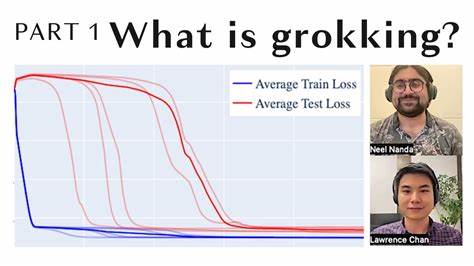
El campo de la inteligencia artificial y el aprendizaje automático está en constante evolución, y uno de los fenómenos más intrigantes que ha captado la atención de los investigadores es el llamado "grokking". Este término, popularizado inicialmente en comunidades técnicas, describe un proceso curiosamente retardado en el cual una red neuronal, después de memorizar los datos de entrenamiento y mostrar una generalización pobre, eventualmente alcanza una generalización casi perfecta tras un período prolongado de entrenamiento. A pesar de su espectacularidad, este fenómeno plantea desafíos importantes en términos de predictibilidad y eficiencia del entrenamiento. La demora en la generalización es un obstáculo para el desarrollo de modelos más rápidos y confiables, especialmente en aplicaciones donde el tiempo y los recursos de cómputo son limitados. Recientemente, investigadores han presentado una solución innovadora que busca acelerar el grokking, denominada GrokTransfer.
La clave de este método reside en la transferencia de embeddings, las representaciones internas que una red neuronal crea para interpretar los datos de entrada. Antes de profundizar en GrokTransfer, es fundamental entender qué es un embedding y por qué juega un papel crucial en la capacidad de las redes neuronales para generalizar. Los embeddings son representaciones vectoriales que transforman datos, como palabras, imágenes o señales, en formatos ordenados que las redes pueden procesar eficazmente. Estos vectores codifican las características esenciales y las relaciones implícitas dentro del conjunto de datos, permitiendo que la red distinga patrones y tome decisiones informadas durante el entrenamiento. En contextos complejos, como el procesamiento del lenguaje natural o la visión por computadora, la calidad y estructura de estos embeddings determinan en gran medida el éxito del modelo.
El fenómeno de grokking generalmente ocurre porque la red necesitará ajustar sus embeddings cuidadosamente para permitir una generalización adecuada. Sin embargo, este ajuste puede tomar un tiempo considerable, durante el cual la red simplemente memoriza sin aprender principios subyacentes que expliquen los datos. GrokTransfer aborda este retraso al aprovechar embeddings ya preentrenados en un modelo más pequeño y menos complejo, que aunque no sea óptimo en desempeño, sí posee una representación útil y no trivial del problema. Este procedimiento consiste inicialmente en entrenar un modelo secundario más simple que alcance un rendimiento decente en la tarea dada, sin esperar alcanzar la perfección. A continuación, se extraen los embeddings aprendidos por este modelo, que constan de las representaciones internas de los datos.
Finalmente, estos embeddings preentrenados se utilizan para inicializar la capa de embedding del modelo principal, que es más grande y complejo. Con esta técnica, el modelo principal parte de una base informada y significativa, evitando el período inicial de aprendizaje lento y memorístico que caracteriza al grokking tradicional. La efectividad de GrokTransfer ha sido demostrada tanto teóricamente como empíricamente. En tareas sintéticas como el clásico problema XOR, donde la generalización retardada se presenta consistentemente, este método permite que el modelo mejor generalice de forma inmediata, eliminando la demora que habitualmente ocurre en el entrenamiento estándar. Esta validación matemática aporta confianza en su aplicabilidad y robustez.
Además, en experimentos con diferentes arquitecturas, desde redes neuronales totalmente conectadas hasta transformadores modernos, GrokTransfer ha reconfigurado la dinámica del entrenamiento para que el modelo produzca mejores resultados en menos tiempo, sin perder precisión ni capacidad de generalización. Esto es especialmente relevante en la era actual, donde la escalabilidad y el rendimiento de los sistemas de aprendizaje automático son esenciales para la investigación científica y aplicaciones industriales. El impacto potencial de acelerar el grokking es significativo. Por un lado, permite ahorrar recursos computacionales, ya que los modelos no necesitan pasar por largas fases de entrenamiento para alcanzar su potencial máximo. Esto puede traducirse en ahorro energético y reducción de costos en centros de datos y servidores.
Por otro lado, abre la puerta a implementaciones más rápidas y ágiles en sistemas en producción, donde la adaptabilidad y la rapidez de aprendizaje son vitales. Otra ventaja importante es la posibilidad de transferir conocimientos entre modelos. La reutilización de embeddings de modelos más pequeños al inicio del entrenamiento de modelos mayores puede considerarse una forma de transferencia de aprendizaje que aprovecha representaciones ya estructuradas, contribuyendo a una evolución más natural y eficiente de las capacidades de la inteligencia artificial. Este proceso se alinea con tendencias actuales en la investigación que buscan optimizar el uso de datos y modelos preexistentes para acelerar la innovación. A pesar del éxito demostrado, queda un camino por recorrer para explorar el alcance total de GrokTransfer en escenarios más heterogéneos y complejos.
Investigaciones futuras podrían investigar cómo esta técnica se aplica en conjuntos de datos con mayor ruido o estructuras irregulares, así como su integración con otros métodos de optimización y regularización. También resulta útil analizar su comportamiento en modelos multimodales, que procesan diferentes tipos de datos simultáneamente, como texto, imágenes y audio. Finalmente, GrokTransfer representa un paso importante hacia la comprensión y perfeccionamiento del grokking, un fenómeno que, aunque fascinante, había significado hasta ahora un cuello de botella en la eficiencia del aprendizaje profundo. Incorporar esta técnica puede ser un catalizador para el desarrollo de modelos más rápidos y confiables que aprendan de manera más humanamente intuitiva, reduciendo la brecha entre la memorización superficial y el verdadero entendimiento del material presentado. En conclusión, la transferencia de embeddings para acelerar el grokking emerge como una herramienta poderosa en el campo del aprendizaje automático.
Esta técnica mejora la curva de aprendizaje, optimiza recursos y fortalece la capacidad de generalización de los modelos, aspectos cruciales para la evolución de la inteligencia artificial. Adoptar estas innovaciones es fundamental para mantener la vanguardia en investigación y desarrollo, impactando positivamente en aplicaciones científicas, industriales y cotidianas que dependen cada vez más de sistemas inteligentes efectivos.