Google Chrome ha dado un gran paso adelante con la implementación de su nuevo modelo de embeddings para texto. Esta actualización revolucionaria pone en evidencia cómo la innovación en inteligencia artificial y machine learning puede fusionarse con la experiencia de navegación cotidiana, optimizando recursos y mejorando el rendimiento sin sacrificar la calidad. La evolución del modelo de embeddings en Chrome no solo representa un avance técnico sino que también impulsa beneficios directos para los usuarios que dependen del navegador para gestionar su historial y realizar consultas semánticas complejas. El núcleo del cambio reside en una reducción asombrosa del tamaño del modelo. La versión más reciente ocupa apenas 35.
14MB, una disminución del 57% en comparación con la versión anterior, que pesaba 81.91MB. Esta optimización fue posible gracias a la aplicación de técnicas avanzadas de cuantización que transforman la matriz de embeddings de precisión float32 a int8 sin incurrir en pérdida detectable de calidad. En términos prácticos, este ajuste significa una gran liberación de espacio en los dispositivos que alojan el navegador, algo especialmente valorado en smartphones y tablets con limitaciones de almacenamiento. El proceso de cuantización aplicado es una muestra clara del enfoque selectivo y estratégico que ha adoptado Google para mejorar su tecnología.
En lugar de cuantizar de forma indiscriminada todos los elementos del modelo, los ingenieros centraron sus esfuerzos en la matriz de embeddings, un componente que representa la mayor carga en términos de memoria. Esta matriz, responsable de almacenar las representaciones vectoriales de tokens, fue convertida de float32 a int8, reduciendo su tamaño de 62.75MB a 15.69MB. Sorprendentemente, esta depreciación no afectó la precisión ni la calidad del modelo, lo que marca una diferencia notable respecto a intentos anteriores de compresión que solían sacrificar desempeño.
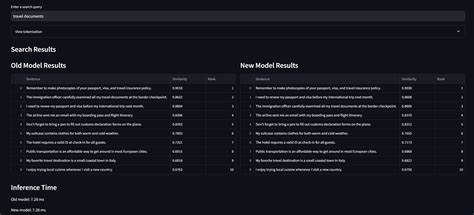
El mantenimiento de la calidad en las búsquedas semánticas fue verificado mediante una metodología exhaustiva que incluyó análisis de arquitectura, comparación binaria, evaluación de cuantización y pruebas de precisión de salida. La arquitectura del modelo permanece intacta, con características idénticas en cuanto a tensores y dimensiones de entrada y salida, apoyando la hipótesis de que ambos modelos derivan de una base común, presumiblemente un modelo basado en transformadores similar a BERT. En cuanto a la precisión de los embeddings generados por el modelo, los resultados mostraron una mejora sorprendente: el nuevo modelo alcanzó una precisión efectiva estimada en 25.42 bits, superando la versión anterior que estaba alrededor de 22.59 bits.
Este incremento involucra técnicas de entrenamiento específicas para cuantización, que permitieron conservar y hasta potencialmente mejorar la integridad de las representaciones vectoriales pese a la reducción en la precisión interna. Para el usuario, esto significa que las búsquedas basadas en el modelo mantienen la calidad y relevancia ya conocidas, con diferencias de similitud insignificantes entre versiones y un ranking de resultados que permanece constante. El impacto en el rendimiento también es positivo. El nuevo modelo no solo es sustancialmente más pequeño, sino que además ofrece un leve incremento en velocidad de inferencia, entre un 1 y 2 por ciento más rápido que su predecesor. Aunque esta mejora pueda parecer modesta en términos porcentuales, en el contexto del navegador, donde cada milisegundo cuenta, representa un avance significativo en la fluidez de funciones que dependen de la inteligencia artificial.
Aplicaciones como la búsqueda del historial y el agrupamiento de contenido semántico se benefician directamente de esta rapidez. Desde un punto de vista técnico, el análisis binario de ambos modelos reveló dinámicas interesantes sobre cómo se gestionan los datos internamente. La reducción del 60% en bytes int8 que contienen ceros equilibra con un aumento del 48.5% en bytes float32 nulos, lo que sugiere una reestructuración inteligente y diferente en la manera en que el modelo almacena la información. La cantidad de ejecuciones (runs) de ceros incrementó un 53.
3%, indicando una estrategia de almacenamiento más eficiente que aprovecha la estructura de datos escasamente poblados para mejorar la compresión. Esto contribuye a una reducción drástica en el tamaño de los tensores float, pasando de 67.33MB a solo 5.05MB. Para los usuarios y desarrolladores que trabajan en ambientes donde el tamaño y el rendimiento del modelo son críticos, esta actualización es un caso ejemplar de cómo hacer más con menos.
Libera espacio en dispositivos, reduce el tiempo y consumo de datos al realizar actualizaciones del navegador, y permite una experiencia más rápida y ágil, sin comprometer la precisión y calidad que se espera de una herramienta tan integral como Chrome. Otra ventaja no menos importante es la posible mejora en la eficiencia energética. El menor requerimiento computacional debido al modelo reducido puede traducirse en un consumo marginalmente menor de batería, especialmente en dispositivos móviles durante sesiones prolongadas de navegación. Esto contribuye indirectamente a una experiencia de usuario más sostenible y económica. En resumen, el nuevo modelo de embeddings de Chrome representa un paradigma de optimización inteligente y aplicada en el campo de la inteligencia artificial en el ámbito de los navegadores web.
La elección de cuantizar solo la matriz más voluminosa y mantener en alto nivel la precisión demuestra un nivel avanzado de ingeniería que logra el equilibrio perfecto entre compresión y calidad. Los resultados impactan positivamente en el almacenamiento, velocidad, consumo de recursos, y facilitan una navegación fluida y precisa, validando que la innovación puede ir de la mano con la accesibilidad y eficiencia. Este desarrollo también abre un camino interesante para futuras implementaciones en otras aplicaciones de machine learning, especialmente aquellas que deben funcionar en dispositivos con limitaciones de hardware. La enseñanza clave está en identificar qué componentes críticos pueden ser optimizados sin afectar la experiencia final y cómo el entrenamiento con conciencia de cuantización puede mitigar los riesgos de degradación en la precisión. Con este nuevo modelo, Google Chrome continúa consolidando su posición como un pionero en la integración de tecnologías de inteligencia artificial avanzadas en el navegador, aportando beneficios concretos a millones de usuarios alrededor del mundo y estableciendo estándares que seguramente serán emulados en la industria.
El futuro de la navegación inteligente está aquí, más pequeño, más rápido, y con la calidad que los usuarios esperan.








