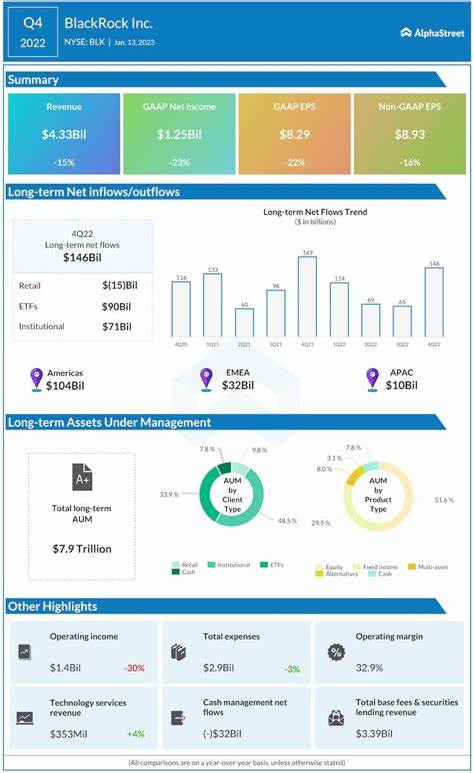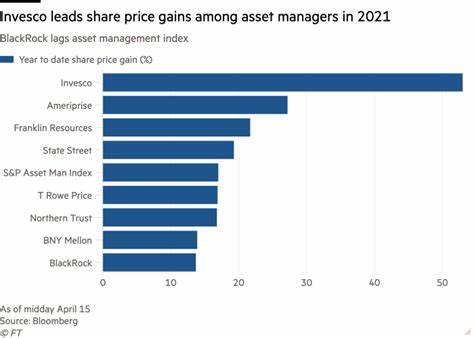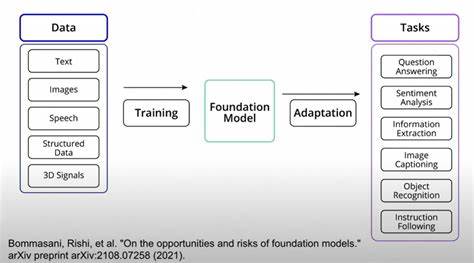
En los últimos años, el aprendizaje automático y, específicamente, el aprendizaje profundo han experimentado un crecimiento exponencial, impulsado en gran parte por la disponibilidad de modelos fundacionales de gran escala. Estos modelos, entrenados con enormes volúmenes de datos, sirven como base para múltiples aplicaciones en visión por computadora, procesamiento de lenguaje natural y otras áreas. Sin embargo, la aplicación práctica de estos modelos en escenarios específicos, sobre todo en el aprendizaje de cola larga, presenta desafíos particulares que han motivado recientes investigaciones para optimizar el proceso de adaptación conocido como fine-tuning. Aquí surge LIFT+, una propuesta innovadora que promete transformar la manera en que se realiza este ajuste fino de modelos, equilibrando eficiencia y rendimiento en clases poco representadas o minoritarias dentro de los conjuntos de datos, conocidas como clases de cola larga. El aprendizaje de cola larga se refiere al problema que enfrentan los modelos cuando deben reconocer y aprender categorías con frecuencias de aparición muy desbalanceadas.
Mientras las clases mayoritarias cuentan con abundantes ejemplos, las clases minoritarias tienen muy pocos, generando un rendimiento deficiente en la predicción y generalización para estas últimas. Tradicionalmente, una solución común ha sido el fine-tuning intenso, donde se modifican una gran cantidad de parámetros del modelo para adaptarlo al nuevo dominio o tarea. Sin embargo, este enfoque no siempre garantiza mejoras en la precisión para las categorías menos representadas y puede incluso resultar contraproducente. Investigaciones recientes como la presentada por Jiang-Xin Shi, Tong Wei y Yu-Feng Li revelan que el fine-tuning pesado, contrario a lo esperado, puede deteriorar el desempeño en las clases de cola, debido a la inconsistencia en las distribuciones condicionales de las clases inducidas durante el proceso de actualización masiva de parámetros. Esto implica que modificar una gran parte del modelo afecta negativamente la distribución de representaciones aprendidas, especialmente para aquellas clases con menos datos, generando sobreajuste o desplazamiento en la interpretación del modelo.
Frente a esta problemática, surge LIFT+ (Lightweight Fine-Tuning Plus), un marco de trabajo que busca optimizar el proceso de fine-tuning utilizando una estrategia ligera y enfocada en mantener la coherencia de las distribuciones condicionales de las clases. Este método no solo reduce significativamente la cantidad de parámetros que se ajustan durante el proceso de fine-tuning, sino que también incorpora técnicas avanzadas para mejorar la inicialización, la augmentación de datos de forma minimalista y el ensamble en tiempo de prueba, con el fin de potenciar la adaptabilidad y la generalización del modelo fundacional. Uno de los mayores beneficios de LIFT+ es su eficiencia. Mientras los enfoques tradicionales requieren cerca de 100 épocas de entrenamiento para lograr resultados adecuados, LIFT+ reduce este número a un máximo de 15, lo que implica una notable reducción en los tiempos y recursos computacionales necesarios. Además, el modelo ajustado modera la actualización a menos del 1% de sus parámetros, un cambio delicado pero efectivo que mantiene la esencia del conocimiento previamente adquirido mientras mejora la capacidad del modelo para identificar clases con baja representación.
La incorporación de una inicialización semántica consciente es otro pilar fundamental del éxito de LIFT+. Al aprovechar una representación previa que encuentra un punto de partida más favorable para el ajuste, se evita que el modelo se desvíe demasiado de la estructura de conocimiento global aprendida, especialmente para clases minoritarias. Esto, junto con técnicas de augmentación de datos que no generan un exceso de variabilidad sino que fortalecen los ejemplos disponibles, contribuye a un entrenamiento más estable y robusto. Además, el ensamble en tiempo de prueba es una estrategia que permite mejorar la predicción combinando múltiples inferencias del modelo bajo diferentes condiciones, maximizando la precisión sin coste adicional en entrenamiento. Esta combinación de técnicas convierten a LIFT+ en un marco altamente efectivo para escenarios donde el desbalance en datos representa un obstáculo para el aprendizaje efectivo.
La importancia de LIFT+ no se limita solo a la mejora en métricas de precisión. En términos prácticos, esta metodología abre un abanico de posibilidades para implementar inteligencia artificial en contextos donde existe una abrumadora predominancia de algunas clases sobre otras, como en el reconocimiento facial en poblaciones diversas, la identificación de objetos raros en imágenes satelitales o incluso en la clasificación de textos especializados con etiquetas poco frecuentes. Además, desde la perspectiva del desarrollo sostenible y la democratización tecnológica, LIFT+ reduce la necesidad de contar con extensos recursos computacionales para adaptar modelos fundacionales, fomentando un acceso más amplio a soluciones de última generación en instituciones con limitaciones técnicas. La reducción significativa en parámetros ajustados y en tiempo de entrenamiento también implica un menor consumo de energía, alineándose con prácticas más responsables con el medio ambiente dentro del campo de la inteligencia artificial. La validación empírica presentada en el estudio detrás de LIFT+ destacó resultados que superan claramente a los métodos de vanguardia existentes, no solo en benchmarks estándar sino también en conjuntos de datos complejos y desequilibrados.