En la era digital actual, los modelos de lenguaje grandes (Large Language Models, LLMs) han revolucionado la forma en que interactuamos con la información y accedemos al conocimiento. Herramientas como ChatGPT han demostrado una capacidad impresionante para procesar y generar texto natural, lo que ha abierto un abanico de posibilidades en sectores como la educación, la investigación y los negocios. Sin embargo, muchos usuarios y profesionales requieren soluciones que puedan trabajar localmente, con sus propios datos, para mantener la privacidad, mejorar la personalización y garantizar un acceso inmediato a recursos específicos. En este contexto, surge una interrogante común: ¿cómo se pueden enriquecer los modelos de lenguaje locales con documentos en formato PDF guardados en nuestras propias computadoras o servidores? En este artículo, abordaremos esta cuestión, explorando potenciales métodos, herramientas y beneficios de utilizar PDFs locales para complementar la inteligencia del modelo y ofrecer respuestas más precisas y contextualizadas. Los modelos de lenguaje grandes son entrenados inicialmente con una amplia variedad de fuentes textuales para adquirir un conocimiento generalizado.
Sin embargo, debido a la grandísima cantidad de documentos que existen, es imposible para un modelo entender o recordar en detalle información muy específica o actualizada que pueda encontrarse, por ejemplo, en una carpeta de investigación personal o en archivos corporativos. Es allí cuando la combinación de esos modelos con archivos PDF locales cobra sentido, pues los documentos actúan como fuentes de información directa, válida y contextualizada. La integración de PDFs locales con LLMs puede suceder mediante procesos que extraen y estructuran el texto contenido en dichos archivos, para posteriormente indexarlo y crear bases de datos semánticas que el modelo pueda consultar. Este enfoque permite alimentar el modelo con información actualizada y específica sin la necesidad de entrenarlo de nuevo, un proceso que suele ser costoso y en ocasiones poco práctico para usuarios comunes. Esta manera de operar ha generado interés para quienes buscan una experiencia similar a la de ChatGPT, pero aplicada a sus propias colecciones de documentos, con el plus de que las respuestas pueden incluir citas directas o referencias a los PDFs consultados.
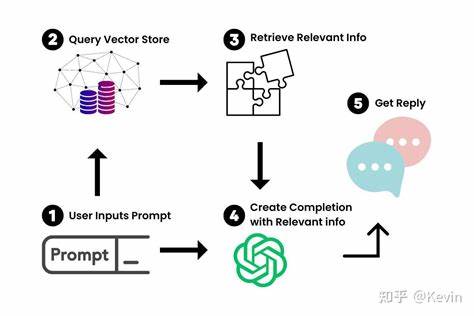
Además, mantener los datos localmente puede aportar ventajas significativas en términos de privacidad y control de la información, evitando enviar documentos confidenciales a servidores externos. Para comenzar a trabajar con esta integración, es fundamental contar con una herramienta que permita la lectura y extracción de texto de PDFs. Existen bibliotecas y software que convierten el contenido de un PDF en texto legible y manipulable, como PyPDF2, pdfminer o herramientas más especializadas que pueden manejar PDFs escaneados mediante OCR (Reconocimiento Óptico de Caracteres). Una vez extraído el contenido, el siguiente paso es organizarlo de forma que el modelo pueda acceder a fragmentos relevantes durante la consulta. Con la extracción realizada, uno de los métodos más eficaces para enlazar la información textual con el modelo es el uso de índices vectoriales o embeddings.
Estas representaciones numéricas codifican el significado semántico de los fragmentos de texto y permiten búsquedas por similitud, es decir, el sistema identifica qué partes del contenido son más relevantes para la consulta que realiza el usuario. Hay varias librerías y frameworks que facilitan esta tarea, como FAISS de Facebook, Annoy de Spotify o vectores en clave de Elasticsearch, que pueden integrarse con APIs de modelos de lenguaje locales. Al combinar estas tecnologías, es posible crear un sistema en el que el usuario ingresa una pregunta y el motor busca en los textos indexados los fragmentos con mayor relevancia, que luego se utilizan para formular una respuesta informada y contextualizada. Las soluciones más avanzadas pueden ir un paso más allá creando un entorno de chat interactivo en el que el modelo no sólo responde, sino que puede citar documentos específicos con precisión, permitiendo validar y profundizar en las respuestas. Este nivel de integración ofrece grandes beneficios para investigadores, profesionales legales, médicos y cualquier persona que necesite trabajar con grandes volúmenes de documentos específicos.
Además de la funcionalidad, otro aspecto clave para enriquecer modelos locales con PDFs es la facilidad de uso y configuración. Muchas iniciativas de software libre y proyectos open source están emergiendo para ofrecer plataformas intuitivas que no requieran conocimientos técnicos avanzados para implementar esta funcionalidad. De esta manera, ámbitos educativos y pequeñas empresas pueden beneficiarse sin realizar grandes inversiones en infraestructura o personal técnico especialista. A la hora de considerar estas implementaciones, también hay que tener en cuenta aspectos como la calidad del PDF original, puesto que documentos escaneados sin texto digitalizado requieren herramientas de OCR que pueden introducir errores de reconocimiento. Por ello, la calidad de la extracción influye directamente en la precisión del modelo a la hora de generar respuestas.
Asimismo, mantener actualizada la base documental y contar con procesos de actualización automática son desafíos que deben considerarse para asegurar que la inteligencia local permanezca vigente con el paso del tiempo. La personalización que logra la combinación de LLMs con PDFs locales es especialmente valiosa cuando se manejan temas especializados o nichos muy concretos. Los modelos generales pueden no tener suficiente profundidad en áreas técnicas, científicas o legales, mientras que al incorporar documentos propios, el sistema puede ofrecer un entendimiento mucho más fino, adaptado a las necesidades del usuario. Por otra parte, trabajar localmente también abre la puerta a optimizar el rendimiento y reducir la dependencia de una conexión a internet estable, requisito fundamental cuando se utilizan soluciones basadas en la nube. Para usuarios en zonas con conectividad limitada o preocupaciones de seguridad, esta ventaja transforma el modo en que interactúan con la información.