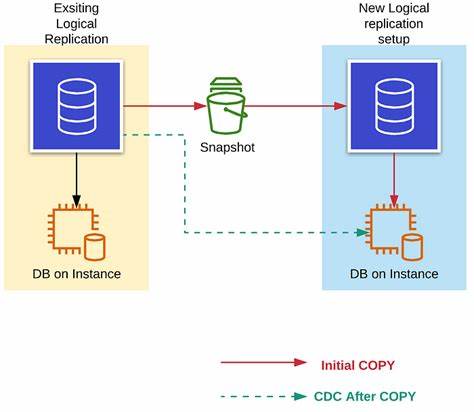
El uso de bases de datos PostgreSQL en entornos de producción es cada vez más común debido a su robustez, flexibilidad y rendimiento. Sin embargo, realizar modificaciones directamente en un entorno productivo siempre implica riesgos que pueden desencadenar interrupciones inesperadas, afectar la experiencia del usuario o generar pérdidas de datos. Para hacer frente a estos desafíos, replicar el tráfico real de producción en entornos separados ha emergido como una estrategia indispensable para administradores y desarrolladores. Entender la replicación exacta del tráfico post-production consiste en copiar las consultas que llegan a una base de datos en producción y enviarlas simultáneamente a otra instancia que actúa como espejo. Esto permite evaluar el impacto de los cambios, ya sea en la configuración o en la estructura del esquema, sin poner en riesgo la estabilidad del sistema principal.
Una herramienta destacada en este ámbito es PgDog, un proxy especializado que logra esta réplica mediante una única configuración sencilla. PgDog opera interceptando y comprendiendo el protocolo de comunicación de Postgres, conocido como protocolo wire. Cuando un cliente envía una consulta, esta se dirige al servidor principal para su ejecución habitual, mientras que en paralelo se duplica hacia una base de datos espejo. Este proceso se ejecuta en segundo plano y de manera asíncrona para no afectar la latencia ni el rendimiento de las consultas originales. Además, los resultados obtenidos por el espejo son descartados rápidamente, garantizando que el estado de la conexión se mantenga sin interrupciones.
Una de las ventajas fundamentales del sistema de mirroring que proporciona PgDog es cómo administra el tráfico enviado hacia el espejo. Usa un grupo de conexiones separado que puede escalar dinámicamente el número de consultas replicadas. Esto significa que la base de datos espejo puede recibir más o menos tráfico según su capacidad en ese momento, y las solicitudes excedentes se almacenan en una cola de espera. Esta cola es vital para controlar la fluidez del sistema, evitando pérdidas en caso de que la base espejo no pueda absorber consultas a tiempo. Cada cliente que se conecta a PgDog mantiene una cola independiente, lo que facilita la escalabilidad proporcional al volumen real de producción.
En caso de que la cola supere un límite configurable, las consultas adicionales se descartan temporalmente, evitando que un fallo prolongado en el espejo impacte la base principal. Esta metodología permite una recuperación gradual y sin sobresaltos. Las aplicaciones prácticas de la réplica del tráfico de producción son numerosas y diversas. En primer lugar, permite probar con total seguridad los efectos que tendrían cambios en la configuración de Postgres, tales como ajustar parámetros críticos como shared_buffers, max_wal_size o checkpoint_timeout. Cabe destacar que algunos de estos ajustes requieren reiniciar la base de datos, una tarea que en producción puede resultar complicada o incluso inviable.
Gracias a la réplica, estas pruebas se pueden efectuar en un entorno que simula exactamente las condiciones reales de trabajo. Otra utilidad es el calentamiento o "warm up" de réplicas recién creadas antes de ponerlas a servir tráfico real. En servicios gestionados como AWS, las réplicas de Postgres se generan a partir de instantáneas almacenadas en S3, y al lanzar el nuevo servidor, las unidades de almacenamiento están prácticamente vacías. La ejecución de las primeras consultas hace que las páginas necesarias se vayan cargando dinámicamente en el disco, proceso que puede ser lento y generar cuellos de botella o incluso interrupciones. Mediante la técnica de mirroring, es posible enviar tráfico real a la réplica mientras ésta inicia y precarga las tablas e índices más consultados en producción.
Esto aporta una ventaja significativa frente a otras soluciones tradicionales como pg_prewarm, que suelen basarse en datos fríos o consultas sintéticas. La réplica calienta su cache con tráfico auténtico, lo que mejora significativamente la velocidad y estabilidad cuando finalmente empieza a operar en producción. El paradigma del sharding, tan relevante en bases de datos distribuidas y escalables, también se ve beneficiado por esta capacidad de replicar tráfico. Ya que las bases espejos pueden ser configuradas con arquitecturas distintas a la original, puede probarse un cluster shardeado enviando consultas reales sin perturbar el tráfico principal. Esto abre una puerta para evaluar cómo se manejarían consultas complejas, cómo se repartiría la carga y cuál sería el impacto en el rendimiento antes de desplegar cambios de arquitectura.
Un desafío importante al replicar tráfico en Postgres es lidiar con la naturaleza stateful del protocolo wire, que requiere sincronización constante entre cliente y servidor para mantener la consistencia de la conexión. PgDog aborda esta complejidad almacenando íntegramente cada solicitud en memoria antes de reproducirla en ambos servidores. Para el modo simple, esto significa almacenar el mensaje Query completo; mientras que para el protocolo extendido que implica declaraciones preparadas, el buffering se extiende hasta alcanzar comandos de sincronización como Sync o Flush. Si por alguna razón la tarea asíncrona de envío al espejo se retrasa o la base de datos réplica no responde adecuadamente, la solicitud completa en espera es descartada para evitar desincronización. Esto garantiza que las conexiones con los servidores siempre permanezcan en un estado limpio y funcional, evitando cierres abruptos o errores que podrían afectar negativamente el funcionamiento global.