En la intersección entre el aprendizaje automático y el procesamiento del lenguaje natural, el aprendizaje por refuerzo representa una herramienta fundamental para enseñar a los modelos a tomar decisiones óptimas basadas en señales de recompensa. Dos algoritmos que han destacado en esta área, especialmente en la optimización de modelos de lenguaje, son Proximal Policy Optimization (PPO) y Group Relative Proximal Policy Optimization (GRPO). La comprensión de estos métodos es indispensable para quienes buscan comprender cómo las máquinas aprenden a generar texto de forma coherente y útil para usuarios humanos. El proceso de entrenamiento de grandes modelos de lenguaje (LLMs, por sus siglas en inglés) suele dividirse en dos fases principales: preentrenamiento y postentrenamiento. En la etapa inicial, el modelo aprende a interpretar y generar texto mediante técnicas de aprendizaje auto-supervisado, familiarizándose con la estructura del lenguaje y adquiriendo conocimientos generales.
Sin embargo, aunque en esta fase adquiere habilidades impresionantes para predecir la siguiente palabra o token en un texto, carece de orientación específica para responder a instrucciones humanas o adaptarse a preferencias subjetivas. Aquí es donde el postentrenamiento adquiere relevancia al afinar el comportamiento del modelo para convertirlo en un asistente más efectivo, alineado con las expectativas y requerimientos humanos. Dentro de esta fase, la Reinforcement Fine-Tuning (RFT) emerge como una técnica poderosa que utiliza señales de recompensa para mejorar la calidad y pertinencia de las respuestas generadas. En el núcleo de los métodos de RFT se encuentra el planteamiento clásico del aprendizaje por refuerzo, donde un agente interactúa con un entorno tomando acciones de acuerdo con una política, y recibe retroalimentación en forma de recompensas. La meta es aprender una política que maximize la suma esperada de estas recompensas.
En el caso de los modelos de lenguaje, el “entorno” es el texto o contexto que se proporciona como entrada, y la “acción” corresponde a la generación de una respuesta completa. A diferencia de sistemas tradicionales, las respuestas son evaluadas en su conjunto, generando un desafío conocido como el problema de los bandits, donde las recompensas escasas dificultan asignar crédito a acciones o tokens específicos. Para superar esta dificultad, se emplea un modelo de recompensa aprendido a partir de preferencias humanas. Utilizando el modelo de Bradley-Terry, se transforman juicios subjetivos comparativos entre respuestas en puntuaciones numéricas que el sistema puede utilizar para mejorar su comportamiento. Este modelo asigna probabilidades de preferencia basadas en “fuerzas” relativas que se estiman exponencialmente para asegurar positividad y facilidad de optimización.
En el entrenamiento de este modelo de recompensa, se utiliza una función de pérdida basada en la entropía cruzada binaria que clasifica cuál respuesta es preferida, consolidando una mejor comprensión de las señales preferenciales y permitiendo que el modelo ajuste sus parámetros para reflejarlas con mayor fidelidad. Una vez que se cuenta con un modelo de recompensa efectivo, el reto es actualizar el modelo generativo para maximizar estas recompensas. Aquí es donde los algoritmos de gradiente de política toman relevancia. Estos algoritmos buscan optimizar directamente la política del modelo ajustando sus parámetros a través de la estimación del gradiente que incrementa la probabilidad de acciones que conducen a mejores resultados. Un concepto fundamental en estos métodos es la función ventaja, que mide cuán favorable es una acción tomada en comparación con el promedio, permitiendo identificar y reforzar comportamientos que exceden las expectativas.
Sin embargo, estimar la ventaja con precisión es complicado debido al balance entre sesgo y varianza. Métodos simples como la estimación de diferencia temporal (TD) tienen bajo riesgo de variación pero alta tendencia al sesgo, mientras que el método Monte Carlo es opuesto, ofreciendo estimaciones sin sesgo pero sujetos a mayor fluctuación y costo computacional. Para abordar este compromiso, la estimación de ventaja generalizada (GAE) combina lo mejor de ambos mundos, proporcionando una estimación ponderada que equilibra la precisión y estabilidad, esencial para el entrenamiento eficiente de modelos de lenguaje donde la retroalimentación suele ser limitada y costosa. Dentro de la familia de algoritmos de política por gradientes, Proximal Policy Optimization o PPO se destaca por su estabilidad y eficacia. PPO introduce una función objetivo que utiliza un ratio entre las políticas nueva y antigua para asegurar que las actualizaciones no sean demasiado abruptas.
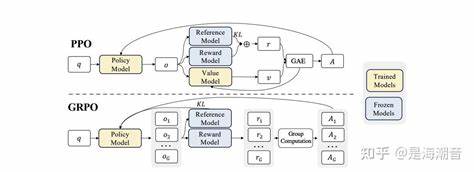
Esta técnica incluye un mecanismo de recorte que limita el cambio de probabilidad permisible en cada paso de entrenamiento, evitando que el modelo caiga en estados de sobreajuste o colapso de capacidades. El cálculo de esta razón de políticas funciona como un término de corrección para el muestreo fuera de política, garantizando que el aprendizaje permanezca estable incluso cuando la política cambia rápidamente. Además, PPO trabaja generalmente con probabilidades token a token en el contexto del modelado de lenguaje, lo que permite ajustes finos en la generación de texto. Sin embargo, PPO también tiene sus desventajas, siendo una de las principales el requerimiento de entrenar una red de valor para estimar la función de estado, lo cual puede aumentar considerablemente los recursos computacionales necesarios. En este punto, aparece Group Relative Proximal Policy Optimization (GRPO), un algoritmo derivado de PPO que simplifica el proceso eliminando la necesidad de una red de valor.
GRPO se basa en la idea de agrupar múltiples respuestas a la misma consulta y realizar un proceso de comparación relativa entre ellas. De esta forma, se asigna a cada respuesta un valor de ventaja en función de su posición relativa dentro del grupo, normalizando las recompensas en términos de media y desviación estándar. Esta estrategia de comparación grupal aporta varios beneficios. Primero, reduce la complejidad computacional al evitar el entrenamiento adicional de un estimador de valor. Segundo, crea una señal de aprendizaje más robusta y estable al basar la actualización en comparaciones dentro de un conjunto homogéneo de resultados.
Finalmente, la inclusión de una penalización basada en la divergencia KL frente a un modelo de referencia ayuda a prevenir la desviación excesiva del modelo de conocimiento y habilidades previas, asegurando que el asistente lingüístico mantenenga su utilidad general mientras se especializa. El papel que juegan PPO y GRPO en el entrenamiento de modelos de lenguaje es fundamental para mejorar la alineación de estos sistemas con preferencias humanas, estabilizando el proceso de aprendizaje y asegurando respuestas coherentes y pertinentes. Ambos algoritmos representan soluciones elegantes al desafío de balancear exploración y explotación, permitiendo que los modelos aprendan de manera eficiente a partir de retroalimentación escasa y a menudo tardía. En resumen, la evolución de técnicas como PPO hacia variantes optimizadas como GRPO marca un avance significativo en la capacidad para entrenar modelos de lenguaje grandes que sean no solo competentes en el manejo del lenguaje sino también adaptativos a las expectativas y matices humanos. Estas herramientas continúan siendo objeto de investigación activa, con miras a optimizar su rendimiento y aplicabilidad en sistemas reales.
El entendimiento de estos métodos no solo contribuye a la mejora de asistentes conversacionales y sistemas de generación automática de texto, sino que también abre la puerta a innovaciones futuras en áreas donde la interacción hombre-máquina es crítica, desde la educación hasta la atención médica y más allá. A medida que estos algoritmos se perfeccionan, la posibilidad de obtener modelos cada vez más alineados, confiables y eficientes se vuelve una realidad tangible. Para aquellos interesados en profundizar en este campo, es recomendable explorar recursos especializados que desglosan estos algoritmos y analizan sus implementaciones en contextos reales. A medida que la tecnología avanza, el conocimiento en aprendizaje por refuerzo, así como la comprensión del comportamiento y optimización de modelos de lenguaje, será cada vez más valioso para desarrolladores, investigadores y usuarios interesados en la inteligencia artificial avanzada.