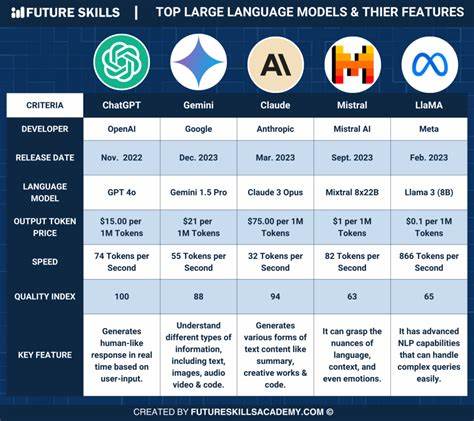
En el mundo actual de la inteligencia artificial, los grandes modelos de lenguaje (LLMs) como Claude Sonnet 3.7, Gemini Pro 2.5 y o4-mini han alcanzado un reconocimiento significativo por su capacidad para manejar una amplia variedad de tareas y consultas. Su versatilidad y potencia les han permitido posicionarse en la cúspide de los rankings de IA. Sin embargo, pese a su gran alcance y versatilidad, existe un método para superar a estos gigantes tecnológicos de una manera mucho más eficiente y costo-efectiva: la especialización mediante el aprendizaje por refuerzo (RL, por sus siglas en inglés).
Esta metodología no solo promete maximizar la efectividad en tareas concretas sino que también define un nuevo paradigma en la forma en que desarrollamos agentes inteligentes dentro del ámbito tecnológico. Los modelos generalistas son diseñados para abarcar una infinidad de temas, desde física avanzada hasta poesía, pasando por prácticamente cualquier consulta imaginable en Internet. Esta amplitud muchas veces implica que no explotan a fondo el dominio particular que un usuario o negocio podría requerir. Por ejemplo, un agente de viajes basado en una IA no necesita tener conocimientos sobresalientes en temas científicos complejos; lo que realmente se espera es que sea experto en localizar y reservar paquetes vacacionales que se ajusten a las necesidades del usuario. Este enfoque enfocado puede marcar la diferencia al ofrecer respuestas y soluciones mucho más precisas, rápidas y rentables.
Aquí es donde el aprendizaje por refuerzo se presenta como una solución revolucionaria. Esta técnica se basa en optimizar un modelo para cumplir con tareas muy concretas, utilizando una función de recompensa que cuantifica el desempeño de acuerdo con los objetivos deseados. Esta función de recompensa puede variar según el dominio y las necesidades específicas, desde evaluaciones proporcionadas por humanos hasta métricas codificadas en software para evaluar criterios específicos. Precisamente esa flexibilidad permite crear modelos entrenados para superar tareas especializadas con un rendimiento que en ocasiones supera incluso a los humanos. Un ejemplo claro es la experiencia reportada por plataformas dedicadas al desarrollo de RL, que han demostrado resultados sorprendentes con modelos relativamente pequeños, como uno de 3 mil millones de parámetros que puede operar en un dispositivo como un iPhone.
Después de solo un par de horas de entrenamiento mediante RL en tareas químicas, estos modelos lograron diseñar moléculas capaces de inhibir proteínas del coronavirus con una efectividad superior a la de modelos generales avanzados como Claude 3.7. Esto no solo implica una eficiencia en tiempo y recursos, sino también un gran avance en la funcionalidad práctica de la IA especializada. Otra aplicación muestra cómo el aprendizaje por refuerzo permite a un modelo concentrarse en problemas tan específicos como llenar formularios complejos rápidamente. Mientras algunos grandes modelos generales fallan o toman demasiado tiempo con tareas engorrosas, un modelo entrenado específicamente bajo RL puede resolver el problema en menos de dos minutos.
Esta capacidad de adaptación inmediata y ejecución eficiente ejemplifica por qué RunRL está impulsando un cambio de enfoque en el desarrollo de IA. El aprendizaje por refuerzo ofrece varias ventajas frente al simple ajuste fino tradicional. Por un lado, evita el sobreajuste, lo que significa que el modelo no se limita a repetir patrones de entrenamientos previos sino que es capaz de generalizar mejor en situaciones nuevas. Por otro lado, no requiere que el desarrollador tenga ya un conjunto extenso de buenos ejemplos para guiar el aprendizaje; la interacción directa con el entorno y la evaluación continua mediante la función de recompensa hacen que el modelo aprenda a comportarse de manera óptima desde cero. Las empresas y desarrolladores que deseen implementar agentes inteligentes especializados pueden basarse en métricas claras de rendimiento ya establecidas para definir sus funciones de recompensa y aprovechar RL para acelerar el proceso.
En caso de no contar con estos datos o evaluaciones, existen herramientas y colaboraciones, como las ofrecidas por The LLM Data Company, que facilitan la medición y definición de recompensas para optimizar modelos gracias al aprendizaje por refuerzo. Asimismo, la plataforma de RunRL se destaca como un facilitador para democratizar el uso del aprendizaje por refuerzo en la comunidad de desarrolladores y empresas de distintas escalas. Al ofrecer infraestructura y soporte que simplifican la integración y entrenamiento de agentes personalizados, RunRL está ayudando a que tecnologías avanzadas no se limiten a gigantes corporativos sino que sean accesibles para una amplia variedad de aplicaciones y sectores. En conclusión, mientras que los LLMs generalistas han sido fundamentalmente exitosos en la creación de agentes capaces de manejar una multitud de consultas, el futuro apunta hacia la especialización inteligente. El aprendizaje por refuerzo representa un camino eficiente para desarrollar modelos que no solo compiten sino que superan la capacidad de los grandes modelos generales, optimizando costos, tiempos de entrenamiento y precisión en tareas concretas.
Esta revolución del modelado especializado promete transformar sectores desde la química y la medicina hasta la atención al cliente y la automatización de procesos complejos, abriendo un abanico de posibilidades que antes eran impensables. Adoptar esta metodología, apoyada por plataformas como RunRL, significa estar a la vanguardia de la inteligencia artificial personalizada, capaz de responder de manera intuitiva y eficiente a las necesidades más específicas. La optimización mediante RL no solo es una mejora técnica, sino una redefinición estratégica de cómo concebimos y desarrollamos agentes inteligentes, convirtiendo la especialización en la mejor herramienta para superar la competencia y obtener resultados sobresalientes.