La captura de datos de cambio (CDC, por sus siglas en inglés) se ha convertido en un elemento fundamental para las empresas que buscan manejar grandes volúmenes de datos en tiempo real y mantener sus sistemas actualizados y sincronizados con las fuentes de datos originales. Esta tecnología posibilita la replicación eficiente de datos, la integración de sistemas y el análisis en tiempo real, todo sin cargar innecesariamente las bases de datos fuente. Sin embargo, no todas las herramientas de CDC ofrecen la misma experiencia o resultados, y los retos técnicos pueden variar según las necesidades y la infraestructura de cada organización. PhysicsWallah, una plataforma educativa enfocada en la India que ha crecido exponencialmente en los últimos años, recientemente compartió detalles sobre su transición desde Debezium hacia olake.io para su pipeline de CDC.
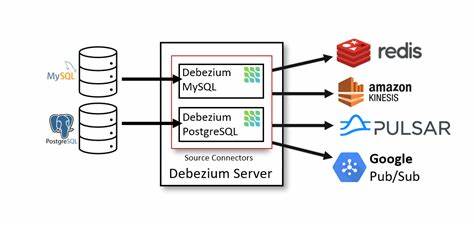
Esta transformación no solo refleja un cambio tecnológico, sino también una evolución en la manera en que el equipo de ingeniería de datos aborda los desafíos asociados con la replicación y sincronización de información crítica. Debezium, basado en Apache Kafka, es una herramienta ampliamente utilizada para CDC. Permite monitorizar bases de datos como MongoDB, MySQL, PostgreSQL, entre otros, y transmitir cambios a través de Kafka hacia distintos destinos. Sin embargo, a medida que los volúmenes de datos y las complejidades aumentan, algunos usuarios pueden enfrentarse a límites prácticos en términos de escalabilidad, flexibilidad e infraestructura requerida. Para entender mejor la decisión de PhysicsWallah, es importante profundizar en las razones principales que motivaron la búsqueda de una alternativa más eficiente.
Uno de los desafíos más relevantes apuntados fue el largo tiempo requerido para las cargas completas (full loads) de colecciones de MongoDB con millones de filas. Este procedimiento inicial es obligatorio para preparar la base de datos que será monitoreada en modo CDC continuo. En entornos con datos voluminosos, las cargas completas son intensivas y vulnerables a fallos: una interrupción implica reiniciar el proceso desde cero y la pérdida del progreso previo, aumentando los costos operativos y la latencia de los datos. Además, la infraestructura basada en Kafka y Kafka Connect se percibió como pesada, especialmente cuando el destino final deseado era almacenar los datos en formatos columnar eficientes como Parquet dentro de tablas Apache Iceberg sobre S3. Esta arquitectura implicaba pasos intermedios donde los datos eran transmitidos, transformados y finalmente almacenados, generando más puntos de fallo, mayor complejidad administrativa y aumento en costos relacionados con la operación de brokers y conectores.
La heterogeneidad de los datos en MongoDB también representaba un reto particular. MongoDB, siendo una base de datos NoSQL orientada a documentos, maneja estructuras complejas y arrays anidados que requieren transformaciones específicas. Debezium, aunque poderosa, demandaba elaboradas transformaciones SMT (Single Message Transforms) para adecuar estos elementos heterogéneos al esquema destino, lo que aumentaba la carga de desarrollo y mantenimiento. Otro inconveniente fue la limitación de Debezium para operar solamente en modo streaming continuo. En ciertos casos, el pipeline necesitaba integrar cargas por lote ad-hoc para algunos flujos de trabajo, lo cual presentaba dificultades adicionales para sincronizarse correctamente y generar una visión coherente y actualizada del estado de los datos.
Por último, el factor del schema drift o evolución continua de esquema supuso otro punto crítico. MongoDB es muy flexible estructuralmente, lo que implica que campos nuevos o cambios en la estructura de documentos pueden surgir con frecuencia. En Debezium, requería trabajo adicional y código personalizado para mantener las tablas Iceberg alineadas con estos cambios de esquema, dificultando la escalabilidad y la estabilidad del sistema. Ante estos retos, PhysicsWallah decidió adoptar olake.io, una solución más ajustada a sus necesidades específicas.
olake.io ofrece un pipeline directo desde MongoDB a Apache Iceberg, eliminando la necesidad de brokers de mensajes como Kafka. Esta simplificación de la arquitectura representa una ventaja significativa, ya que reduce los componentes en operación, facilita la gestión y disminuye la latencia global del pipeline. La herramienta de olake.io está diseñada para operar en dos modos complementarios: una carga completa inicial, seguida por la captura incremental de cambios (CDC).
Lo destacado es que ambas operaciones se controlan mediante una única bandera en la configuración del trabajo, simplificando el despliegue y gestión de tareas. Una característica diferenciadora es la capacidad de realizar cargas completas en fragmentos o chunks, lo que permite que si un pod o tarea falla, el proceso puede continuar desde el último punto registrado en lugar de reiniciarse completamente. Esta capacidad de reanudar cargas reduce considerablemente el tiempo de inactividad y los recursos desperdiciados en reprocesos. La evolución automática del esquema es otro punto fuerte de olake.io.
Nuevos campos en MongoDB aparecen automáticamente como columnas nullable en las tablas Iceberg. Los sub-documentos complejos se almacenan como cadenas JSON, ofreciendo flexibilidad para análisis posteriores sin la necesidad de interrupciones o cambios manuales complejos en los esquemas. Además, olake.io puede ejecutarse como un CronJob en Kubernetes o como una tarea en Airflow, utilizando un único archivo de configuración en YAML o JSON. Esto lo adapta perfectamente a las plataformas de orquestación modernas que PhysicsWallah ya emplea, reduciendo la curva de aprendizaje y la complejidad operacional.
El stack completo de PhysicsWallah después de este cambio está compuesto por MongoDB a través del escritor de olake.io, la persistencia en tablas Apache Iceberg sobre Amazon S3, procesamiento con Apache Spark y consultas mediante Trino o, en ocasiones específicas, Redshift. Todo ello orquestado y coordinado mediante Airflow y Kubernetes, garantizando un sistema escalable, flexible y de alta disponibilidad. Este cambio y su experiencia están alineados con una tendencia creciente en la industria donde las organizaciones buscan pipelines de datos optimizados que reduzcan dependencias, mejoren la resiliencia y aprovechen almacenamiento barato en la nube mediante formatos como Iceberg. Evitar pasar por sistemas intermediarios de streaming cuando se apunta a almacenamiento analítico puede significar una reducción considerable en la complejidad y costos manteniendo la calidad y frescura de los datos.
Que una empresa como PhysicsWallah, con necesidades reales y significativas de manejo de datos en grandes volúmenes, opte por esta transición tecnológica es una señal clara del estado actual del procesamiento de datos. Estos casos aportan información valiosa para ingenieros de datos, arquitectos de soluciones y responsables de tecnología que evalúan opciones para sus pipelines de CDC y almacenamiento. El debate sobre mantener o abandonar Kafka en pipelines CDC es recurrente. Kafka sigue siendo una tecnología robusta y preferida para casos con múltiples consumidores, necesidades de almacenamiento temporal o integración con aplicaciones de streaming complejas. Sin embargo, para escenarios enfocados principalmente en almacenamiento y análisis, con cargas predecibles y arquitecturas modernas en la nube, soluciones como olake.
io están ganando tracción por su simplicidad y características enfocadas. Además, olake.io está disponible como proyecto open source, lo que invita a la comunidad a contribuir y adaptar la herramienta para diferentes ecosistemas y casos de uso. Esta apertura es importante para la evolución continua y la adopción en distintas industrias. En conclusión, la experiencia de PhysicsWallah al migrar su pipeline CDC de Debezium a olake.
io representa un hito en la búsqueda de ventajas operacionales y tecnológicas en la captura y sincronización de datos. Simplificación arquitectural, mejores tiempos de carga, manejo automático de esquemas y adaptación a herramientas modernas de orquestación son factores decisivos que pueden motivar a otras empresas a evaluar caminos similares. En un mundo donde los datos aumentan sin cesar y las organizaciones compiten por decisiones más rápidas y fundamentadas, elegir correctamente las herramientas para construir y mantener pipelines de datos es clave. La historia de PhysicsWallah muestra que, a veces, repensar y simplificar la arquitectura es la mejor estrategia para acelerar la innovación y mantener la competitividad.