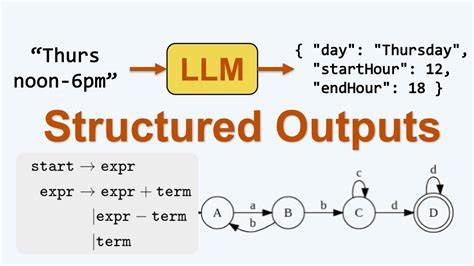
Los modelos de lenguaje grandes, conocidos comúnmente como LLM por sus siglas en inglés, han revolucionado el campo de la inteligencia artificial y el procesamiento del lenguaje natural. Estas poderosas herramientas tienen la capacidad de generar texto coherente y contextualizado en función de las indicaciones que reciben, pero uno de los aspectos más interesantes y desafiantes es cómo producen salidas estructuradas que no solo son comprensibles para humanos, sino también útiles para sistemas automatizados que requieren formatos específicos como JSON o modelos de validación como Pydantic. Entender cómo los LLM logran esta salida estructurada implica adentrarse en el mecanismo de generación de texto y cómo se integra con las restricciones o formatos predefinidos por el usuario o por desarrolladores que buscan que estas respuestas sean compatibles con flujos de trabajo o sistemas externos. Para empezar, es importante conocer que los LLM están entrenados con enormes cantidades de datos textuales y han aprendido a predecir la probabilidad de una palabra o secuencia de palabras dadas las anteriores, lo cual permite generar contenido que sigue patrones lingüísticos naturales. Sin embargo, cuando se trata de salidas estructuradas, el desafío aumenta porque deben respetar formatos que no son simplemente texto libre sino códigos o estructuras específicas que los sistemas consumen.
Una de las técnicas habituales es la utilización de modelos de validación o esquemas como Pydantic. Pydantic es una biblioteca de Python que permite definir modelos de datos con tipos y restricciones, facilitando la validación y serialización de estructuras en JSON. Al integrar Pydantic con un LLM, el enfoque común es formular una solicitud para que la salida del modelo sea compatible con un formato JSON que corresponde al modelo Pydantic deseado. Pero, ¿cómo se asegura que el modelo realmente genere una salida válida y bien estructurada? Existe la opción de simplemente pedir al LLM que produzca una cadena JSON, confiando en su capacidad de imitar el formato correcto por su entrenamiento y contexto. Por ejemplo, se le puede dar un prompt que incluya instrucciones explícitas para responder con un JSON siguiendo una estructura determinada.
En muchos casos, esto suele funcionar, porque los LLM han visto muchos documentos y códigos durante su entrenamiento, y son capaces de generar sintaxis válida. Sin embargo, este método no es infalible y puede conducir a errores de formato o inconsistencias, especialmente en respuestas complejas. Para hacer más robusta y determinista la generación de salidas estructuradas, algunas herramientas y bibliotecas han implementado estrategias adicionales que combinan la generación probabilística del LLM con validaciones y correcciones automáticas. Por ejemplo, la respuesta generada puede ser interpretada y validada automáticamente contra el modelo Pydantic, y si no es válida, se puede regenerar el texto solicitando corrección o proceder a aplicar parsers y correctores automáticos. También, algunas soluciones usan cadenas de herramientas que guían al LLM a producir solo aquellos elementos permitidos, restringiendo y limitando su output en función de un esquema definido.
Además, hay enfoques más técnicos que combinan prompt design avanzado con técnicas de post-procesamiento. El prompt design implica construir la consulta o instrucción al LLM de modo que se incluya un ejemplo claro y detallado del formato deseado, además de instrucciones claras para evitar desviaciones. Esta señalización contextual ayuda a que la generación sea más confiable y estructurada. Por otro lado, la serialización no es simplemente pasar el JSON al LLM como contexto, sino que se trata de un proceso cuidadoso donde el modelo debe entender su tarea como producir un resultado que cumple ciertos requisitos estructurales. El LLM, debido a su naturaleza probabilística, no está “forzado” a producir un objeto JSON válido en el sentido tradicional, pero con la combinación adecuada de prompting, validación y corrección se logra un nivel alto de cumplimiento que satisface las necesidades de los desarrolladores.
Los beneficios de poder obtener salidas estructuradas son inmensos. Permite que aplicaciones como chatbots, asistentes virtuales, sistemas de recomendación, motores de búsqueda o cualquier solución que maneje datos complejos puedan integrar las respuestas del LLM de forma directa y eficiente sin necesidad de un procesamiento adicional pesado. Esto agiliza el desarrollo y mejora la experiencia del usuario. En resumen, la salida estructurada de los LLM se consigue mediante una combinación de generación inteligente basada en contexto, validación mediante modelos como Pydantic y técnicas de diseño de prompts que orientan y limitan la respuesta. Aunque el proceso no es totalmente determinista por naturaleza debido a la arquitectura de los modelos, la integración de herramientas de validación y post-procesamiento garantiza que la información generada cumpla con las especificaciones necesarias para su aplicación en niveles productivos.
El futuro de esta tecnología apunta a mejoras continuas donde los modelos aprendan directamente a respetar esquemas de salida y formatos predefinidos con mayores garantías, reduciendo la necesidad de intervenciones externas. Esto abre un abanico de posibilidades para aplicaciones inteligentes más robustas, confiables y escalables basadas en inteligencia artificial. La colaboración entre técnicas de machine learning, ingeniería de prompts y desarrollo de software es esencial para perfeccionar esta interacción entre humanos, modelos y sistemas automáticos, logrando así sacar el máximo provecho de los avances actuales en modelos de lenguaje grandes.