Desde su lanzamiento, DeepSeek-R1 ha generado gran interés en la comunidad de inteligencia artificial y procesamiento del lenguaje natural debido a sus avanzadas capacidades de razonamiento y generación de contenido. Sin embargo, un fenómeno preocupante ha surgido en torno a este modelo: su tendencia a generar alucinaciones, entendidas como información incorrecta o no respaldada explícitamente por las fuentes originales. DeepSeek-R1 presenta una tasa de alucinación del 14.3%, cifra muy superior a la de su antecesor DeepSeek V3 que reporta solo un 3.9%.
Este diferencial ha despertado la curiosidad por comprender las causas detrás de este comportamiento y su impacto en la calidad de las aplicaciones basadas en este modelo. Es fundamental entender qué impulsa este aumento en las alucinaciones para optimizar la experiencia del usuario, mejorar la confiabilidad de las respuestas y orientar la evolución futura de los LLM (Modelos de Lenguaje a Gran Escala) con capacidades avanzadas de razonamiento. Uno de los enfoques iniciales para comprender la razón de la mayor tasa de alucinación fue considerar el papel del razonamiento. DeepSeek-R1 está diseñado para realizar pasos de lógica y reflexión más profundos durante la generación de sus respuestas, a diferencia de la versión V3 que tiene un enfoque menos centrado en el razonamiento explícito. Un análisis comparativo entre modelos con y sin capacidades de razonamiento revela una tendencia común: los modelos de razonamiento tienden a alucinar más que sus contrapartes no orientadas a procesos lógicos avanzados.
Sin embargo, pruebas específicas con DeepSeek demuestran que el razonamiento en sí mismo no es la causa principal de la alucinación. Al inyectar el contenido de razonamiento de DeepSeek-R1 en el prompt de DeepSeek V3 y solicitar que este último genere resúmenes, la tasa de alucinación del modelo V3 no solamente no aumentó, sino que incluso descendió en ciertas variantes. De esta forma, la hipótesis inicial que vinculaba el mayor nivel de razonamiento con más errores factuales fue descartada. Esta evidencia llevó a la investigación hacia otro fenómeno: DeepSeek-R1 tiende a «sobreayudar» a los usuarios añadiendo información que no está explícitamente indicada en el texto original, aunque dicha información sea correcta o plausible desde el punto de vista del conocimiento general o contexto mundial. Estas alucinaciones, denominadas benignas, son aquellas desviaciones que, si bien no se encuentran en la fuente, son aceptables o incluso deseables para quien consume el contenido.
Por ejemplo, al procesar datos sobre el programa «Weekly Idol», DeepSeek-R1 añadió el descriptor “coreano” aunque el artículo original no lo mencionaba, dado que es un conocimiento comúnmente asociado al programa. Esta tendencia a completar con datos adicionales que “encajan” dentro del contexto puede ser valorada como un signo de razonamiento o contextualización avanzada, pero a la vez implica un riesgo de desviación de la estricta fidelidad al texto fuente. Para comprobar con rigor esta hipótesis, se llevó a cabo un estudio con 50 pares de muestras generadas por DeepSeek-R1 y DeepSeek V3 en las que sus evaluaciones de hallucination diferían. Cinco anotadores humanos analizaron estas muestras clasificando cada alucinación en categorías que incluían las alucinaciones benignas, aquellas consistentes con otras fuentes y las inconsistentes, que eran claramente erróneas o no justificables. El análisis reveló que DeepSeek-R1 presentaba una concentración mucho mayor de alucinaciones benignas: de 46 casos de alucinaciones señalados por humanos en R1, 33 fueron benignas (un 71.
7% de ellas). En contraste, DeepSeek V3 presentó un 36.8% de alucinaciones benignas. Esto valida que la mayor tasa de alucinaciones en R1 está más relacionada con la tendencia a añadir información extrapolada o contextualizada que con errores factuales genuinos o deficiencias en la base documental. Un aspecto clave en esta investigación fue el desarrollo y aplicación de métodos para detectar y evaluar alucinaciones.
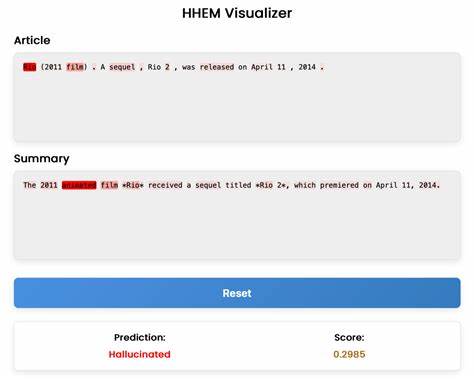
El equipo de Vectara diseñó HHEM, un evaluador automático con alta sensibilidad para captar alucinaciones benignas, que suelen ser difíciles de discernir para los métodos convencionales de detección como el uso de LLM actuando como jueces. Las variantes más básicas y razonadas de LLM-as-a-judge mostraron pobres niveles de acuerdo con las anotaciones humanas cuando se trataba de identificar estas alucinaciones benignas, mientras que HHEM alcanzó elevadas concordancias superiores al 88% en el caso de DeepSeek-R1. Este hallazgo es relevante porque proporciona una herramienta robusta para monitorear la calidad y la fidelidad del contenido generado por modelos con tendencias fuertemente contextualizadoras. Ejemplos concretos ilustran bien esta problemática. Cuando se suministró información sobre la película «Rio (2011 film)» donde no se mencionaba que era una película animada, DeepSeek-R1 añadió el término “animada”, que es correcto pero no estaba en la fuente.
Similarmente, en casos relacionados con noticias policiales o datos científicos, el modelo completó términos o conceptos que hacen sentido, pero no se encontraban explicitados. Desde un punto de vista práctico, muchos usuarios podrían encontrar estos añadidos aceptables o incluso útiles, pero pueden debilitar la percepción de confiabilidad cuando se requiere estricta adherencia a una fuente concreta. A nivel técnico, se especula que la causa raíz del fenómeno en DeepSeek-R1 puede estar asociada a las particularidades del protocolo de entrenamiento utilizado. Al reforzar la capacidad del modelo para razonar y proporcionar resúmenes interpretativos, puede haberse incentivado indirectamente la generación de información adicional que el modelo considera relevante o pertinente —aunque no provenga del texto original—. Este comportamiento sugiere que los objetivos y parámetros definidos en el entrenamiento quizás favorecen la completitud o utilidad general frente a la precisión estricta de la información.
Entonces, ¿cuáles son las implicaciones para desarrolladores y empresas que utilizan DeepSeek-R1? Primero, deben estar conscientes del compromiso entre capacidades avanzadas de razonamiento y la producción de respuestas estrictamente fieles, lo que puede afectar la precisión de información en contextos sensibles. En aplicaciones donde la veracidad y la rastreabilidad de los datos es crucial, DeepSeek-R1 podría no ser la mejor opción aun cuando brinde ventajas en análisis y explicabilidad. De hecho, la excesiva «ayuda» del modelo puede generar consecuencias no deseadas, especialmente en entornos regulados o donde la transparencia es prioritaria. Por otro lado, los avances en herramientas como HHEM para la detección automatizada de alucinaciones benignas y no benignas suponen un salto importante hacia la mitigación y control de estos riesgos. Integrar estas tecnologías de evaluación dentro de plataformas de generación y búsqueda aumentada puede mejorar de forma significativa la confianza y aplicabilidad empresarial de los modelos LLM.
La capacidad de distinguir entre una información extrapolada plausible y una realmente errónea es vital para alcanzar niveles aceptables de desempeño en soluciones comerciales y de investigación. Para concluir, la elevada tasa de alucinaciones en DeepSeek-R1 no es un simple fallo técnico o una consecuencia directa del razonamiento avanzado, sino más bien un reflejo de su tendencia a extenderse e incorporar información contextual o extrapolada que, aunque correcta o probable, no se limita estrictamente a las fuentes proporcionadas. Este fenómeno representa un doble filo: por un lado, añade valor en cuanto a profundidad y contextualización; por otro lado, compromete la precisión estricta del reporte. La adopción responsable y crítica de DeepSeek-R1 implica entender y gestionar esta dinámica, aprovechar sus fortalezas bajo vigilancia rigurosa y continuar investigando mecanismos de evaluación y control como HHEM para mejorar su desempeño en el futuro. La industria de la IA está frente a un desafío que obliga a balancear creatividad y precisión para maximizar el beneficio y minimizar los riesgos inherentes a la generación automatizada de contenido por inteligencia artificial.
La comunidad entera espera que las futuras iteraciones y mejoras en modelos como DeepSeek combinen lo mejor de ambos mundos para ofrecer resultados fiables, explicables y enriquecidos a la vez. Invitamos a desarrolladores, investigadores y usuarios a seguir aportando ideas y casos de uso para avanzar en este empeño, apoyados por plataformas y herramientas que promuevan la transparencia, la detección precisa de alucinaciones y la mejora continua en los sistemas de generación de lenguaje natural.