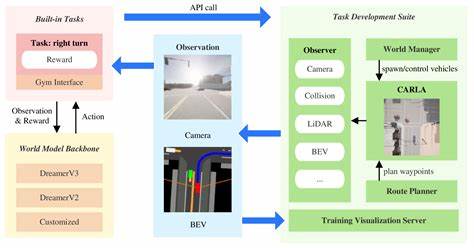
En la era de la tecnología, la conducción autónoma ha emergido como uno de los campos más fascinantes y desafiantes. Con la ambición de crear vehículos capaces de desplazarse con total independencia, la investigación no ha dejado de avanzar. Un desarrollo reciente que ha captado la atención es el concepto de "Aprender a conducir a partir de un modelo del mundo". Esta metodología representa un cambio paradigmático en la manera de abordar el entrenamiento de políticas de conducción autónoma, incorporando simulaciones basadas en datos reales para perfeccionar el rendimiento en escenarios complejos y variados. La conducción autónoma tradicional se ha apoyado durante años en algoritmos con reglas codificadas rígidas y características diseñadas artesanalmente.
Sin embargo, esta aproximación resulta limitada, ya que las situaciones reales y dinámicas del tráfico superan la capacidad de anticipación de modelos basados exclusivamente en normas predefinidas. En cambio, los modelos de aprendizaje profundo y el aprendizaje por experiencia empiezan a dominar, facilitando que las máquinas aprendan de manera similar a los humanos: observando, experimentando y adaptándose continuamente. Un reto fundamental en esta transición reside en la forma de entrenar estas políticas de conducción. En el aprendizaje supervisado convencional, los modelos se nutren de ejemplos etiquetados y aprenden a replicar un comportamiento específico bajo la suposición de que las observaciones de entrenamiento y las del mundo real son independientes e idénticamente distribuidas. En el contexto de la conducción, esta hipótesis no se cumple, dado que las decisiones actuales afectan directamente las situaciones futuras que el vehículo enfrentará.
Los errores pequeños tienden a acumularse, desviando la trayectoria del vehículo de manera irreversible si no se corrigen a tiempo. Debido a estas limitaciones, surge la necesidad de entrenar las políticas "en línea" o de forma "on-policy", donde el modelo aprende de sus propias acciones e interacciones con el entorno. Sin embargo, llevar a cabo este aprendizaje directamente en condiciones reales se torna costoso, riesgoso y poco práctico. Aquí es donde los simuladores juegan un papel trascendental, permitiendo replicar entornos diversos y desafiantes sin peligro real y optimizando la generación de experiencia para el entrenamiento continuado. Los simuladores clásicos suelen basarse en la reproyección de imágenes, donde, mediante mapas de profundidad detallados y poses en seis grados de libertad, se generan nuevas vistas a partir de imágenes previas.
Esta técnica, conocida como simulación reproyectiva, ha sido efectiva para ciertas aplicaciones y se ha implementado en sistemas reales, como algunos lanzamientos del software openpilot. No obstante, presenta limitaciones notables, tales como la suposición de un escenario estático que no contempla la reacción de otros conductores o elementos dinámicos del entorno. También enfrenta desafíos en cuanto a artefactos visuales causados por inexactitudes en la estimación de profundidad, dificultades en el relleno de zonas ocultas y problemas derivados de reflejos o cambios de iluminación, especialmente en condiciones nocturnas. Además, para evitar artefactos que comprometan la calidad y veracidad de la simulación, la simulación reproyectiva suele limitar las distancias de movimiento simuladas a pocos metros. Este factor restringe la capacidad del modelo para ensayar maniobras más complejas o prever escenarios a mediano y largo plazo.
También existe el problema del aprendizaje por atajos, en el cual la red neuronal se beneficia de señales visuales no intencionadas que revelan pistas sobre la acción futura, perjudicando la generalización y la robustez del modelo en entornos reales. Ante estas limitaciones, la investigación se ha orientado hacia modelos del mundo basados en datos, que adoptan un enfoque generativo capaz de predecir estados futuros a partir de un historial de estados y acciones pasadas. Estos modelos representan el estado del entorno mediante una representación latente de menor dimensión, obtenida a través de una red compresora, y predicen la dinámica del entorno dentro de ese espacio latente con modelos adaptados, como transformadores de difusión. El sistema actual utiliza una combinación de modelos de autoencoder variacional estable y un transformador de difusión para video, lo que garantiza una generación de imágenes más fiel y detallada. Además, incorpora un componente denominado "Plan Head", encargado de predecir la trayectoria ideal con base en el estado actual.
Esta adición facilita que el modelo del mundo pueda proporcionar además la acción óptima, es decir, la curvatura y aceleración ideales dada la situación. Un desafío inicial con los modelos del mundo es que entrenarlos únicamente con información histórica no permite que "recuperen" ante errores o desviaciones, reproduciendo la problemática del entrenamiento fuera de política. Para contrarrestar este déficit, la técnica de "anclaje futuro" se incorpora, entregando al modelo información sobre estados futuros en un tiempo fijo hacia adelante. Esta estrategia permite que, incluso si el modelo comete errores en sus predicciones actuales, pueda corregirse gradualmente y converger hacia el estado futuro esperado, mejorando la estabilidad y realismo de la simulación. Este enfoque es revolucionario porque facilita simular despliegues complejos mediante comandos específicos, como desviaciones laterales o maniobras de cambio de carril.
La simulación puede producir imágenes con alta fidelidad que respetan esas órdenes y evoluciona hacia el anclaje futuro previsto, reflejando una robustez notable que los simuladores tradicionales no alcanzan. En cuanto al entrenamiento de políticas de conducción, ambos tipos de simuladores, tanto reproyectivos como basados en modelos del mundo, se emplean conjuntamente en un esquema on-policy de aprendizaje. Con arquitecturas distribuidas y asincrónicas para la recolección de datos y la actualización de modelos, similares a métodos como IMPALA o GORILA, se consigue optimizar el uso de recursos computacionales y acelerar el proceso de entrenamiento. Uno de los beneficios más apreciados del entrenamiento con modelos del mundo es que la simulación es completamente de extremo a extremo y generalista, adaptándose mediante el aumento de capacidad computacional y datos, a entornos cada vez más variados y complejos. Esta característica abre la puerta para que las políticas aprendan comportamientos refinados en condiciones que serían difíciles o inseguras de replicar en el mundo real.
Los resultados prácticos de esta investigación ya se ven reflejados en sistemas implementados comercialmente, como el software openpilot, que emplea estas políticas para planificar tanto movimientos laterales como longitudinales con un desempeño sobresaliente en entornos reales. Esto representa un paso concreto e importante hacia la conducción autónoma confiable y escalable. Para concluir, la combinación innovadora de simuladores basados en modelos del mundo, técnicas avanzadas de aprendizaje profundo y estrategias de entrenamiento on-policy marca un cambio importante en la forma en la que las máquinas aprenden a conducir. Al superar los límites de métodos anteriores y aprovechar el poder de la simulación generativa anclada en estados futuros, se abre una nueva era para la inteligencia artificial aplicada a la movilidad autónoma, que promete mayor seguridad, eficiencia y adaptabilidad en el futuro del transporte.