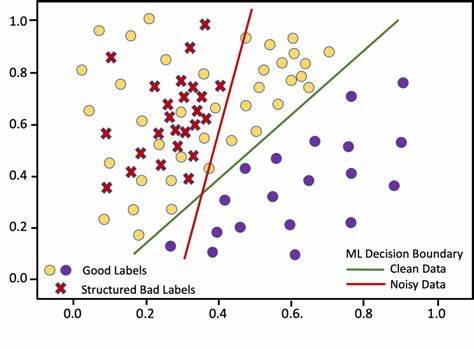
En el campo del aprendizaje automático, la necesidad de contar con grandes conjuntos de datos etiquetados ha sido tradicionalmente un desafío significativo, aludiendo a un proceso costoso, largo y a veces incluso inviable, especialmente en dominios donde la obtención de etiquetas verdaderas requiere expertos o acceso limitado. Para superar estas barreras, la comunidad de la inteligencia artificial ha desarrollado paradigmas innovadores que permiten entrenar modelos sin depender exclusivamente de etiquetas fiables y limpias. La supervisión débil, y en particular el enfoque conocido como “data programming” o programación de datos, abre un nuevo horizonte para el aprendizaje automático, aprovechando heurísticas ruidosas o funciones de etiquetado imperfectas para generar etiquetas suaves y probabilísticas que alimentan el entrenamiento de modelos predictivos. El concepto central detrás de este enfoque consiste en generar etiquetas sintéticas a partir de diferentes fuentes o funciones de etiquetado que, aunque no sean perfectas ni completamente precisas, correlacionan con la verdad subyacente. Estas funciones de etiquetado, conocidas por su naturaleza ruidosa o incompleta, pueden optar por abstenerse en ciertos casos o asignar etiquetas erróneas con alguna frecuencia, pero cuando se combinan e interpretan correctamente, permiten aproximar con alta fidelidad la distribución real de las etiquetas.
Esta aproximación elimina la estricta dependencia en datos etiquetados manualmente y anticipa una forma escalable de ampliar conjuntos de datos para tareas de clasificación, especialmente en problemas binarios. Los primeros trabajos sistemáticos sobre programación de datos se remontan a un artículo emblemático de 2016, donde se estableció una metodología formal basada en máxima verosimilitud para estimar parámetros que describen la precisión y tasa de abstención de cada función de etiquetado. El núcleo del método asume que cada función puede devolver tres posibles valores: 1 para una clase positiva, -1 para una clase negativa, y 0 para abstención cuando la función decide no emitir una etiqueta para un dato específico. Los parámetros por estimar son la probabilidad de que una función de etiquetado abstenga y la tasa a la cual devuelve la etiqueta correcta cuando no se abstiene. Estos parámetros, por definición, son desconocidos al inicio y deben inferirse únicamente a partir de las etiquetas generadas y su relación conjunta.
Para lograr esta estimación, se modela la distribución conjunta entre las funciones de etiquetado y la etiqueta verdadera desconocida, asumiendo independencia condicional entre las funciones (aunque se reconoce que esta es una simplificación). La función de verosimilitud combina la probabilidad a priori uniforme sobre las clases con las contribuciones individuales de las funciones, que incluyen las probabilidades de abstenerse, acertar y errar. Al maximizar esta función de verosimilitud sobre los parámetros que describen las funciones de etiquetado, es posible encontrar las estimaciones que mejor explican los datos observados. Un reto que surge en esta etapa es la no identificabilidad del modelo, manifestada en que existe simetría entre parámetros que puede invertirse sin cambiar la verosimilitud, por lo que se debe incorporar información adicional o restricciones para obtener soluciones interpretables y significativas. Una vez estimados estos parámetros, la metodología permite calcular probabilidades condicionales de que cada instancia de datos pertenezca a una clase dada su vector de etiquetas generadas por las funciones heurísticas.
Estos resultados, denominados “etiquetas suaves” o probabilidades, son empleadas como objetivos de entrenamiento para modelos supervisados tradicionales. En lugar de entrenar con etiquetas categóricas binarias firmes, los modelos aprenden a predecir probabilidades, lo cual refleja la incertidumbre inherente debido al ruido y a la naturaleza no perfecta de las funciones de etiquetado. Este paradigma se ha implementado exitosamente en diversas aplicaciones, y se destaca que no solo permite mantener la calidad predictiva de los modelos, sino que también habilita la rápida generación de grandes conjuntos de entrenamiento sin necesidad de mano de obra humana extensiva. La inclusión de penalidades de regularización, como L2 en modelos lineales, es fundamental para evitar el sobreajuste a las etiquetas suaves ruidosas y controlar la complejidad del modelo resultante. Un ejemplo práctico, basado en un conjunto de datos sobre cáncer de mama, muestra cómo se pueden diseñar funciones heurísticas vinculadas a características clínicas — como grosor cloral, tamaño celular o número mitótico— que abstienen o asignan etiquetas erróneas con diferentes probabilidades.
Al calcular las etiquetas suaves y emplearlas para entrenar un modelo lineal con regularización, se alcanzan niveles de precisión y sensibilidad competitivos que validan la eficacia del enfoque. Esta experiencia evidencia la capacidad del método para transformar conocimientos expertos, codificados como reglas simples, en sistemas predictivos robustos bajo la ausencia de etiquetas verdaderas. Más allá de la clasificación binaria, el enfoque puede ampliarse a escenarios multiclase o incluso regresión, aunque los cálculos de probabilidades se vuelven más complejos y requieren modelados más sofisticados de las distribuciones conjuntas. También, el método puede combinarse con técnicas de aprendizaje semi-supervisado integrando algunas etiquetas verdaderas para mejorar aún más el rendimiento y la estabilidad del proceso de estimación. Las herramientas y librerías que soportan este paradigma, como Snorkel en Python, facilitan su adopción en entornos reales, ofertando un marco sólido para la creación rápida de datasets a partir de fuentes variadas de etiquetado heurístico, incluidas reglas, patrones de texto, bases de conocimiento o modelos previos.