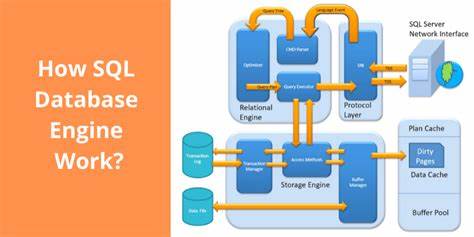
Los motores SQL son el componente central en la arquitectura de las bases de datos relacionales, actuando como la capa lógica que conecta al cliente con el almacenamiento físico de datos. Su función principal es interpretar y ejecutar consultas SQL, un lenguaje estándar para manejar y manipular bases de datos. Comprender su anatomía es esencial para profesionales en tecnologías de la información que buscan optimizar rendimiento, diagnosticar errores o simplemente adquirir una visión integral del procesamiento de datos. El viaje de una consulta SQL dentro del motor puede desglosarse en diversas fases que trabajan de manera coordinada para garantizar que la petición se transforme en resultados válidos y optimizados. La primera etapa y probablemente la más crucial es el análisis o parsing.
Cuando un motor SQL recibe una consulta, esta se presenta como una secuencia de bytes que el sistema debe interpretar. El parser convierte esta secuencia en una estructura llamada árbol de sintaxis abstracta o AST, una representación jerárquica que describe la sintaxis y componentes de la consulta de manera lógica. El parser puede ser implementado utilizando estrategias tales como análisis recursivo izquierdo o derecho, cada una con sus ventajas; por ejemplo, la recursión izquierda puede ser más eficiente en términos de uso de memoria, aunque puede ser más compleja de implementar. Una vez que la consulta está correctamente parseada y estructurada, el siguiente paso es el binding. Durante esta fase, el motor busca enlazar o asociar los identificadores presentes en la consulta, como los nombres de tablas, columnas y alias, con las entidades reales almacenadas en el catálogo de la base de datos.
Este es el momento en el que se valida que las referencias sean válidas, que no existan ambigüedades y que se respeten las reglas de scoping o ámbito. Por ejemplo, si una columna está referenciada sin especificar la tabla a la que pertenece, y existen múltiples tablas con columnas homónimas, la fase de binding detectará el conflicto y generará un error para evitar resultados imprecisos. Luego, la consulta pasa por un proceso de simplificación del plan. La complejidad de SQL permite múltiples formas de expresar la misma consulta lógica, por lo que el motor debe normalizar o unificar estas variaciones en una forma canónica que facilite el análisis posterior y la ejecución eficiente. Este proceso puede incluir optimizaciones comunes como el filtrado de columnas no utilizadas (column pruning) o el movimiento de filtros hacia etapas tempranas del plan de ejecución (filter pushing), lo que reduce el volumen de datos procesados en etapas siguientes.
La exploración del plan es una de las fases técnicas más sofisticadas en la operación de un motor SQL. Esta consiste en evaluar diferentes formas de ejecutar una consulta, especialmente en lo concerniente al orden en el que se realizan las uniones (joins) entre tablas y qué métodos de unión física se utilizan, tales como hash join, merge join o nested loop join. La elección óptima depende de múltiples factores, incluyendo estadísticas de datos, índices disponibles, y características específicas de la consulta. Algunos motores emplean algoritmos de programación dinámica para evaluar todas las permutaciones posibles de joins, mientras que otros utilizan estrategias de backtracking para ir descartando planes menos favorables de forma temprana. Para contabilizar y comparar efectivamente diferentes planes, el motor SQL utiliza un componente llamado coster o estimador de costos.
Este modelo analiza métricas como la cardinalidad estimada de resultados intermedios, el tamaño de tablas y la complejidad de operadores para asignar un «costo» aproximado a cada posible plan. La minimización de este costo ayuda a seleccionar la estrategia de ejecución más rápida y económica en términos de recursos. Una vez seleccionado el plan óptimo, el motor lleva a cabo la fase de ejecución. Aquí, el plan se materializa en una serie de operadores que procesan los datos, ya sea recuperándolos del almacenamiento, aplicando filtros, uniones, agregaciones o cualquier transformación requerida. La ejecución puede ser row-based, procesando fila a fila, o vector-based, trabajando con bloques de datos, técnica que suele mejorar la eficiencia en operaciones masivas.
En sistemas distribuidos, la ejecución puede estar paralelizada, pero en motores como Dolt, por ejemplo, predomina la ejecución local basada en filas. Después de que los datos han sido procesados y el plan ha generado resultados, la última etapa es el spooling o el volcado de resultados. Este proceso consiste en convertir las filas generadas en un formato adecuado para ser transmitido al cliente, lo cual puede incluir la transformación de datos internos a formatos compatibles con protocolos de red, como el protocolo MySQL wire format, donde incluso tipos numéricos son representados como cadenas de texto. El sistema también implementa mecanismos para optimizar la memoria y el flujo de datos, empleando buffers y procesos de batching para minimizar el consumo de recursos y mejorar la latencia de respuesta. Uno de los retos permanentes en la evolución de los motores SQL es la gestión eficiente de la memoria y el rendimiento, especialmente en contextos con alta concurrencia y datos de gran volumen.