medida del orden de las columnas dentro del índice. Generalmente, se recomienda colocar la columna más selectiva primero, es decir, aquella que filtra una mayor cantidad de datos, para que el acceso sea lo más restringido posible desde el principio. Esto permite que la base de datos use el índice para aplicar acceso directo en la primera columna y, si es necesario, aplique un filtro con la segunda. Aunque esta práctica está muy extendida, es importante entender que tiene excepciones y que el rendimiento final también dependerá del tipo de consulta que se realiza. Por otro lado, existen escenarios donde un índice compuesto no puede optimizar adecuadamente.
Especialmente, las consultas que involucran condiciones de rango independientes en múltiples columnas presentan un problema. Debido a la naturaleza de los índices B-tree, que funcionan como listas enlazadas ordenadas, solo pueden aprovechar eficazmente un rango en orden secuencial. Por ejemplo, una consulta que filtra por "apellido anterior a una letra específica" y "fecha de nacimiento menor que cierta fecha" no puede utilizar los dos rangos simultáneamente en un índice compuesto, porque el índice solo puede ordenar y recorrer eficientemente según una dimensión. En estos casos, los índices separados pueden ser una alternativa. La base de datos puede entonces realizar indirectamente un cruce o fusión de los resultados de dos índices individuales.
Aunque conceptualmente esto parece viable, en la práctica implica un costo adicional significativo. El motor de base de datos debe recorrer dos árboles de índices, consumir más memoria y realizar cálculos adicionales para combinar las entradas coincidentes, lo que puede traducirse en un aumento notable del tiempo de procesamiento. Algunas bases de datos aplican técnicas como el "index join" para combinar resultados de varios índices; esta funcionalidad puede mejorar la situación, pero igualmente conlleva un esfuerzo extra comparado con recorrer un solo índice compuesto. Además, el consumo de recursos puede ser elevado, especialmente si los conjuntos intermedios son grandes o si la consulta es muy compleja. Una solución especializada utilizada especialmente en entornos de almacenamiento de datos, como los data warehouses, son los índices bitmap.
Estos índices indican la existencia o ausencia de valores mediante bits, lo que permite combinaciones rápidas y eficientes mediante operaciones lógicas. La ventaja es que cada columna tiene su propio índice bitmap y todos se pueden concatenar rápidamente, dando buenos tiempos de respuesta para consultas con múltiples condiciones. Sin embargo, los índices bitmap tienen una gran limitación: su baja escalabilidad en operaciones de escritura. Los procesos de inserción, actualización y eliminación son lentos y problemáticos, haciendo que sean inapropiados en sistemas transaccionales con mucha concurrencia. Por eso, su uso se restringe principalmente a sistemas de consulta masiva con poca modificación de datos.
Para contrarrestar las limitaciones de los índices bitmap en sistemas OLTP, algunos motores modernos emplean estructuras híbridas. Estas convierten temporalmente los resultados de múltiples índices B-tree en mapas bitmap en memoria para realizar combinaciones rápidos dentro de una consulta. De este modo, se aprovechan los beneficios de la combinación bitmap sin incidir en la desventaja del pobre rendimiento en escritura. Esta estrategia permanece solo durante la ejecución de la consulta y desaparece después, sin almacenar la estructura permanentemente. Aunque es útil, esta técnica consume recursos significativos y debe considerarse un recurso de último recurso para el optimizador.
Al decidir entre índices compuestos o separados, no existe una regla universal que aplique para todas las bases de datos o escenarios. Lo recomendable es analizar las consultas más frecuentes y los patrones de acceso a los datos. Si las consultas suelen filtrar por varias columnas simultáneamente y en un orden lógico, un índice compuesto es la mejor opción para acelerar la búsqueda. Por el contrario, cuando las consultas utilizan filtros con condiciones independientes y variables o múltiples rangos, los índices separados acompañados de técnicas de combinación pueden ser más adecuados, aunque siempre con un costo de rendimiento adicional. Finalmente, la creación de índices debe balancear la mejora en la velocidad de lectura con el impacto en la escritura y el almacenamiento.
Más índices significan también más espacio en disco y mayor tiempo requerido para actualizar los índices durante las modificaciones de los datos. Conocer las capacidades específicas del sistema gestor de base de datos que se utiliza es fundamental, ya que cada uno tiene implementaciones y optimizaciones propias que pueden inclinar la balanza hacia un tipo de índice o el otro. En resumen, una estrategia inteligente de indexación en SQL considera la naturaleza de las consultas, el tipo de operaciones que predomina (lectura vs escritura), las características del motor de base de datos y la calidad de los datos. La flexibilidad para combinar índices compuestos y separados, junto con la comprensión de sus ventajas y limitaciones, permitirá maximizar el rendimiento y obtener un sistema ágil y robusto.