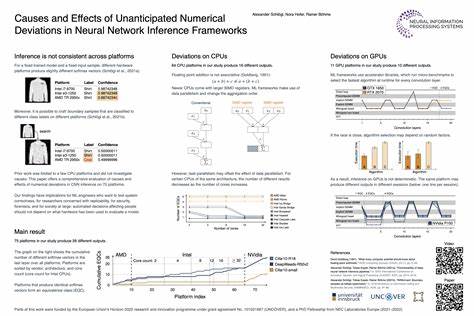
En el fascinante mundo del aprendizaje automático y las redes neuronales, la precisión y la consistencia de los resultados son cruciales para garantizar su utilidad y confiabilidad. Recientemente, un estudio destacado en NeurIPS 2023 ha puesto en evidencia un fenómeno poco discutido pero sumamente importante: las desviaciones numéricas inesperadas que ocurren durante la inferencia de redes neuronales, incluso cuando se mantienen constantes tanto el modelo entrenado como los datos de entrada. Esta investigación realizada por Alexander Schlögl, Nora Hofer y Rainer Böhme representa un avance significativo en nuestra comprensión sobre cómo el hardware y las optimizaciones específicas dentro de los marcos de trabajo de aprendizaje automático influyen en el comportamiento final de los modelos neurales. El problema central de estas desviaciones numéricas radica en que los resultados de las inferencias no son consistentes entre diferentes plataformas de hardware y, en algunos casos, ni siquiera son deterministas en la misma plataforma. Esto significa que, utilizando el mismo modelo preentrenado y con los mismos datos de entrada, se pueden obtener resultados numéricamente distintos dependiendo del dispositivo o del entorno donde se ejecute la inferencia.
En términos prácticos, esta situación genera preocupaciones críticas en campos donde la precisión y la reproducibilidad son esenciales, tales como la seguridad informática, el diagnóstico médico, y otras aplicaciones donde decisiones automatizadas deben ser confiables. Diversos factores contribuyen a estas desviaciones, siendo el hardware uno de los más importantes. Las diferencias en procesadores, tarjetas gráficas (GPUs), e incluso en la configuración de las unidades de procesamiento vectorial (SIMD) llevan a que cada plataforma adopte diferentes estrategias para ejecutar las operaciones necesarias en las redes neuronales. Por ejemplo, el uso de instrucciones SIMD en CPUs puede variar ampliamente, afectando la precisión y el orden de las operaciones aritméticas, lo que ocasiona pequeñas pero significativas discrepancias en el resultado final. En el caso de las GPUs, los algoritmos seleccionados en tiempo de ejecución para realizar convoluciones, que son operaciones fundamentales en muchas redes neuronales especialmente en las CNN (redes neuronales convolucionales), influyen notablemente en la consistencia numérica de la inferencia.
Estas optimizaciones están diseñadas para mejorar el rendimiento y la velocidad, sin embargo, introducen variabilidad en la forma cómo se calculan los resultados debido a diferencias en la implementación y el paralelismo inherente a las GPUs modernas. Esta diversidad de resultados expone un desafío para la comunidad de inteligencia artificial. ¿Cómo garantizar que un sistema basado en aprendizaje automático mantenga resultados reproducibles y confiables en distintos entornos? En este sentido, los autores del estudio han realizado experimentos extensivos en 75 plataformas distintas para analizar estas desviaciones, logrando identificar patrones y causas subyacentes. Su metodología combina evaluaciones en pipelines completos de inferencia y pruebas aisladas de operaciones específicas, generando así un entendimiento profundo del origen de las variaciones numéricas. Además de establecer las causas técnicas, la investigación también destaca cómo estas desviaciones se propagan a través de las distintas capas y etapas de procesamiento en los modelos, afectando el resultado final y la confianza en las predicciones.
La propagación de errores, aunque a veces sutil, puede amplificarse en modelos más complejos o en casos donde se requieren decisiones muy precisas, lo cual puede tener impactos significativos en aplicaciones prácticas. Una parte crucial del estudio se focaliza también en la evaluación de posibles mitigaciones para minimizar estas desviaciones y asegurar una mayor coherencia en las inferencias. Aunque no existe una solución mágica que elimine por completo la variabilidad inherente al procesamiento en diferentes arquitecturas de hardware, algunas estrategias como la estandarización de implementaciones, el control riguroso del entorno de ejecución y el desarrollo de marcos de trabajo que favorezcan la reproducibilidad están emergiendo como caminos prometedores. La publicación de este trabajo y la disponibilidad pública del código asociado fomentan la transparencia y el progreso en esta área, permitiendo que otros investigadores y profesionales puedan replicar los experimentos, validar los resultados y contribuir con nuevas propuestas que mejoren la estabilidad numérica en la inferencia de redes neuronales. En definitiva, este hallazgo pone en relieve una dimensión crítica y a menudo no suficientemente valorada en la implementación práctica del aprendizaje automático, especialmente en ambientes donde la seguridad, la verificabilidad y la reproducibilidad son prioritarias.
Las desviaciones numéricas inesperadas no solo representan un reto técnico sino también un llamado a la comunidad científica a desarrollar soluciones más robustas y estandarizadas. Según las tendencias actuales y el avance acelerado de la inteligencia artificial, la comprensión profunda de estos fenómenos y su mitigación será esencial para asegurar que las aplicaciones basadas en redes neuronales sean tan confiables y precisas como se espera en el mundo real. La investigación de Schlögl, Hofer y Böhme abre una puerta para futuras exploraciones que garanticen que la innovación tecnológica en redes neuronales se traduzca en beneficios efectivos, sostenibles y segurizados para la sociedad en general.