El ordenamiento eficiente de datos es una tarea fundamental en la computación moderna, especialmente en contextos donde el rendimiento y la rapidez son clave, como en aplicaciones científicas, análisis de grandes volúmenes de información y aprendizaje automático. Las GPUs (unidades de procesamiento gráfico) se han convertido en herramientas esenciales para acelerar procesos computacionales, gracias a su arquitectura masivamente paralela. En este contexto, el uso de intrínsecos SIMD (Single Instruction, Multiple Data) en CUDA ha revolucionado la manera en que abordamos algoritmos de ordenamiento, permitiendo optimizaciones sustanciales y un aprovechamiento eficaz del hardware. Una de las estrategias más interesantes para la aceleración del ordenamiento es la aplicación del bitonic sort, un algoritmo basado en redes de ordenamiento que se beneficia de la paralelización extrema que ofrecen las GPUs. A diferencia de los métodos secuenciales que requieren un tiempo proporcional a O(n log n) para ordenar n elementos, el bitonic sort ofrece un tiempo paralelo logarítmico al cuadrado, específicamente O(log² n), que aunque pueda parecer mayor en términos de complejidad, resulta extremadamente eficiente cuando se despliega en arquitecturas de procesamiento con múltiples hilos ejecutándose simultáneamente.
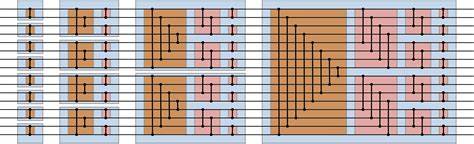
El concepto fundamental detrás del ordenamiento bitónico concierne a la manipulación de secuencias bitónicas, definidas como la concatenación de dos secuencias monotónicas (ya sean crecientes o decrecientes). Esta característica permite que el algoritmo opere como una red de comparaciones y permutaciones organizadas en etapas paralelas. La estructura se asemeja a un circuito lógico donde en cada paso se realizan intercambios condicionados que gradualmente reorganizan los datos hasta alcanzar una secuencia totalmente ordenada. Las GPUs modernas, organizadas en bloques de hilos y subdivididas en unidades denominadas warps (generalmente de 32 hilos), ejecutan instrucciones de forma SIMD, lo que significa que una sola instrucción se aplica simultáneamente a un conjunto de datos distribuidos a través de las lanes del warp. Este modelo es ideal para operaciones intensamente paralelizadas como el ordenamiento bitónico.
En CUDA, el intrínseco __shfl_sync permite el intercambio directo de valores entre las lanes dentro de un warp sin necesidad de recurrir a la memoria compartida o global. Este método elimina latencias ocasionadas por operaciones de lectura/escritura en memoria, además de reducir la necesidad de sincronización explícita de los hilos usando __syncwarp, que puede convertirse en un cuello de botella de rendimiento. El uso de __shfl_sync facilita operaciones de permutación complejas, esenciales en el bitonic sort para comparar y reorganizar datos entre lanes arbitrarias dentro del warp. Una implementación típica del bitonic sort en CUDA implica cargar los datos en registros de cada hilo y realizar iterativamente comparaciones y posibles intercambios con datos de otras lanes indicadas por el patrón del algoritmo. La combinación de operaciones min y max en cada ciclo garantiza que los valores se ordenen progresivamente.
La optimización basada en los intrínsecos SIMD ha demostrado un aumento superior al 30% en el rendimiento respecto a versiones que emplean memoria compartida para el intercambio de datos. El poder de esta técnica cobra especial relevancia al combinarse con algoritmos de ordenamiento más generales como el mergesort, donde el bitonic sort se utiliza para ordenar bloques base de tamaño 32 rápidamente dentro de cada hilo warp antes de proceder con etapas de fusión más complejas. La capacidad para acelerar esta fase base implica una mejora significativa en el tiempo total de ejecución de un algoritmo de ordenamiento en GPU a gran escala. El bitonic sort está naturalmente limitado a datos cuyo tamaño sea potencia de dos, dado que los pasos de comparación y mezcla están diseñados para dividirse y combinarse en mitades iguales iterativamente. No obstante, en la práctica, esta limitación se supera mediante técnicas de padding, añadiendo valores extremos que no afectan el resultado pero aseguran que la cantidad de datos se ajuste a las dimensiones necesarias para el algoritmo.
Desde una perspectiva más amplia, trabajar con intrínsecos SIMD en CUDA no solo implica escribir código más eficiente, sino también requiere comprender el modelo de ejecución SIMT (Single Instruction, Multiple Threads) de los GPUs. Aunque conceptualmente similar a SIMD, SIMT permite la gestión de hilos individuales con ciertos grados de libertad, pero que aún se ejecutan de forma síncrona dentro del warp. La correcta sincronización y manejo del flujo de datos es crucial para evitar condiciones de carrera y asegurar que los resultados sean correctos. Las mejoras que se obtienen al usar __shfl_sync para el intercambio directo de datos entre lanes también impactan en la utilización de la memoria del sistema. Al reducir el acceso a la memoria compartida y global, se disminuye la presión en los buses de datos y se liberan recursos para otras operaciones.
Esto se traduce en un aumento general del throughput y una reducción de la latencia que puede resultar fundamental en aplicaciones de alta demanda. Por otro lado, detrás de estos avances está el considerable trabajo de ingeniería y diseño de los fabricantes de hardware que han incorporado primitivas de comunicación eficientes a nivel warp dentro de sus arquitecturas. Además, la integración con herramientas de desarrollo y bibliotecas estándar como Thrust facilita la adopción por parte de desarrolladores, permitiendo implementar ordenamientos paralelizados sin sacrificar la legibilidad o mantenibilidad del código. En el futuro, se espera que la sinergia entre algoritmos de ordenamiento paralelos y las capacidades intrínsecas de los GPUs continúen evolucionando. Algunas posibles líneas de investigación incluyen la optimización de fusiones de múltiples vías (por ejemplo, fusiones 32-a-la-vez) que aprovechan la velocidad del bitonic sort como bloque fundamental, o la combinación con algoritmos adaptativos que pueden ajustarse dependiendo del tipo de datos o carga computacional.
En conclusión, el uso de intrínsecos SIMD en CUDA representa una vía poderosa para acelerar significativamente el ordenamiento de datos en GPUs. Gracias a la naturaleza paralela del bitonic sort y el eficiente manejo de la comunicación entre hilos a través de __shfl_sync, es posible optimizar el consumo de recursos y obtener mejoras de rendimiento notables. Estas tecnologías juegan un papel crucial en la modernización y escalabilidad de aplicaciones que manejan grandes conjuntos de datos, haciendo que las GPUs sean aún más indispensables en el panorama computacional actual.