Con el avance acelerado de la inteligencia artificial y, en particular, de los grandes modelos de lenguaje (LLM), la demanda para resolver problemas complejos ha ido en constante crecimiento. Estos modelos, aunque poderosos, enfrentan altos costos de computación y latencia durante la inferencia en tiempo real, lo que limita su aplicabilidad en escenarios donde la rapidez y eficiencia son cruciales. Es en este contexto que surge el concepto innovador de “Sleep-Time Compute”, una técnica que va más allá del escalado tradicional de la inferencia para optimizar el desempeño y reducir la carga computacional exactamente cuando más importa: en el momento de consulta o test-time. Sleep-Time Compute introduce un cambio paradigmático al permitir que los modelos “piensen” o procesen información de manera anticipada y offline, antes de que las preguntas o consultas reales se presenten. Esto significa que, en lugar de depender únicamente del procesamiento en tiempo real para cada nueva consulta, el sistema realiza cálculos y prepara datos útiles con anticipación, basándose en la anticipación de posibles preguntas que los usuarios podrían formular.
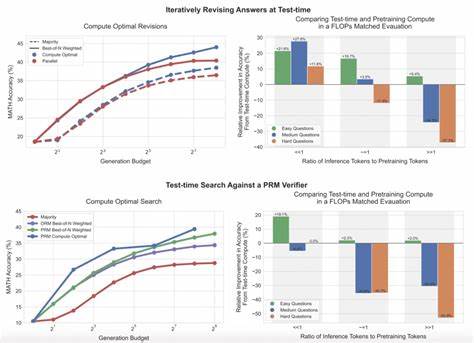
Este enfoque permite disminuir significativamente la cantidad de cómputo requerido durante la inferencia, lo cual se traduce en menor latencia y menor consumo de recursos. Para validar la efectividad de esta novedosa técnica, se emplearon dos tareas de razonamiento basadas en modelos con estado: Stateful GSM-Symbolic y Stateful AIME. Estas tareas implican dificultades razonables que demandan mayor capacidad de procesamiento para alcanzar una alta precisión. Los resultados revelaron que Sleep-Time Compute puede reducir el cómputo necesario durante el test-time en aproximadamente cinco veces, manteniendo el mismo nivel de precisión. Además, al aumentar el cómputo realizado de manera anticipada —el llamado cómputo en estado de "sueño"— se consigue una mejora significativa en la precisión, alcanzando incrementos de hasta 13% en Statefull GSM-Symbolic y un notable 18% en Stateful AIME.
Una extensión interesante de este enfoque se materializó con la introducción de Multi-Query GSM-Symbolic, que incorpora múltiples consultas relacionadas para un mismo contexto. Esta estructura permite amortizar el gasto computacional del cómputo anticipado en varias preguntas vinculadas, reduciendo aún más el costo promedio por consulta en aproximadamente 2.5 veces. Este hallazgo subraya la eficiencia de agrupar consultas relacionadas y maximizar el valor del trabajo realizado en la etapa de preprocesamiento o “sueño”. El éxito de Sleep-Time Compute está estrechamente vinculado con la capacidad de predecir cuál será la consulta del usuario.
Cuando las preguntas son altamente predecibles o se puede anticipar el tipo de información que los usuarios buscarán, el beneficio de esta técnica se multiplica. Esto abre un nuevo campo de investigación para hacer modelos más inteligentes no solo en responder, sino en anticipar demandas futuras. Más allá de las pruebas controladas, Sleep-Time Compute fue aplicado en un estudio de caso real en tareas de ingeniería de software (SWE) con agentes inteligentes. Los resultados mostraron un impacto positivo en la reducción de costos de inferencia y en la mejora de la respuesta y precisión, demostrando su potencial para aplicaciones prácticas fuera del laboratorio. Este avance no solo es relevante para la comunidad académica y científica, sino que tiene profundas implicaciones comerciales y tecnológicas.
La reducción de la latencia y del costo computacional hace que la implementación de modelos grandes sea más asequible y viable para una mayor variedad de industrias y aplicaciones. Empresas que requieren respuestas rápidas y precisas, desde atención al cliente hasta análisis de datos complejos, pueden beneficiarse enormemente de esta técnica. Además, Sleep-Time Compute plantea un paradigma en el desarrollo futuro de sistemas de inteligencia artificial. La capacidad de anticipar y preparar resultados mediante cómputo anticipado invita a replantear los arquitectos de software sobre cómo estructurar modelos y flujos de información para maximizar eficiencia, escalabilidad y precisión. Se trata de un paso importante hacia sistemas más inteligentes y adaptativos, que optimicen el uso de los recursos computacionales sin sacrificar desempeño.
Sin embargo, es importante considerar también las limitaciones y desafíos que la técnica implica. La dependencia en la previsibilidad de las consultas requiere un análisis profundo del comportamiento del usuario y del contexto, lo que puede involucrar complejidades añadidas en el diseño y entrenamiento de modelos. Asimismo, el balance entre el costo del cómputo anticipado y el ahorro durante el test-time debe ser cuidadosamente calibrado para obtener los mejores resultados. La disponibilidad de código y datos asociados a esta investigación impulsa la colaboración e innovación, facilitando que otros investigadores y desarrolladores puedan explorar, adaptar y mejorar Sleep-Time Compute en diferentes áreas y contextos. De cara al futuro, el concepto de Sleep-Time Compute podría integrarse con avances en aprendizaje continuo, modelos adaptativos y sistemas autónomos, creando ecosistemas de IA capaces de aprender, anticipar y responder de manera cada vez más eficiente y contextualmente relevante.
En definitiva, Sleep-Time Compute representa un importante salto en la evolución de la inteligencia artificial, ofreciendo una solución innovadora para superar las limitaciones actuales de inferencia a gran escala. Al permitir que los modelos realicen cálculos anticipados y aprovechen patrones en las consultas, se promueve una IA más eficiente, rápida y accesible para aplicaciones del mundo real, marcando un antes y un después en el manejo de los grandes modelos de lenguaje y sus múltiples aplicaciones.







![An Israeli court has convicted several toxic Wikipedia editors for defamations [pdf]](/images/352BAC90-5DED-4E17-BC3B-8AA92936093C)
