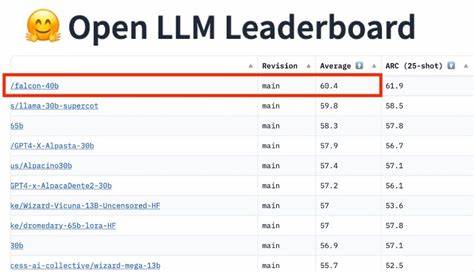
En los últimos años, el campo de la inteligencia artificial ha experimentado un crecimiento exponencial, especialmente en lo que concierne a los modelos de lenguaje. Conocidos como LLM por sus siglas en inglés (Large Language Models), estos sistemas de inteligencia artificial han revolucionado la forma en que las máquinas entienden y generan texto, afectando desde aplicaciones de búsqueda y asistentes virtuales hasta traducción automática y creación de contenido. Un aspecto fundamental que cobra cada vez más protagonismo es el desarrollo y disponibilidad de modelos de lenguaje abiertos, junto con datos abiertos, que potencian tanto la innovación como la transparencia en la IA. Los modelos de lenguaje abiertos representan una ruptura significativa frente a los tradicionales modelos cerrados de propiedad de grandes corporaciones tecnológicas. Estas soluciones permiten que comunidades de desarrolladores, investigadores y empresas de todos los tamaños puedan acceder, modificar y utilizar la tecnología de modelado del lenguaje sin las restricciones de licencias cerradas.
De esta manera, se fomenta una colaboración global y una democratización tecnológica que hace posible que cualquiera pueda experimentar y mejorar estos modelos. Una de las ventajas más destacadas de los LLM open source es la posibilidad de personalización y adaptación en sectores específicos. Muchas organizaciones enfrentan necesidades particulares o trabajan con datos sensibles que no pueden ser compartidos con proveedores externos. Al contar con un modelo abierto, es posible entrenar o afinar el modelo con conjuntos de datos de dominio privado, garantizando así estabilidad, privacidad y un rendimiento adaptado a los escenarios propios. Además de los modelos, la disponibilidad de datos abiertos es un pilar crucial para la evolución y eficacia de estos sistemas.
El acceso a datasets variados y de alta calidad permite entrenar modelos con un amplio espectro de información, que incluye textos en múltiples idiomas, dialectos y estilos. El uso responsable y ético de datos abiertos también mitiga problemas relacionados con el sesgo, al diversificar las fuentes y reducir la dependencia de conjuntos de datos limitados o sesgados. En este contexto, emergen proyectos y frameworks innovadores que aplican técnicas avanzadas de eficiencia y optimización para el entrenamiento y despliegue de modelos de lenguaje abiertos. Por ejemplo, se utilizan arquitecturas que incorporan capas especializadas de expertos o mecanismos de atención que mejoran la capacidad de procesamiento sin aumentar exponencialmente los recursos computacionales necesarios. Estas mejoras técnicas permiten acercar la capacidad de modelos competitivos a instituciones con recursos más modestos o para su uso en dispositivos locales, reduciendo la dependencia de la nube.
La comunidad de desarrolladores juega un rol protagónico en la evolución de los LLM open source. A través de plataformas colaborativas y repositorios abiertos, se generan contribuciones en forma de código, optimizaciones, documentación y herramientas de evaluación que fortalecen el ecosistema en su conjunto. Es común observar que los proyectos más exitosos cuentan con un sólido sistema de ablation testing, evaluaciones en benchmarks reconocidos y una integración eficiente con sistemas de monitoreo y visualización de métricas, que garantizan la fiabilidad y reproducibilidad de los resultados. Por otro lado, el factor costo es otro incentivo para optar por modelos abiertos. El entrenamiento de un gran modelo de lenguaje puede ser prohibitivo por sus requerimientos de hardware, consumo energético y licencias.
Al usar frameworks optimizados y aprovechar kernels acelerados para GPUs de última generación, es decir, unidades especializadas para procesamiento paralelo, el costo se reduce notablemente. Estas optimizaciones técnicas también tienen un impacto positivo en la huella ambiental, al hacer más sostenibles los procesos intensivos en cómputo. Además, la transparencia inherente a los proyectos open source y de datos abiertos fortalece la confianza del público y las entidades reguladoras. En un entorno donde la ética en la inteligencia artificial es una preocupación creciente, el poder examinar y validar cómo se entrenan y evalúan los modelos, así como los datos empleados, es esencial para mitigar riesgos de mal uso o sesgos perjudiciales. Esta cultura de apertura crea un espacio para la auditoría externa y la mejora continua.
La expansión del acceso a modelos de lenguaje abiertos también promueve la inclusión digital y lingüística. Idiomas menos representados, dialectos regionales y comunidades con bajo acceso a tecnologías de punta se benefician enormemente cuando los recursos no están bloqueados por barreras comerciales o técnicas. Esto abre la puerta a aplicaciones personalizadas que resultan en un mejor entendimiento e interacción para usuarios de diferentes contextos culturales y lingüísticos. Algunos casos de éxito recientes demuestran el potencial disruptivo de esta tendencia. Instituciones académicas y organizaciones sin fines de lucro han logrado desarrollar modelos que compiten en calidad y versatilidad con los productos comerciales más avanzados.
Esto no solo favorece la innovación tecnológica sino que contribuye a la formación y capacitación en áreas emergentes de IA, ampliando la base de talento y conocimiento a nivel global. Pese al avance, existen desafíos importantes que deben ser enfrentados. La gestión y curación de grandes volúmenes de datos abiertos puede conllevar dificultades legales y éticas, debido a la privacidad, derechos de autor y consentimientos. Igualmente, mantener la calidad y representatividad de los datos para evitar sesgos profundos es una tarea compleja que requiere colaboración interdisciplinaria. Por otra parte, es imprescindible fomentar un equilibrio entre la apertura y la protección contra usos maliciosos, como generación automatizada de desinformación.
Mirando hacia el futuro, la sinergia entre modelos de lenguaje open source y datos abiertos tiene un enorme potencial para transformar diversos sectores. Desde la educación personalizada, pasando por la medicina, la justicia y la atención al cliente, estas tecnologías permitirán soluciones más accesibles, efectivas y adaptadas. La combinación de avances técnicos, apertura colaborativa y conciencia ética configurará el camino hacia un ecosistema de inteligencia artificial más justo y sostenible. En resumen, los modelos de lenguaje abiertos y el acceso a datos abiertos se presentan como un eje fundamental para democratizar la inteligencia artificial. La innovación acelerada, la reducción de barreras económicas, la transparencia y la diversidad de aplicaciones son algunos de los beneficios clave que este enfoque genera.
A medida que comunidades técnicas y usuarios finales continúan abrazando estas herramientas y recursos, se construye un futuro en el que la inteligencia artificial no es patrimonio exclusivo de unos pocos, sino un recurso global para el desarrollo humano y tecnológico.



![Artificial Intelligence Report 2025 [pdf]](/images/93C6ABDB-C6B7-4B47-9D39-9F37FF8D4CEB)