En la era digital actual, la inteligencia artificial y, en particular, los grandes modelos de lenguaje (LLMs, por sus siglas en inglés) están transformando la manera en que interactuamos con la información. Estas tecnologías son capaces de comprender, generar y razonar con lenguaje natural a niveles previamente inimaginables. Sin embargo, una de las áreas donde los LLMs enfrentan desafíos importantes es la búsqueda efectiva de información para apoyar sus capacidades de razonamiento y generación. Tradicionalmente, los modelos han dependido de motores de búsqueda externos para obtener datos en tiempo real, lo que plantea problemas como la inconsistencia en la calidad de los documentos recuperados y costos prohibitivos por el uso continuo de APIs. Ahí es donde ZeroSearch emerge como una solución innovadora, incentivando la capacidad de búsqueda de los LLMs sin necesidad de realizar búsquedas reales durante el entrenamiento.
El núcleo del problema que aborda ZeroSearch es doble. Por un lado, la calidad impredecible de los documentos que devuelven los motores de búsqueda introduce un ruido considerable en el proceso de entrenamiento de los modelos, afectando negativamente su aprendizaje. Por otro, el entrenamiento mediante aprendizaje por refuerzo (RL) que implica interacciones constantes con motores de búsqueda conlleva gastos elevados, ya que cada consulta realizada puede sumar costos significativos al acumularse en miles o incluso cientos de miles de solicitudes. Esta combinación pone un límite claro a la escalabilidad y viabilidad económica de los enfoques tradicionales. ZeroSearch se plantea superar estas barreras con un enfoque estratégico y eficiente que simula el entorno de búsqueda para que el modelo aprenda a manejar diferentes calidades de información sin necesidad de consultar fuentes externas reales.
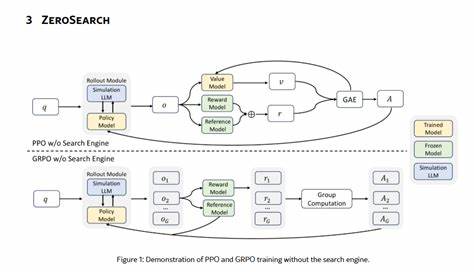
La propuesta de ZeroSearch comienza con una fase de ajuste fino supervisado, donde un modelo de lenguaje relativamente pequeño se transforma en un módulo de recuperación. Este módulo genera documentos que pueden ser tanto útiles como contener ruido, simulando así la variabilidad de la información que un motor de búsqueda real podría proporcionar. De esta forma, durante el entrenamiento, el modelo se expone a diferentes escenarios de calidad de documento que lo preparan para el manejo y procesamiento de información en condiciones imperfectas. Este procedimiento es fundamental porque permite que el modelo construya una habilidad sólida para discernir, razonar y utilizar datos variados sin depender de la disponibilidad y calidad de resultados externos. Uno de los elementos más innovadores de ZeroSearch es la estrategia de rollout basada en un currículo que se aplica durante el aprendizaje por refuerzo.
La idea es degradar gradualmente la calidad de los documentos simulados presentados al modelo en cada etapa del entrenamiento. Este proceso escalonado obliga al modelo a adaptar y mejorar su capacidad de razonamiento, enfrentando desafíos cada vez mayores y aprendiendo a superar las adversidades que la información imprecisa o ruidosa plantea. A través de esta técnica, ZeroSearch logra potenciar la resiliencia del modelo y su habilidad para mantener un desempeño alto a pesar de la variabilidad y dificultad creciente del material con el que trabaja. Los resultados experimentales de ZeroSearch son notables y demuestran la efectividad del enfoque. Utilizando un LLM con 3 mil millones de parámetros como base para el módulo de recuperación, el sistema ya muestra mejoras significativas en su capacidad de búsqueda simulada.
Más sorprendente aún es el desempeño de módulos con 7 mil millones y 14 mil millones de parámetros, los cuales igualan e incluso superan el rendimiento de motores de búsqueda reales, respectivamente. Esto indica no solo la viabilidad del enfoque sino que potencialmente se está frente a una nueva generación de modelos capaces de gestionar información con una autonomía y eficiencia sin precedentes. Otra ventaja destacada de ZeroSearch es su adaptabilidad y generalización. El marco propuesto no se limita a un solo modelo o configuración; es compatible con diferentes tamaños de modelos, tanto base como ajustados mediante instrucciones, y puede integrarse con diversas variantes de algoritmos de aprendizaje por refuerzo. Esta flexibilidad es crucial porque permite que desarrolladores e investigadores apliquen la metodología en múltiples contextos y necesidades, facilitando la mejora continua y la innovación en el área de procesamiento del lenguaje natural.
En un contexto más amplio, ZeroSearch representa un avance significativo en la manera en que los LLMs pueden aprender y mejorar su interacción con fuentes de información sin depender directamente de estas durante el entrenamiento. Este paradigma no solo reduce costos y evita la incertidumbre ligada a la calidad de contenido externo, sino que también abre el camino a modelos más autónomos, responsables y eficientes en la gestión de datos. En conclusión, ZeroSearch ofrece un enfoque revolucionario para incentivar la capacidad de búsqueda de los grandes modelos de lenguaje sin la necesidad de realizar búsquedas reales durante el entrenamiento. Mediante la simulación inteligente de documentos y una estrategia de aprendizaje escalonada basada en la dificultad, se consigue que los modelos desarrollen habilidades avanzadas para manejar información variada y ruidosa. El impacto de esta metodología se refleja en mejoras cuantificables en el desempeño y la eficiencia, además de su amplio potencial para adaptarse a distintos modelos y técnicas de aprendizaje.
A medida que la inteligencia artificial continúa su expansión y profundización en nuestras vidas, innovaciones como ZeroSearch serán clave para potenciar su evolución y maximizar sus beneficios.