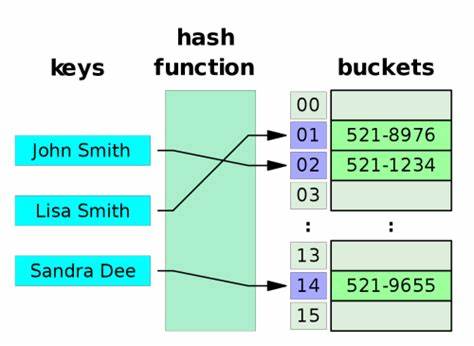
PostgreSQL se ha consolidado como una de las bases de datos relacionales más robustas y flexibles del mercado. Su capacidad para gestionar grandes volúmenes de datos a través de técnicas como el particionamiento la convierte en una solución ideal para aplicaciones de alto rendimiento y escalabilidad. El particionamiento permite dividir tablas enormes en segmentos más manejables, mejorando la velocidad y eficiencia de las consultas. Sin embargo, determinar a cuál partición pertenece un registro específico puede ser un desafío, especialmente cuando se manejan millones de filas y se requieren consultas rápidas y eficientes. En este contexto, surge la gema pg_hash_func para Ruby, una herramienta que replica la lógica interna de PostgreSQL para calcular el índice de partición basada en el hash estándar directamente desde Ruby, sin la necesidad de consultar a la base de datos.
Esta capacidad resulta esencial para optimizar aplicaciones que dependen del particionamiento hash de columnas con datos enteros, como identificadores de usuario o claves foráneas. La esencia de la gema radica en su implementación exacta de las funciones de hash interno de PostgreSQL: hashint8extended para enteros grandes (bigint) y hashint4extended para enteros normales y pequeños (integer y smallint). Estas funciones determinan de manera consistente el índice de partición para un valor dado y un número fijo de particiones, reproduciendo el algoritmo nativo del motor de la base de datos. Al utilizar pg_hash_func, los desarrolladores Ruby pueden calcular directamente, en su propio entorno de aplicación, la partición de destino sin tener que realizar una consulta SQL tipo SELECT para conocer la ubicación de un dato en las tablas particionadas. Esto reduce significativamente la latencia y la carga del servidor de base de datos, especialmente en sistemas distribuidos o aplicaciones con tráfico intensivo.
La gema está diseñada para funcionar principalmente con claves enteras. Este es un enfoque lógico porque el particionamiento hash en PostgreSQL se suele implementar sobre columnas con valores numéricos para maximizar la eficiencia y uniformidad de la distribución. Cabe destacar que pg_hash_func no admite tipos de datos como texto, fechas o números flotantes, ni otros métodos de particionamiento como particionamiento por lista o rango. La compatibilidad de pg_hash_func abarca Ruby 3.0 en adelante y versiones de PostgreSQL desde la 11 hasta la 16, lo que la hace ideal para proyectos que buscan adoptar tecnologías modernas sin renunciar a funcionalidades probadas y estables.
Su instalación es sencilla: basta con agregar la gema en el archivo Gemfile del proyecto Ruby y ejecutar bundle install. Alternativamente, puede instalarse mediante gem install pg_hash_func. Una vez incorporada, la gema ofrece métodos claros y específicos para calcular el índice de partición. Por ejemplo, para un identificador de usuario representado como bigint, se utiliza el método calculate_partition_index_bigint, mientras que para valores integer o smallint se emplea calculate_partition_index_int4. El procedimiento de uso es intuitivo.
Se suministra el valor de la clave y el número total de particiones, y la función devuelve el índice correspondiente. Posteriormente, puede construirse el nombre de la tabla particionada concatenando el prefijo del nombre base con el índice calculado, tal como lo hace PostgreSQL internamente. Más allá del uso básico, la gema permite escenarios avanzados como el particionamiento multinivel, donde diferentes columnas con distintos tipos de enteros pueden determinar distintos niveles de partición. Por ejemplo, una primera partición basada en un bigint que representa el ID del cliente y una segunda partición interna basada en un integer para tipos de configuraciones. Esto facilita la creación de estructuras de datos sumamente segmentadas y optimizadas para consultas específicas.
Además, pg_hash_func expone el resultado bruto de las funciones hash internas de PostgreSQL, lo que resulta valioso para depuración, análisis de distribución de datos y ajuste de esquemas. Comprender cómo se distribuyen hashcode los valores enteros ayuda a evitar desbalances en las particiones que pueden afectar negativamente el rendimiento. El desarrollo activo y abierto de la gema en GitHub permite que la comunidad contribuya a su mejora y adaptación a nuevas versiones o necesidades específicas. También ofrece scripts para instalación, pruebas y liberación de versiones, lo cual facilita su integración en flujos de trabajo profesionales. Por otro lado, la eficiencia que aporta este enfoque es notable.
Al no depender de consultas a la base de datos para identificar el destino de un dato, se minimizan comunicaciones sobre la red, se reduce la latencia y se optimiza el procesamiento en aplicaciones distribuidas y microservicios, donde cada milisegundo cuenta. Para equipos de desarrollo que trabajan con sistemas basados en PostgreSQL y Ruby, pg_hash_func representa una herramienta invaluable para acelerar la lógica de particionamiento y mantener la coherencia con los algoritmos nativos de la base de datos. Eso se traduce en implementaciones más limpias, mantenibles y con menores puntos de fallo. En resumen, pg_hash_func es una gema compacta, especializada y poderosa que responde a una necesidad muy concreta y crítica en el manejo eficiente de datos particionados en PostgreSQL. Su enfoque basado en la réplica exacta del hash interno, sumado a su fácil integración en aplicaciones Ruby modernas, la convierten en un recurso imprescindible para desarrolladores que busquen maximizar el rendimiento y la escalabilidad de sus sistemas.
El futuro de la gestión de datos seguirá exigiendo herramientas que optimicen la interacción entre las aplicaciones y las bases de datos. La capacidad de calcular índices de partición sin interrumpir el flujo con consultas adicionales es un paso adelante hacia sistemas más reactivos, inteligentes y coordinados. En un mundo donde el análisis en tiempo real y la alta disponibilidad son fundamentales, contar con soluciones como pg_hash_func será sin duda una ventaja competitiva para empresas y proyectos tecnológicos que se apoyen en PostgreSQL como núcleo de datos.