En el ámbito de la inteligencia artificial y la recuperación de información, uno de los desafíos más recurrentes es el manejo eficaz del contexto en documentos extensos. A medida que aumentan las necesidades de buscar y extraer información precisa en bases de datos, libros, informes o cualquier texto largo, surge la problemática del contexto perdido, que afecta sustancialmente la calidad y la pertinencia de los sistemas de recuperación. Late chunking emerge como una solución innovadora que revoluciona el enfoque tradicional y brinda resultados notoriamente superiores. El problema fundamental al que se enfrentan los sistemas tradicionales de recuperación radica en cómo procesan los documentos antes de su almacenamiento en bases vectoriales. El procedimiento clásico divide primero el texto en fragmentos o "chunks" para luego convertir cada uno de estos en vectores a través de modelos de embeddings.
Sin embargo, esta metodología presenta una falla crítica: al segmentar el documento primero y luego generar los vectores, se pierde la conexión contextual entre fragmentos. Imagine que un usuario consulta sobre la población de Berlín en un sistema que tiene fragmentos individuales del documento. Uno de ellos dice "La ciudad tenía 3,85 millones de habitantes", pero no menciona explícitamente "Berlín". Otro fragmento tiene la mención "Berlín es la capital y la ciudad más grande de Alemania". El sistema falla en unir que "la ciudad" es Berlín, porque los embeddings de cada fragmento fueron generados de forma aislada, ignorando las referencias cruzadas y la dependencia del contexto completo.
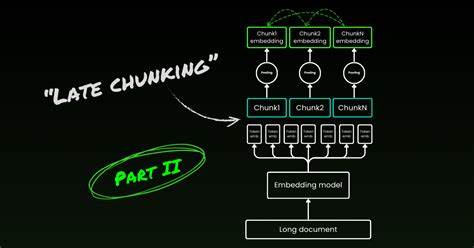
Este fenómeno se conoce como el problema del contexto perdido y representa una limitación estructural en cómo la mayoría de las arquitecturas de recuperación y sistemas RAG (Generación Asistida por Recuperación) funcionan actualmente. Al fragmentar primero, se dividen también las referencias y relaciones semánticas, haciendo que pronombres, sinónimos y menciones indirectas se vuelvan ambiguos y difíciles de representar correctamente en el espacio vectorial. Para abordar esta limitación aparece el concepto de late chunking, que propone una inversión radical del flujo tradicional. En lugar de segmentar el texto y luego generar embeddings de cada fragmento, late chunking consiste en primero procesar y embebir todo el documento completo a nivel de tokens con modelos de embeddings que poseen capacidad para manejar contextos extensos. Posteriormente se realiza la agrupación o chunking sobre estas representaciones ya embebidas.
Este cambio permite que cada segmento derivado contenga internamente el contexto completo del documento y no solo la información local. De esta forma, el modelo puede conservar las relaciones entre términos, referencias y dependencias de largo alcance, mejorando significativamente la coherencia y calidad de la recuperación. Uno de los factores esenciales para el éxito de late chunking es el uso de modelos de embedding diseñados para largas secuencias, capaces de procesar hasta miles de tokens simultáneamente. Estos modelos pueden analizar el documento completo, atendiendo a las interdependencias y estructurando representaciones vectoriales que reflejan tanto el significado local como el global. La implementación práctica de late chunking comienza con la tokenización del documento completo a través de un tokenizer que provea los offsets y permita mapear los tokens a fragmentos de texto exactos.
Estos offsets son fundamentales para segmentar el documento en unidades comprensibles para el usuario, tales como oraciones o párrafos. Luego, se aplican las segmentaciones basadas en puntuaciones o delimitadores naturales del texto, pero sobre el espacio tokenizado. Esto genera posiciones de inicio y fin tanto en caracteres como en tokens. Con estas posiciones, se extraen los embeddings de los tokens correspondientes y mediante técnicas de pooling —como la media geométrica— se produce un vector único para cada fragmento. Este vector cargado de contexto completo se almacena como representación del fragmento, y al momento de realizar una consulta, el sistema compara la pregunta embebida contra estos vectores para identificar el fragmento más relevante con precisión.
Comparado con la técnica tradicional, late chunking ha demostrado mejoras sustanciales en la capacidad de capturar respuestas cuando la información requerida está distribuida a lo largo de múltiples fragmentos. Mientras que el enfoque clásico logra un buen desempeño cuando la información está contenida en un único fragmento, decae fuertemente en consultas cross-chunk, que implican la integración de información dispersa. En experimentos prácticos, se ha evidenciado que late chunking mantiene y hasta mejora el rendimiento para consultas simples, a la vez que incrementa notablemente la tasa de éxito en preguntas complejas que requieren conexión de conceptos a través de varios fragmentos. Esto es un gran avance para aplicaciones de búsqueda documental, sistemas de atención al cliente y asistentes basados en conocimiento. Otra ventaja de late chunking es que reduce la necesidad de crear fragmentos con grandes solapamientos o usar técnicas arbitrarias de segmentación para tratar de preservar contexto.
Como cada token embedding ya incorpora la información global, los límites exactos del chunking pierden importancia, lo que simplifica el proceso y mejora la consistencia. Es imprescindible destacar que la efectividad de late chunking depende crucialmente del tipo de modelo de embeddings empleado. Modelos tradicionales con limitaciones de ventana de contexto o sin entrenamiento orientado a documentos largos no serán efectivos, porque no lograran representar adecuadamente las relaciones largas. Modelos recientes que incorporan mecanismos de atención extendida o arquitecturas especializadas para procesar secuencias de tokens mucho más largas son ideales para esta técnica. Además, algunos han sido entrenados explícitamente con tareas que requieren comprensión global del documento, lo que potencia su capacidad para capturar referencias contextuales.
Adicionalmente, late chunking permite diseñar sistemas más robustos y escalables en términos de almacenamiento y computación, dado que evita el aumento redundante de datos que generan los fragmentos solapados. Se optimiza la cantidad de vectores almacenados, manteniendo o mejorando la calidad de la recuperación. Para integrar late chunking en sistemas existentes, es posible aprovechar librerías y modelos open source que facilitan la tokenización con offsets y el cálculo de embeddings a nivel de token, como las herramientas provistas por Jina AI u otras plataformas especializadas. La transición implica adaptar el flujo a embed-then-chunk y revisar las arquitecturas de almacenamiento y búsqueda. En conclusión, late chunking representa un cambio paradigmático en la forma de procesar y recuperar información en documentos largos.
Su innovación consiste en preservar el contexto completo durante la generación de embeddings y luego segmentar para extraer fragmentos útiles. El resultado es un sistema que entiende mejor las referencias, mantiene coherencia en la recuperación y responde acertadamente a consultas complejas que requieren integrar información dispersa. Este avance potencia enormemente aplicaciones en motores de búsqueda, asistentes conversacionales, análisis documental y cualquier sistema que dependa de una comprensión profunda y precisa de grandes volúmenes de texto. Adoptar late chunking es, sin duda, un paso hacia sistemas de información más inteligentes, eficientes y contextualmente conscientes.