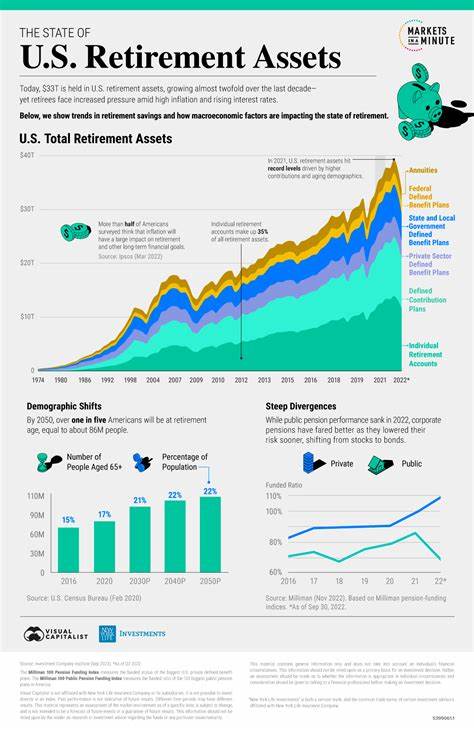
El lenguaje de programación D ha ganado popularidad por su potente manejo de arrays y su capacidad para combinar eficiencia con facilidad de uso. En particular, el soporte para matrices multidimensionales ofrece a los desarrolladores flexibilidad y rendimiento en aplicaciones numéricas, científicas y de ingeniería. Comprender cómo trabajar con estos arrays en D es crucial para aprovechar al máximo las características del lenguaje y escribir código optimizado que se ajusta a diferentes necesidades. En este análisis profundo, abordaremos desde los fundamentos de los arrays en D hasta técnicas avanzadas con librerías especializadas como Mir, cubriendo aspectos esenciales de creación, manipulación e impresión de matrices multidimensionales. Los arrays en D pueden clasificarse en tres categorías principales: arrays normales, arrays estáticos y arrays dinámicos.
Los arrays normales representan una colección general de elementos almacenados consecutivamente en memoria. Los arrays estáticos tienen un tamaño fijo establecido en tiempo de compilación, lo que permite optimizaciones de memoria y acceso. Por su parte, los arrays dinámicos no tienen una dimensión fija y pueden expandirse o contraerse según las necesidades en tiempo de ejecución. Cada tipo de array en D posee propiedades útiles como length, que representa la cantidad de elementos, y ptr, un puntero hacia el primer elemento, facilitando la gestión y acceso eficiente. La dinámica de los arrays se extiende con el concepto de slices o segmentos, que representan vistas parciales o completas de un array original sin copiar los datos subyacentes.
Por ejemplo, al crear slices se pueden manejar subconjuntos de información con mínima sobrecarga, reutilizando el almacenamiento existente. Estas vistas permiten operaciones sencillas como obtener un fragmento de un array existente, modificar elementos o concatenar nuevos valores. Si bien el funcionamiento detallado de los slices en D es complejo, su comprensión es fundamental para manipular datos multidimensionales de manera eficiente. Para construir matrices multidimensionales en D, el enfoque más directo es utilizar arrays anidados. Por ejemplo, la declaración int[][] representa un array dinámico de arrays dinámicos, lo que también se denomina array irregular o “jagged”.
Aunque este método es muy flexible, la cantidad de elementos puede variar en cada dimensión, lo cual puede ser una ventaja o inconveniente según el caso. Sin embargo, la eficiencia no es óptima porque el array externo simplemente guarda referencias a arrays internos dispersos en la memoria, lo que genera un cierto costo en el acceso a cada elemento. Por otro lado, D permite crear matrices multidimensionales densas a través de arrays estáticos anidados, donde el tamaño es conocido en tiempo de compilación, lo que favorece el rendimiento. Por ejemplo, la expresión int[2][3] define un array de tres filas con dos columnas cada una. Si la primera dimensión es fija, pero la segunda dinámica, se puede utilizar una combinación híbrida como double[2][] para adaptar la estructura a lo que la aplicación requiera.
Esta estrategia mejora la gestión de memoria y puede acelerar operaciones por el almacenamiento contiguo. Aquel que busca crear matrices a partir de valores calculados o un rango automático de números puede aprovechar las funciones del módulo std.range, como iota y chunks. Mediante iota, se genera una secuencia lazily evaluada de números enteros, mientras que chunks permite segmentar un array unidimensional en múltiples arrays de longitud fija, aportando una vista bidimensional sin producir copias adicionales. Esta técnica es muy útil para inicializar matrices de manera eficiente y realizar procesamiento dimensional sin complicaciones.
Aunque D no incluye una propiedad nativa para extraer la forma o dimensiones de un array multidimensional, es posible simular esta funcionalidad mediante templates recursivos. Estos templates recogen la longitud en cada dimensión y, tras alcanzar un valor base, presentan la estructura completa, facilitando la comprensión y manipulación de datos complejos. La técnica funciona bien para arrays correctamente formados y segmentados con chunks, pero es importante verificar la uniformidad en el tamaño de subarrays. Para escenarios donde la eficiencia es crítica, existe la librería Mir, una colección de paquetes de alto rendimiento orientados a cálculos numéricos y científicos en D. Dentro de Mir, el módulo mir.
ndslice proporciona implementaciones avanzadas de multidimensional slices que permiten un acceso aleatorio eficiente además de poseer propiedades como shape (forma), strides y estructura, optimizando la gestión en memoria y rendimiento computacional. A diferencia de los slices estándar de D, los slices de Mir están diseñados para ofrecer máxima velocidad y uso compacto de memoria. Al crear slices con mir.ndslice, es importante entender que convertir un array simple a slice no siempre genera la expectativa inicial; por ejemplo, pasando un array de enteros a slice puede producir una estructura tridimensional inicializada con ceros debido a cómo Mir interpreta las dimensiones. Para evitar esto, se emplea la función as del submódulo mir.
ndslice.topology, que transforma los datos originales a la representación deseada sin alterar el contenido. La construcción de slices con mir.ndslice permite diversas formas, desde inicializar con dimensiones conocidas hasta establecer valores particulares por defecto en toda la matriz. Asimismo, existe la función sliced que facilita la creación rápida de vistas multidimensionales desde iteradores o arrays sin la necesidad de pasos intermedios complejos.
Esto reduce considerablemente la complejidad del código y mejora la legibilidad manteniendo una alta eficiencia. Gracias a la integración completa con otras librerías estándar de D, es posible utilizar funciones como iota junto con sliced o fuse para crear matrices multidimensionales sin pérdida de rendimiento. Por ejemplo, utilizando iota y fuse se puede generar una matriz inicializada con valores incrementales organizados según dimensiones deseadas. Además, al manipular slices con la propiedad field también se puede obtener arrays planos tradicionales, útil para interoperabilidad o procesamiento específico. La impresión de matrices y slices es sencilla utilizando writeln acompañado de bucles foreach, pero para presentaciones más elaboradas y legibles se recomiendan técnicas de impresión especializadas o librerías externas destinadas a formatear datos multidimensionales en consola o archivos.
El manejo de matrices aleatorias es otro escenario frecuente en desarrollo numérico. Combinando funciones de generación de valores aleatorios de std.random con técnicas de generación y segmentación de rangos en std.range, es posible rellenar matrices con números aleatorios de forma eficiente y rápida. Mir aporta mecanismos adicionales para crear slices de números aleatorios con distribuciones uniformes o normales empleando motores de generación avanzados y funciones especializadas, lo cual es una gran ventaja para quienes buscan cálculos estadísticos o simulaciones complejas.
Para modificar valores dentro de un slice o matriz de Mir, existen métodos como each que permiten aplicar funciones in-place sin necesidad de crear copias. También se puede usar map para generar nuevas matrices basadas en transformaciones, aunque map es una operación lazy que requiere forzar la evaluación mediante slice o conversiones específicas. La posibilidad de definir funciones personalizadas para inicializar matrices con ceros u otros valores simplifica la implementación de rutinas matemáticas. Las operaciones matemáticas elementales sobre matrices se presentan en Mir de forma sencilla y eficiente. Métricas comunes como suma, producto, o transformaciones elementales se hacen mediante sobrecarga de operadores y funciones específicas que actúan sobre slices sin recorrer manualmente los elementos.
Este enfoque combina la claridad del código con el máximo rendimiento que ofrece Mir gracias a su implementación lazy y optimizada. Una característica poderosa de Mir es la capacidad de operar sobre dimensiones específicas de una matriz mediante la función byDim, que separa la matriz en subconjuntos dimensionales para aplicar operaciones detalladas como sumas por columnas, comprobaciones de condiciones en filas o clasificación entre filas o columnas. Esto abre el abanico para análisis matriciales, operaciones de agregado y procesamiento avanzado sin necesidad de complicadas iteraciones manuales. La indexación en slices de mir.ndslice es intuitiva y compatible con el estilo D, utilizando índices y rangos con soporte para operadores como $, que indica el final del rango.
En arrays multidimensionales, la indexación se realiza encadenando dimensiones, permitiendo acceder a filas, columnas y elementos individuales con facilidad y seguridad en tiempo de compilación. Esta coherencia facilita la adopción por parte de desarrolladores acostumbrados a la sintaxis clásica de arrays. En resumen, el lenguaje D ofrece múltiples caminos para trabajar con matrices multidimensionales, desde arrays dinámicos irregulares hasta estructuras densas y optimizadas con librerías especializadas como Mir. Aprovechar las herramientas nativas y externas no solo facilita la escritura de código limpió y mantenible, sino que garantiza un rendimiento acorde con las exigencias modernas, indispensable en proyectos científicos, técnicos y de análisis de datos. La flexibilidad para combinar enfoques permite adaptar soluciones a las necesidades específicas, ofreciendo un ecosistema robusto para manejo de arrays complejos.
Aprender y dominar el manejo de matrices multidimensionales en D es una inversión valiosa para programadores interesados en computación numérica eficiente y versátil.