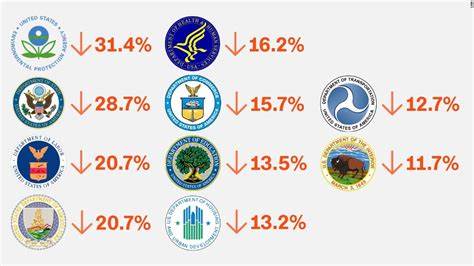
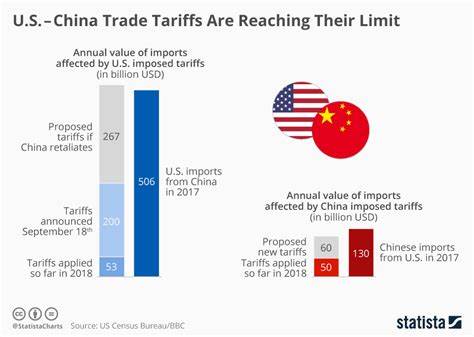
Los sistemas RAG (Retrieval-Augmented Generation) representan una evolución fascinante en el desarrollo de aplicaciones basadas en inteligencia artificial, combinando técnicas de recuperación de información con modelos avanzados de lenguaje para generar respuestas precisas y contextualizadas. Sin embargo, quienes han desarrollado su primera aplicación RAG saben que la experiencia puede ser un tanto frustrante cuando los resultados no alcanzan las expectativas iniciales. No es raro sentirse decepcionado al constatar que la calidad de las respuestas o la velocidad del sistema no son las ideales. La buena noticia es que, a pesar de las dificultades, es posible mejorar significativamente estos sistemas distribuyendo soluciones específicas a cada parte del proceso. Para entender cómo hacerlo, es esencial conocer las etapas del pipeline de un sistema RAG y las áreas donde suelen presentarse cuellos de botella.
Inicialmente, la mayoría de los proyectos RAG comienzan organizando la información en trozos o «chunks», luego estos fragmentos se convierten en vectores mediante procesos de embedding, seguidamente se almacenan en una base preparada para recuperación eficiente, se ejecutan consultas que permiten recuperar información relevante y finalmente se genera la respuesta mediante un componente de generación o de ampliación de datos. La clave para el éxito está en identificar problemas específicos en cada etapa y aplicar medidas correctivas que mejoren la experiencia global. El primer componente, el de fragmentación o chunking, es fundamental para garantizar el éxito del resto del sistema. Elegir correctamente la estrategia para dividir el contenido evita que se incluya información irrelevante dentro del prompt que alimentará al modelo generador. Cuando un modelo de lenguaje recibe datos con mucho ruido o datos que no guardan relación directa con la consulta, la calidad de las respuestas cae precipitadamente.
Por ende, adoptar una lógica de fragmentación cuidadosa que priorice la coherencia contextual es el primer paso para aumentar la calidad de las respuestas. A continuación, la transformación de estos fragmentos en vectores mediante modelos de embedding es otro punto crítico. Los modelos y técnicas elegidos para crear embeddings influyen directamente en la capacidad del sistema para recuperar información relevante. Existen múltiples algoritmos y arquitecturas que permiten representar conceptos semánticos con diferentes grados de precisión. Escoger embeddings de alta calidad y entrenados en dominios cercanos a la temática del sistema impulsará el rendimiento general.
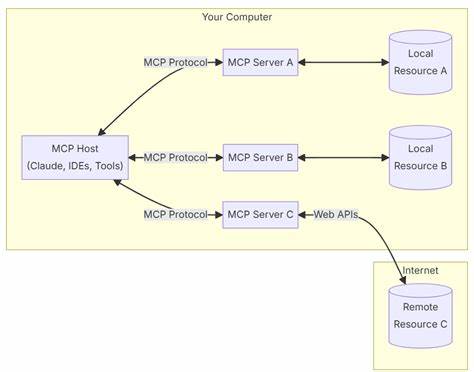
Pero no basta con una buena generación de embeddings, el almacenamiento debe estar optimizado para consultas rápidas y eficientes. La elección de sistemas vectoriales de bases de datos o motores especializados para indexación juega un rol decisivo en reducir la latencia y garantizar que el usuario reciba respuestas ágilmente. Tecnologías como FAISS, Pinecone o Milvus se han posicionado como opciones confiables para esta tarea y deben configurarse con parámetros adecuados según el volumen de datos y la frecuencia de consultas que se esperen. Una vez consolidado el almacenamiento, el módulo de recuperación es responsable de identificar qué fragmentos son realmente relevantes a partir del vector de la consulta. Es común que la precisión en esta etapa defina en gran medida la utilidad del sistema, pues traer información irrelevante o escasa limita la capacidad del modelo generador para responder correctamente.
Por ello, la implementación de estrategias avanzadas de búsqueda y recuperación, incluyendo técnicas de reranking o combinación de búsquedas booleanas con semánticas, mejora sustancialmente la pertinencia del contenido seleccionado. Otro aspecto a pulir es la integración eficiente de la información recuperada dentro del prompt que alimentará al modelo de lenguaje. En esta fase, conocida como augmentación, se debe garantizar que el contenido necesario quede perfectamente ambientado y contextualizado para facilitar la generación de respuestas precisas. Además, hay que cuidar la longitud y la estructura para no sobrepasar limitaciones típicas de los modelos y evitar la saturación del prompt con datos superfluos. La última etapa, correspondiente a la generación misma de la respuesta, se beneficia enormemente de modelos grandes, pero también requiere ajustes personalizados que optimicen la coherencia y claridad de las respuestas.
Ajustar hiperparámetros como temperatura o longitud máxima, o emplear modelos afinados para el dominio de interés, contribuye a mejorar la experiencia del usuario final. En la práctica, este conjunto integral de mejoras, paso a paso y desde la base, ha demostrado transformar aplicaciones RAG comunes y rutinarias en soluciones robustas, confiables y escalables listas para su consolidación en producción. La posibilidad de iterar y ajustar cada componente individualmente brinda un marco efectivo tanto para desarrolladores como consultores que buscan obtener el máximo rendimiento de estas tecnologías emergentes. Adoptar esta metodología no solo resuelve problemas puntuales de calidad o latencia sino que también solidifica la arquitectura y prepara el sistema para futuros retos y expansiones. En conclusión, trabajar sistemáticamente en la fragmentación, embedding, almacenamiento, recuperación, augmentación y generación lleva a superar las limitaciones iniciales comunes en los sistemas RAG.
Entender la dinámica particular del pipeline es esencial para aplicar mejoras precisas y escalables que permitan generar respuestas de alta calidad en tiempos reducidos. Esta aproximación estratégica obliga a profundizar en cada componente y aplicar las mejores prácticas para sacar el máximo provecho de las capacidades de inteligencia artificial actuales, poniendo al alcance herramientas potentes para resolver problemas complejos de forma más eficiente y práctica.