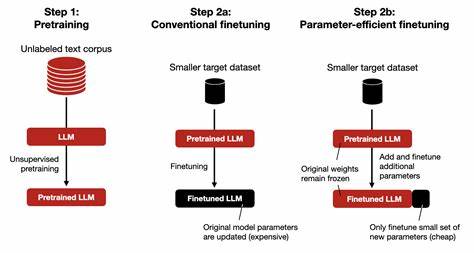
Microsoft Clarity ha revolucionado la manera en que los propietarios de sitios web y aplicaciones comprenden la interacción de sus usuarios con sus contenidos digitales. Al ofrecer de forma gratuita una herramienta que permite descubrir puntos de fricción, analizar dónde los usuarios abandonan y observar patrones de comportamiento, Clarity se posiciona como un recurso fundamental para optimizar la experiencia digital. Sin embargo, la tremenda cantidad de datos que procesa diariamente plantea retos técnicos y operativos considerables, especialmente cuando se trata de escalar para atender millones de proyectos con cientos de billones de eventos y petabytes de información. En esta encrucijada tecnológicamente desafiante, ClickHouse emergió como la solución clave para que Microsoft Clarity mantuviera su promesa de eficiencia, rapidez y costo-efectividad. Antes de la salida pública de Clarity, Microsoft tuvo que lidiar con una versión preliminar de la herramienta que se usaba de manera interna para monitorear algunas webs de Microsoft.
Durante esta etapa, la infraestructura era sustancialmente distinta, ya que se apoyaba en Elastic Search y Spark para soportar los paneles y visualizaciones. Pero esta combinación tenía limitaciones evidentes. El caudal de datos que podían ingerir era bajo, las consultas tardaban mucho tiempo en ofrecer resultados, y procesos como la generación de mapas de calor eran trabajos offline que podían demorar alrededor de media hora. Además, la operación resultaba costosa y la plataforma no podía sostener siquiera una fracción del tráfico que actualmente soporta Clarity. Cuando Microsoft decidió lanzar Clarity como un servicio gratuito al público, se hizo imprescindible rediseñar toda la infraestructura con un enfoque de escalabilidad robusta y eficiente.
El objetivo era enfrentar el desafío de procesar datos a velocidades extremadamente altas, aplicar cálculos complejos y agregaciones para aportar sentido a la información, y proveer insights inmediatos a los usuarios sin sacrificar la granularidad de los detalles. Esto último es fundamental para permitir filtros detallados y exhaustivos, una demanda común en análisis de comportamiento. El proceso de evaluación tecnológica para seleccionar la base de datos central fue riguroso y completo. Recorreron diferentes caminos antes de decidirse por ClickHouse, un sistema diseñado específicamente para escenarios OLAP (procesamiento analítico en línea) que se había probado en plataformas comparables, como Yandex.Metrica.
ClickHouse destacó por su capacidad para manejar altos volúmenes de ingestión de datos gracias a su motor MergeTree, obtener respuestas de consultas en milisegundos a partir de miles de millones de filas y almacenar la información con una compresión particularmente eficiente, lo que disminuye significativamente los costos de almacenamiento. Entre las ventajas más notables que motivaron esta elección están el rendimiento superior tanto en ingestión como en consulta. Comparado con Elastic Search y Spark, ClickHouse logró reducir los tiempos de procesamiento y consumo de recursos, al punto que la generación de mapas de calor pasó de ser un proceso demorado a uno instantáneo y económico. Además, su estructura distribuida tipo master-master permite replicación y escalabilidad horizontal, adaptándose dinámicamente al crecimiento del tráfico. Esta base de datos open source goza de una vibrante comunidad detrás, que no solo asegura ciclos de actualización mensuales sino también soporte activo en plataformas como GitHub y Telegram.
Este respaldo fue fundamental para Microsoft Clarity, que incluso colaboró contribuyendo código al proyecto, evidenciando una integración profunda y confianza en esta tecnología. No obstante, la incorporación de ClickHouse requería asumir una serie de desafíos operativos. Uno de los principales fue la necesidad de auto-gestionar la infraestructura, en contraste con el uso de servicios gestionados de Microsoft Azure a los que el equipo estaba acostumbrado. Mientras que en Azure la creación y administración de una base de datos NoSQL puede hacerse con unos pocos clics, ClickHouse aún no estaba disponible como servicio gestionado en la nube de Microsoft, lo que llevó a desarrollar herramientas propias para la administración, automatización y monitoreo del sistema. Esta complejidad añadió costos operativos y demandó la adquisición y desarrollo de nuevas habilidades dentro del equipo.
La arquitectura que sostiene Clarity y su masivo uso de ClickHouse está compuesta por un enorme clúster con cientos de máquinas organizadas en subclústers o capas. Cada una de estas capas gestiona un subconjunto específico de proyectos, lo que facilita la contención y organización de los datos. Aun cuando funcionan de forma independiente, las capas están interconectadas permitiendo consultas跨proyecto y simplificando su administración. Para reforzar la disponibilidad y confiabilidad, los datos se replican entre centros de datos y la coordinación de la replicación recae sobre un conjunto de nodos ZooKeeper. La esencia del rendimiento descansa en el motor ReplicatedMergeTree, una variante del MergeTree que posibilita tasas de ingestión elevadas y la gestión de grandes volúmenes de datos con replicación.
La selección cuidadosa de las claves primarias y particiones contribuye a mejorar los índices y la compresión. Además, Clarity utiliza vistas materializadas para optimizar ciertas consultas, reestructurando y agregando datos de forma anticipada para acelerar el acceso. Desde la recolección inicial, la plataforma aprovecha SDKs para JavaScript y dispositivos móviles para capturar detalles visuales, como el DOM o la jerarquía de vistas, así como interacciones del usuario como clicks, movimientos de mouse y desplazamientos. Estos datos se envían a gateways backend que dividen la información en dos rutas: los datos visuales y de reproducción van a almacenamiento en blobs, y los datos analíticos se encolan para procesamiento posterior. Un servicio específico se encarga de almacenar datos en grandes bloques agrupados antes de enviarlos a las distintas máquinas del clúster.
Esta estrategia evita pérdidas derivadas de la inestabilidad del sistema, a diferencia del uso nativo de tablas buffer en ClickHouse. En cuanto al consumo, la arquitectura es más sencilla. Todos los paneles, gráficos y mapas de calor que se visualizan en el portal están respaldados por ClickHouse, y son accesados a través de APIs que abstraen la complejidad. Si bien inicialmente se utilizó Chproxy como proxy y balanceador de cargas para ClickHouse, posteriormente se desarrolló un servicio personalizado que adapta la bi-sharding del sistema. También se incorporaron funcionalidades de control de tasa de solicitudes, registro mejorado y otras herramientas de monitoreo.