Durante años, uno de mis grandes sueños ha sido aprender a programar en GPU, y finalmente en abril de 2025 decidí ponerme en serio con CUDA. Fue un camino de aprendizaje intenso que me llevó a comprender no solo la arquitectura de las tarjetas gráficas modernas, sino también la mentalidad necesaria para crear código eficiente que explote plenamente la capacidad de cómputo paralelo que ofrecen estas unidades. Mi experiencia revela que pensar en CUDA no es lo mismo que programar para un CPU convencional; requiere un cambio profundo en la forma en que concebimos la división de trabajo y el manejo de la memoria. Para entender CUDA y su impacto, primero hay que conocer la historia detrás de la programación en GPU. Originalmente, las GPUs estaban dedicadas a acelerar la representación gráfica mediante un pipeline fijo de operaciones: procesamiento de vértices, rasterización, generación de fragmentos y operaciones de salida.
Este modelo rígido limitaba la versatilidad del hardware porque solo funcionaban para tareas gráficas específicas. Esto cambió con la introducción de los shaders y luego con la llegada de los Unified Shaders en tarjetas como la Nvidia 8800GTX, que permitieron que un mismo hardware realizara diferentes funciones según la programación del momento. CUDA surgió como una revolución en la computación paralela, al proveer un ecosistema en el que los desarrolladores podían escribir kernels, es decir, funciones que se ejecutan en la GPU para cualquier tipo de cálculo, más allá del renderizado gráfico. Esto abrió la puerta para aplicaciones diversas, desde procesamiento de imágenes y video hasta simulaciones científicas y, muy especialmente, el auge del aprendizaje automático. Uno de los conceptos claves que aprendí al profundizar en CUDA es la relación fundamental entre operaciones y memoria, lo que llamamos Flops por Byte.
Por ejemplo, la tarjeta RTX 4090 es impresionante en su capacidad de cómputo, alcanzando hasta 82 Teraflops en operaciones punto flotante de 32 bits, pero su velocidad para acceder a la memoria es mucho menor en comparación. Esto significa que no basta con tener una GPU potente; la verdadera optimización pasa por disminuir la cantidad de lectura y escritura en memoria global, que es un cuello de botella crucial. Para contrarrestar este desafío, las GPUs cuentan con una memoria compartida dentro de cada Streaming Multiprocessor, que actúa como una caché rápida, y los programadores deben diseñar algoritmos que aprovechen esta capacidad al máximo. Por ejemplo, en la multiplicación matricial, uno debe pensar en la forma en que cada hilo (thread) accede a los datos para evitar accesos innecesarios a la memoria principal. En el mundo CPU, típicamente un solo hilo carga matrices A y B, calcula la matriz C y guarda los resultados.
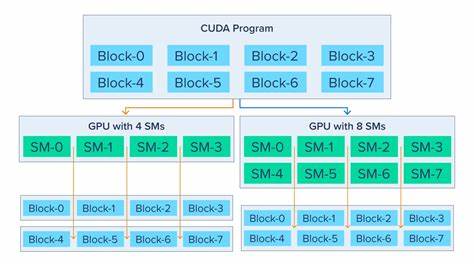
En CUDA, cada hilo está encargado de un elemento específico de la matriz resultado, accediendo a porciones pequeñas y usando técnicas de bloqueo y segmentación (tiled matrix multiplication) para compartir datos entre hilos y reducir la presión sobre la memoria. Esta manera particular de distribuir el trabajo y pensar en los datos es una de las mayores barreras para novatos, pues requiere imaginar el problema desde el producto final hacia las entradas, en lugar de hacerlo al revés como se hace tradicionalmente en CPU. Aprender a visualizar cómo el índice del hilo determina qué datos debe cargar y qué resultado debe calcular es fundamental para escribir kernels eficientes. En cuanto al manejo de hilos, es fascinante cómo una GPU puede lanzar miles de ellos simultáneamente, muy diferente a los procesadores tradicionales que solo cuentan con unos pocos núcleos físicos y penalizan un exceso de concurrencia. En CUDA, se emplean estructuras llamadas bloques y mallas para organizar los hilos, y el programador debe calcular cuidadosamente las dimensiones de estas para cubrir todos los elementos de salida sin desperdiciar recursos.
Estas configuraciones, junto con el manejo de los índices de hilo y bloque, pueden parecer bastante enredadas al principio, pero son clave para exprimir la capacidad total del hardware. Una de las mejores formas en que adquirí confianza en CUDA fue mediante la práctica en plataformas como Tensara y LeetGPU, que ofrecen problemas prácticos centrados en aprendizaje automático y programación paralela. Las dificultades para depurar código en estos entornos me enseñaron el valor de escribir kernels robustos y pensar en casos límite rigurosos, además de comprender mejor la estructura de los datos y la memoria global y compartida. Escribir y depurar estos problemas resultó indispensable para afinar mis habilidades. En mi camino de aprendizaje también encontré recursos esenciales que recomiendo fervientemente a quienes deseen profundizar en CUDA.
El libro más representativo sigue siendo el famoso “Orange Book”, titulado 'Programming Massively Parallel Processors', que ofrece una mirada clara a patrones de programación paralela y técnicas para optimizar el rendimiento en arquitectura GPU. Aunque no cubre de forma exhaustiva la configuración de los parámetros de bloques y mallas, proporciona la base conceptual necesaria para comprender cómo funcionan los kernels y cómo mejorar su eficiencia. Complementariamente, el libro 'Professional CUDA C Programming' brinda detalles más específicos sobre la API de CUDA, facilitando un entendimiento más práctico y aprehensible. Además de estos recursos formales, la interacción con proyectos innovadores como HipScript, que permite compilar kernels CUDA para ejecución en navegadores web y diferentes plataformas utilizando la tecnología HIP de AMD, me inspiró a valorar el esfuerzo de los desarrolladores y la comunidad abierta que impulsa el avance en este campo. Ahora, en 2025, las GPUs no solo dominan la escena de los videojuegos y gráficos, sino que se han convertido en la espina dorsal de la revolución en inteligencia artificial.
El impacto de la computación paralela cuántica ha trascendido. Por ejemplo, la habilidad para optimizar el uso de memoria y operaciones elementales influyen directamente en que modelos de lenguaje masivos puedan entrenarse y ejecutarse de forma eficiente en cortes de tiempo y con consumo energético razonables. Con la intención de expandir mis horizontes, considero invertir en hardware especializado como la plataforma Jetson Orin o Nano de NVIDIA, que me permitiría ejecutar pruebas y aplicaciones reales sin depender exclusivamente de servicios en la nube. Sin embargo, también reconozco la importancia de afinar mis habilidades primero, al menos resolviendo un buen porcentaje de problemas disponibles en Tensara. Esto garantizará que mi experiencia sea lo suficientemente sólida para justificar cualquier inversión en hardware avanzado o en renta de máquinas virtuales dedicadas en servicios como vast.
ai. Por otro lado, la lectura de artículos técnicos y papers de arquitectura HPC, como el trabajo de DeepSeek sobre el Fire-Flyer HPC, revelan que la competencia en desarrollo de tecnologías para computación de alto rendimiento es global y cada vez más sofisticada. Implementaciones personalizadas de reducción de datos, como HFReduce, muestran que no todo depende del hardware sino también de la creatividad para diseñar soluciones software más eficientes que aprovechen al máximo cada recurso. En conclusión, aprender a pensar en CUDA significa cambiar nuestra forma de razonar sobre el flujo de datos, la distribución del trabajo y el aprovechamiento de la memoria. Requiere disciplina para entender un modelo menos directo pero fantástico en su capacidad de paralelismo, donde miles de pequeñas piezas trabajan en conjunto por un objetivo común.
El viaje de aprendizaje es desafiante pero sumamente gratificante, y las oportunidades que abre son inmensas, desde el desarrollo de aplicaciones científicas hasta la optimización de inteligencias artificiales que marcarán el futuro de la computación. Para quienes deseen adentrarse en esta disciplina, recomiendo comenzar con los fundamentos, practicar mucho en plataformas de problemas prácticos y aprovechar los recursos bibliográficos tradicionales y comunitarios. En poco tiempo, la magia de la programación paralelo en GPU revelará sus secretos y permitirá transformar ideas en soluciones poderosas que impacten en múltiples campos de la tecnología moderna.




![Programming Without Pointers [video]](/images/CEF441B6-A2A3-42A6-A8C0-AF8879AEF22A)